

文章《You Only Look Once: Unified, Real-Time Object Detection》提出方法下面简称YOLO。
目前,基于深度学习算法的一系列目标检测算法大致可以分为两大流派:
1.两步走(two-stage)算法:先产生候选区域然后再进行CNN分类(RCNN系列),
2.一步走(one-stage)算法:直接对输入图像应用算法并输出类别和相应的定位(YOLO系列)
之前的R-CNN系列虽然准确率比较高,但是即使是发展到Faster R-CNN,检测一张图片如下图所示也要7fps(原文为5fps),为了使得检测的工作能够用到实时的场景中,提出了YOLO。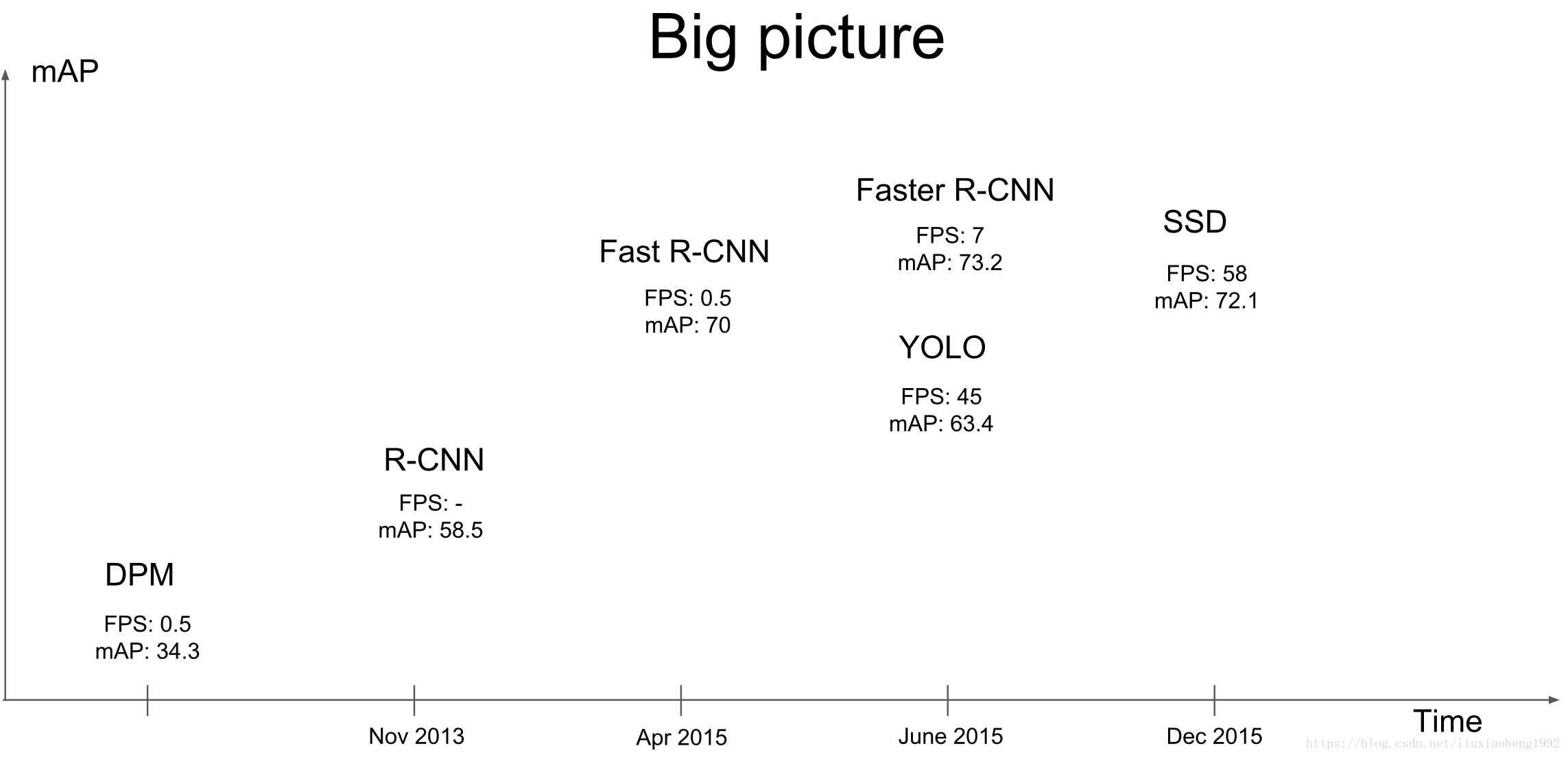
YOLO的检测思想不同于R-CNN系列的思想,它将目标检测作为回归任务来解决。
下面来看看YOLO的整体结构:

由上两图所示,网络是根据GoogLeNet改进的,输入图片为448*448大小,输出为7×7×(2×5+20)
,现在看来这样写输出维度很奇怪,下面来看一下输出是怎么定义的。
将图片分为S×S
个单元格(原文中S=7),之后的输出是以单元格为单位进行的:
1.如果一个object的中心落在某个单元格上,那么这个单元格负责预测这个物体。
2.每个单元格需要预测B个bbox值(bbox值包括坐标和宽高,原文中B=2),同时为每个bbox值预测一个置信度(confidence scores)。也就是每个单元格需要预测B×(4+1)个值。
3.每个单元格需要预测C(物体种类个数,原文C=20,这个与使用的数据库有关)个条件概率值.
所以,最后网络的输出维度为S×S×(B×5+C)
,这里虽然每个单元格负责预测一种物体(这也是这篇文章的问题,当有小物体时可能会有问题),但是每个单元格可以预测多个bbox值(这里可以认为有多个不同形状的bbox,为了更准确的定位出物体,如下图所示)。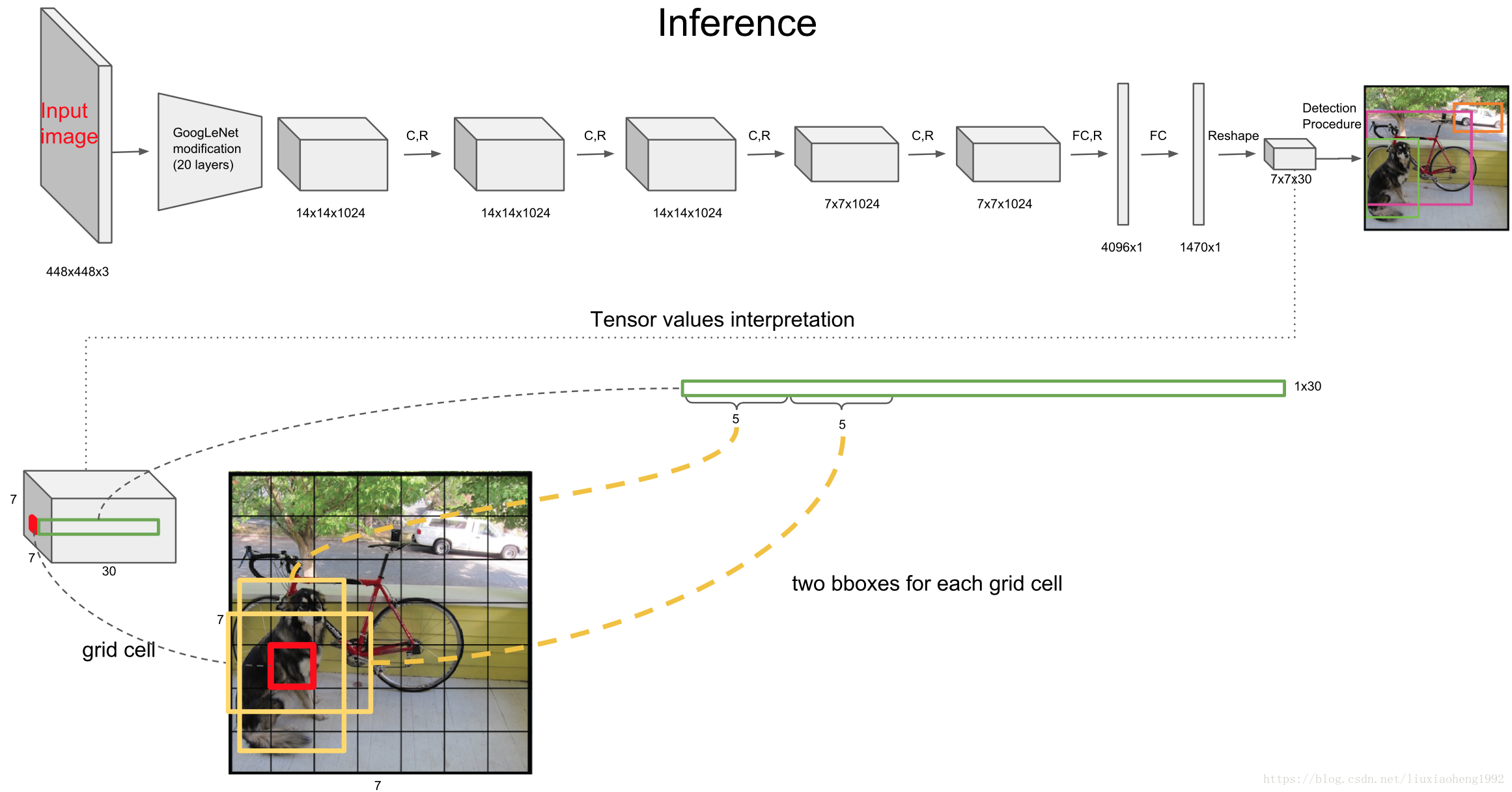
因为这里是当作回归问题来解决的,所以所有的输出包括坐标和宽高最好都定义在0到1之间。网上看见一张比较详细的图如下。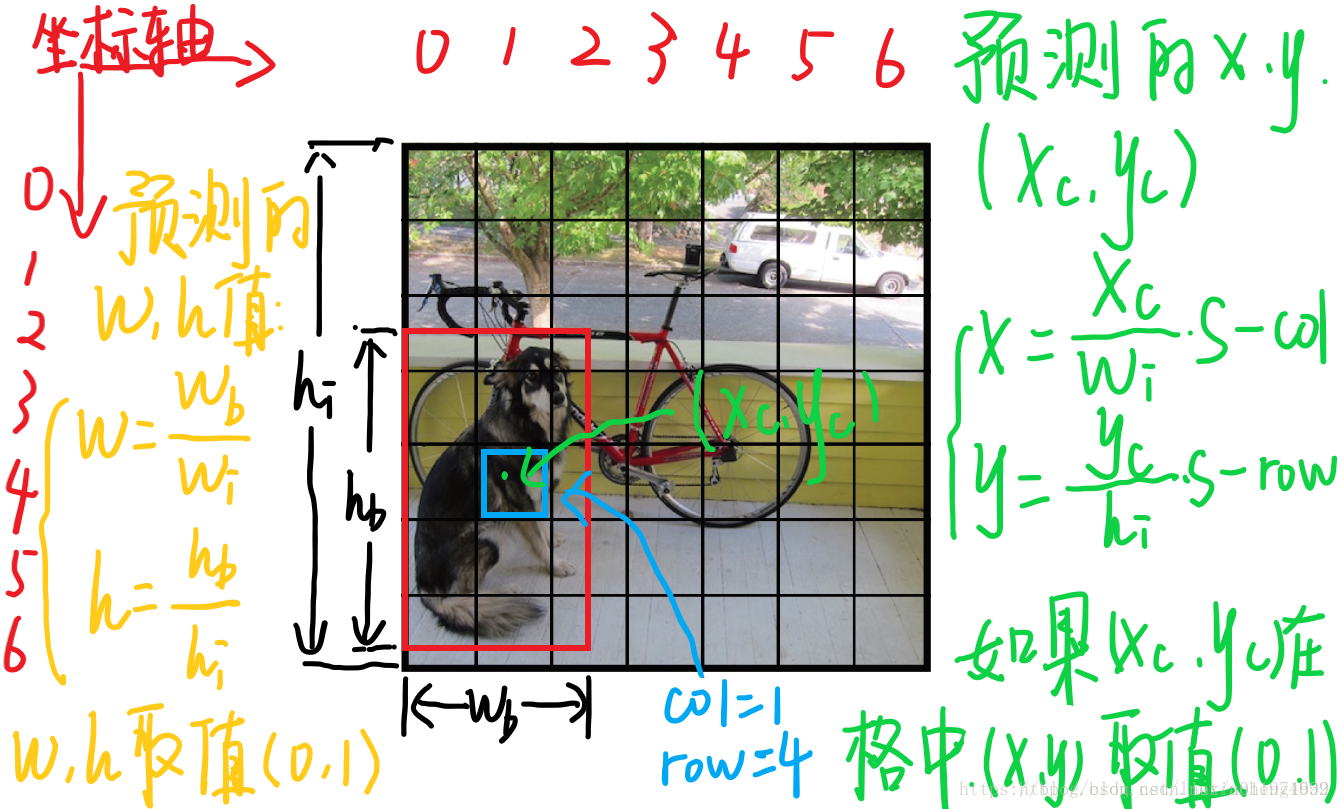
来看一下每个单元格预测的B个(x,y,w,h,confidence)的向量和C的条件概率中,每个参数的含义(假设图片宽为{w_i}高为{hi},将图片分为S×S):
1.(x,y)是bbox的中心相对于单元格的offset
对于下图中蓝色框的那个单元格(坐标为(xcol=1,yrow=4)),假设它预测的输出是红色框的bbox,设bbox的中心坐标为(xc,yc),那么最终预测出来的(x,y)是经过归一化处理的,表示的是中心相对于单元格的offset,计算公式如下:
x=xcwiS−xcol,y=ychiS−yrow
2.(w,h)是bbox相对于整个图片的比例
预测的bbox的宽高为wb,hb
,(w,h)表示的是bbox的是相对于整张图片的占比,计算公式如下:
w=wbwi,h=hbhi
3.confidence
这个置信度是由两部分组成,一是格子内是否有目标,二是bbox的准确度。定义置信度为Pr(Object)∗IOUtruthpred
。
这里,如果格子内有物体,则Pr(Object)=1,此时置信度等于IoU。如果格子内没有物体,则Pr(Object)=0
,此时置信度为0
4.C类的条件概率
条件概率定义为Pr(Classi|Object)
,表示该单元格存在物体且属于第i类的概率。
在测试的时候每个单元格预测最终输出的概率定义为,如下两图所示(两幅图不一样,代表一个框会输出B列概率值)
Pr(Classi|Object)∗Pr(Object)∗IOUtruthpred=Pr(Classi)∗IOUtruthpred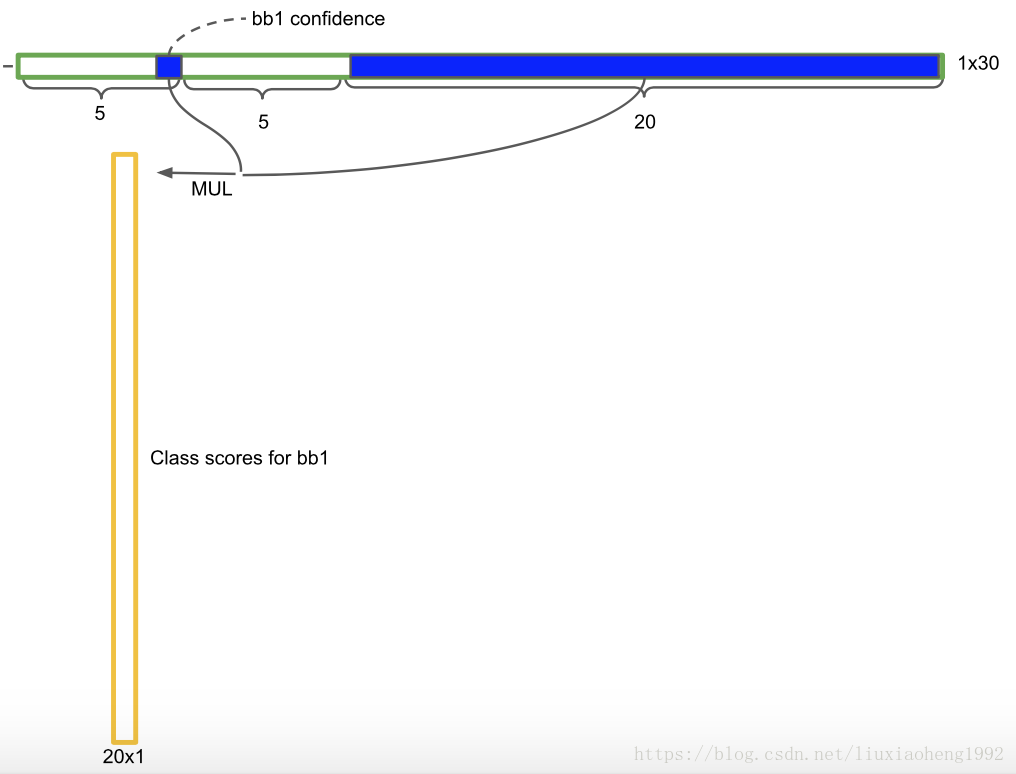
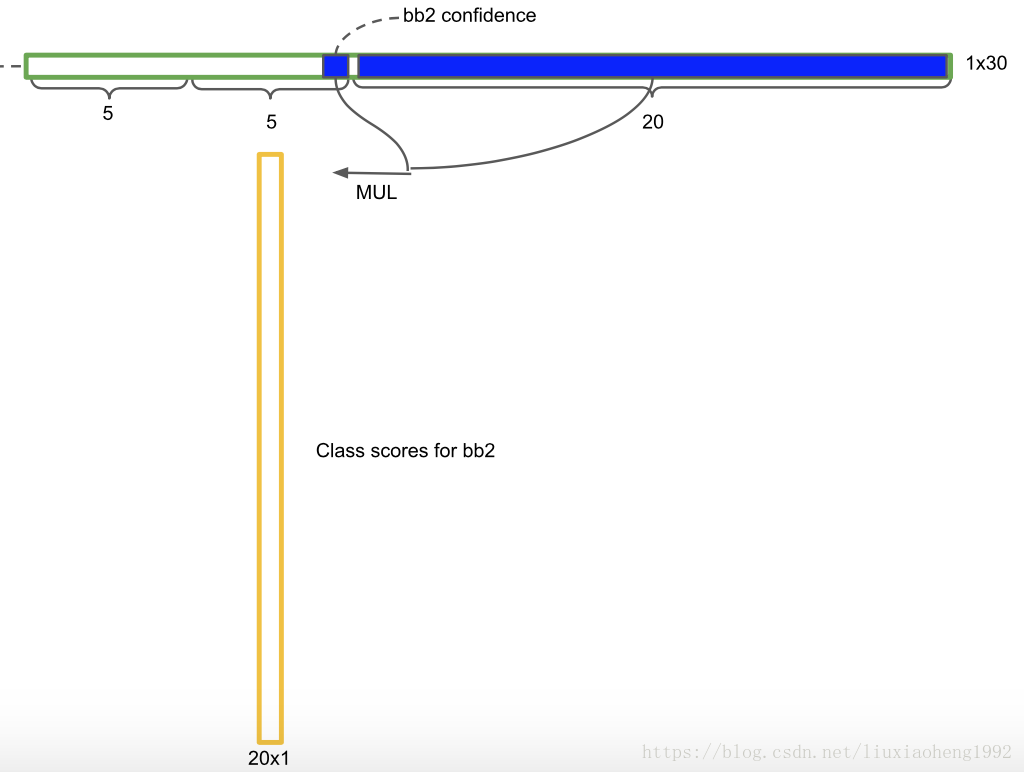
最后将(S×S)×B×20 列的结果送入NMS,最后即可得到最终的输出框结果
最后来看一下训练YOLO使用的损失函数定义(本想自己用latex打的,后来有个符号一直打不出来,使用网友的图如下)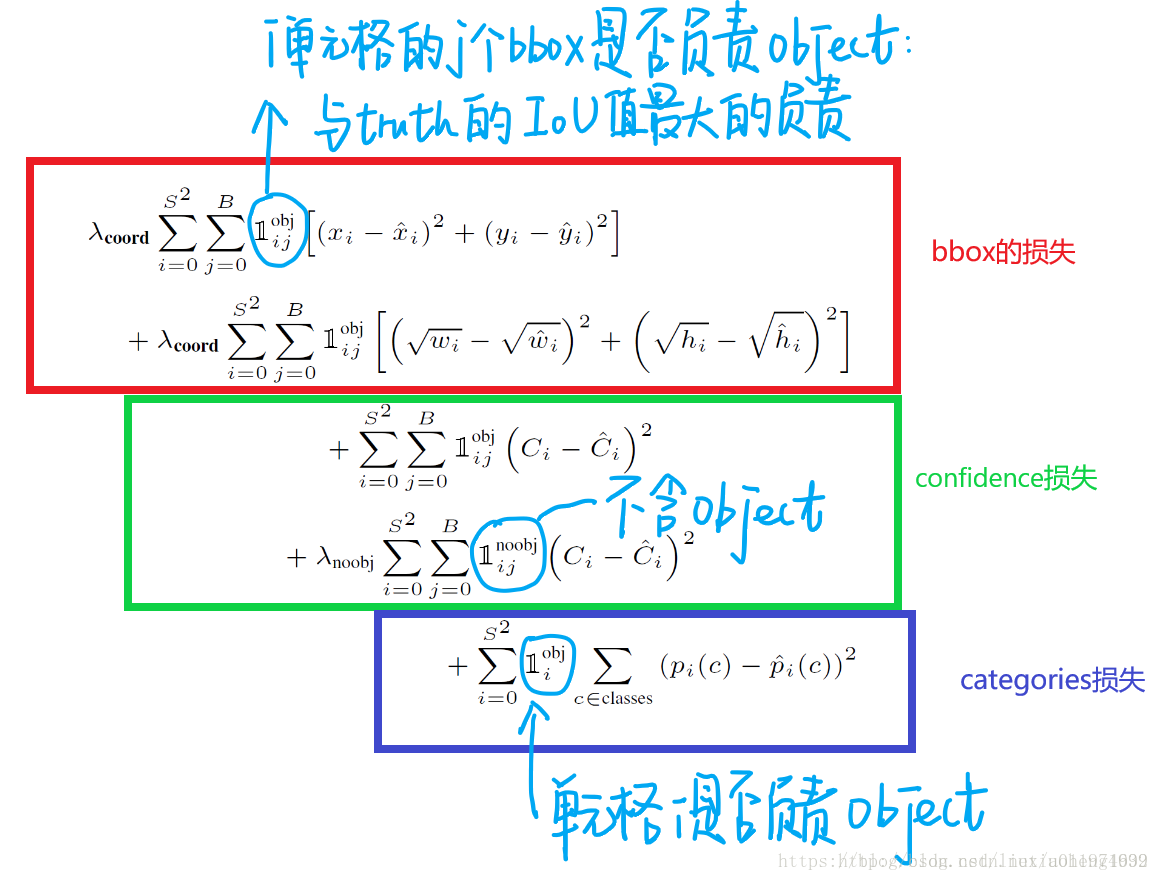
这里强调两点:
1.每个图片的每个单元格不一定都包含object,如果没有object,那么confidence就会变成0,这样在优化模型的时候可能会让梯度跨越太大,模型不稳定跑飞了。为了平衡这一点,在损失函数中,设置两个参数λcorrd
和λnoobj,其中λcorrd控制bbox预测位置的损失,λnoobj控制单个格内没有目标的损失。
2.对于大的物体,小的偏差对于小的物体影响较大,为了减少这个影响,所以对bbox的宽高都开根号。
---------------------
转自:CSDN
作者:Michaelliu_dev
原文:https://blog.csdn.net/liuxiaoheng1992/article/details/81983280
