

转自:https://blog.csdn.net/ghw15221836342/article/details/80084861
https://blog.csdn.net/ghw15221836342/article/details/80084984
Mask RCNN 原理:
简单说一下Mask R-CNN 是一个两阶段的框架,第一个阶段扫描图像并生成提议(proposals,即有可能包含一个目标的区域),第二阶段分类提议并生成边界框和掩码。Mask R-CNN 扩展自 Faster R-CNN,由同一作者在去年提出。Faster R-CNN 是一个流行的目标检测框架,Mask R-CNN 将其扩展为实例分割框架。

Mask R-CNN 的主要构建模块:
1. 主干架构
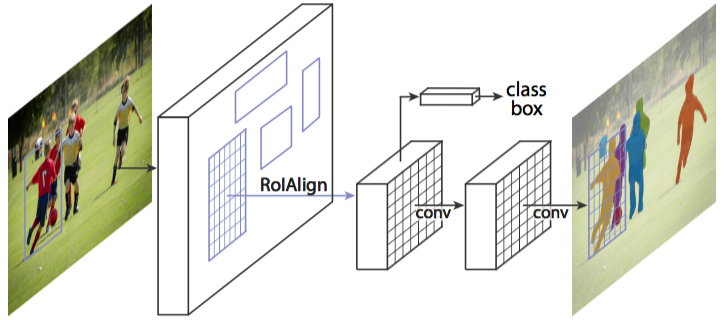
主干网络(上图左边第一个箭头)的简化图示
这是一个标准的卷积神经网络(通常来说是 ResNet50 和 ResNet101),作为特征提取器。底层检测的是低级特征(边缘和角等),较高层检测的是更高级的特征(汽车、人、天空等)。
经过主干网络的前向传播,图像从 1024x1024x3(RGB)的张量被转换成形状为 32x32x2048 的特征图。该特征图将作为下一个阶段的输入。
特征金字塔网络(FPN)
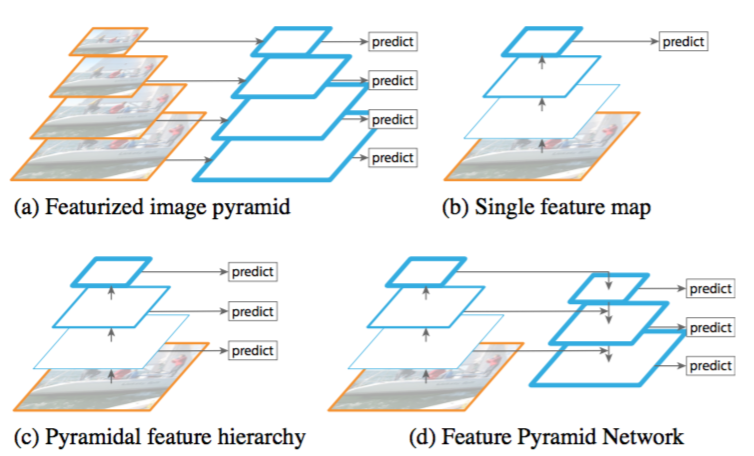
Feaature Pyramid Networks for Object Detection
上述的主干网络还可以进一步提升。由 Mask R-CNN 的同一作者引入的特征金字塔网络(FPN)是对该主干网络的扩展,可以在多个尺度上更好地表征目标。
FPN 通过添加第二个金字塔提升了标准特征提取金字塔的性能,第二个金字塔可以从第一个金字塔选择高级特征并传递到底层上。通过这个过程,它允许每一级的特征都可以和高级、低级特征互相结合。
在我们的 Mask R-CNN 实现中使用的是 ResNet101+FPN 主干网络。
2. 区域建议网络(RPN)

RPN 是一个轻量的神经网络,它用滑动窗口来扫描图像,并寻找存在目标的区域。
RPN 扫描的区域被称为 anchor,这是在图像区域上分布的矩形,如上图所示。这只是一个简化图。实际上,在不同的尺寸和长宽比下,图像上会有将近 20 万个 anchor,并且它们互相重叠以尽可能地覆盖图像。
RPN 扫描这些 anchor 的速度有多快呢?非常快。滑动窗口是由 RPN 的卷积过程实现的,可以使用 GPU 并行地扫描所有区域。此外,RPN 并不会直接扫描图像,而是扫描主干特征图。这使得 RPN 可以有效地复用提取的特征,并避免重复计算。通过这些优化手段,RPN 可以在 10ms 内完成扫描(根据引入 RPN 的 Faster R-CNN 论文中所述)。在 Mask R-CNN 中,我们通常使用的是更高分辨率的图像以及更多的 anchor,因此扫描过程可能会更久。
RPN 为每个 anchor 生成两个输出:
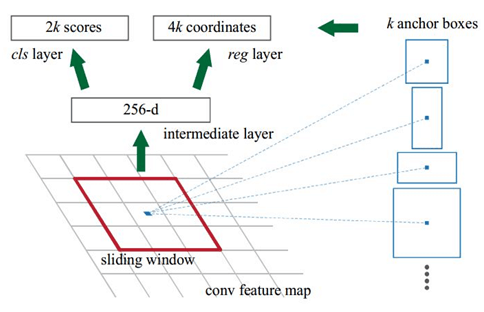
-
anchor 类别:前景或背景(FG/BG)。前景类别意味着可能存在一个目标在 anchor box 中。
-
边框精调:前景 anchor(或称正 anchor)可能并没有完美地位于目标的中心。因此,RPN 评估了 delta 输出(x、y、宽、高的变化百分数)以精调 anchor box 来更好地拟合目标。
使用 RPN 的预测,我们可以选出最好地包含了目标的 anchor,并对其位置和尺寸进行精调。如果有多个 anchor 互相重叠,我们将保留拥有最高前景分数的 anchor,并舍弃余下的(非极大值抑制)。然后我们就得到了最终的区域建议,并将其传递到下一个阶段。
3. ROI 分类器和边界框回归器
这个阶段是在由 RPN 提出的 ROI 上运行的。正如 RPN 一样,它为每个 ROI 生成了两个输出:
-
类别:ROI 中的目标的类别。和 RPN 不同(两个类别,前景或背景),这个网络更深并且可以将区域分类为具体的类别(人、车、椅子等)。它还可以生成一个背景类别,然后就可以弃用 ROI 了。
-
边框精调:和 RPN 的原理类似,它的目标是进一步精调边框的位置和尺寸以将目标封装。
ROI 池化
在我们继续之前,需要先解决一些问题。分类器并不能很好地处理多种输入尺寸。它们通常只能处理固定的输入尺寸。但是,由于 RPN 中的边框精调步骤,ROI 框可以有不同的尺寸。因此,我们需要用 ROI 池化来解决这个问题。
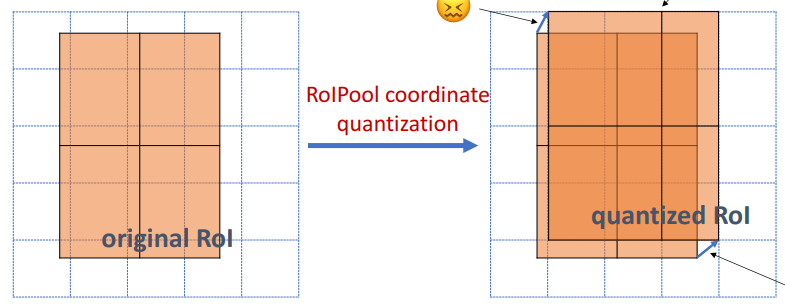
ROI 池化是指裁剪出特征图的一部分,然后将其重新调整为固定的尺寸。这个过程实际上和裁剪图片并将其缩放是相似的(在实现细节上有所不同)。
Mask R-CNN 的作者提出了一种方法 ROIAlign,在特征图的不同点采样,并应用双线性插值,主要是减少量化操作带来的特征损失https://www.cnblogs.com/MY0213/p/9567014.html。在我们的实现中,为简单起见,我们使用 TensorFlow 的 crop_and_resize 函数来实现这个过程。
4. 分割掩码
到第 3 节为止,我们得到的正是一个用于目标检测的 Faster R-CNN。而分割掩码网络正是 Mask R-CNN 的论文引入的附加网络。
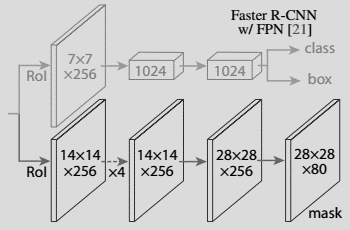
掩码分支是一个卷积网络,取 ROI 分类器选择的正区域为输入,并生成它们的掩码。其生成的掩码是低分辨率的:28x28 像素。但它们是由浮点数表示的软掩码,相对于二进制掩码有更多的细节。掩码的小尺寸属性有助于保持掩码分支网络的轻量性。在训练过程中,我们将真实的掩码缩小为 28x28 来计算损失函数,在推断过程中,我们将预测的掩码放大为 ROI 边框的尺寸以给出最终的掩码结果,每个目标有一个掩码。
