

Socket
一、概述
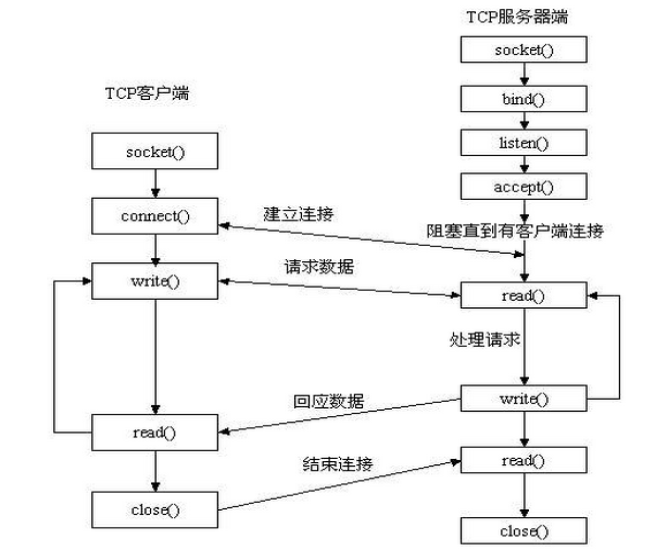
socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求。
socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,对于文件用【打开】【读写】【关闭】模式来操作。socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭)
socket和file的区别:
- file模块是针对某个指定文件进行【打开】【读写】【关闭】
- socket模块是针对 服务器端 和 客户端Socket 进行【打开】【读写】【关闭】
# -*- coding:utf-8 -*-
import socket
ip_port = ('127.0.0.1',9999)
sk = socket.socket()
sk.bind(ip_port)
sk.listen(5)
while True:
print 'server waiting...'
conn,addr = sk.accept()
client_data = conn.recv(1024)
print client_data
conn.sendall('不要回答,不要回答,不要回答')
conn.close()
socket server
# -*- coding:utf-8 -*-
import socket
ip_port = ('127.0.0.1',9999)
sk = socket.socket()
sk.connect(ip_port)
sk.sendall('请求占领地球')
server_reply = sk.recv(1024)
print server_reply
sk.close()
socket client
WEB服务应用:
#coding:utf-8
import socket
def handle_request(client):
buf = client.recv(1024)
client.send("HTTP/1.1 200 OK\r\n\r\n")
client.send("Hello, World")
def main():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('localhost',8080))
sock.listen(5)
while True:
connection, address = sock.accept()
handle_request(connection)
connection.close()
if __name__ == '__main__':
main()
二、解释
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM,0)

参数一:地址簇 socket.AF_INET IPv4(默认) socket.AF_INET6 IPv6 socket.AF_UNIX 只能够用于单一的Unix系统进程间通信 参数二:类型 socket.SOCK_STREAM 流式socket , for TCP (默认) socket.SOCK_DGRAM 数据报式socket , for UDP socket.SOCK_RAW 原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以;其次,SOCK_RAW也可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头。 socket.SOCK_RDM 是一种可靠的UDP形式,即保证交付数据报但不保证顺序。SOCK_RAM用来提供对原始协议的低级访问,在需要执行某些特殊操作时使用,如发送ICMP报文。SOCK_RAM通常仅限于高级用户或管理员运行的程序使用。 socket.SOCK_SEQPACKET 可靠的连续数据包服务 参数三:协议 0 (默认)与特定的地址家族相关的协议,如果是 0 ,则系统就会根据地址格式和套接类别,自动选择一个合适的协议
ip_port = ('127.0.0.1',9999)
sk = socket.socket(socket.AF_INET,socket.SOCK_DGRAM,0)
sk.bind(ip_port)
while True:
data = sk.recv(1024)
print data
import socket
ip_port = ('127.0.0.1',9999)
sk = socket.socket(socket.AF_INET,socket.SOCK_DGRAM,0)
while True:
inp = raw_input('数据:').strip()
if inp == 'exit':
break
sk.sendto(inp,ip_port)
sk.close()
sk.bind(address)
s.bind(address) 将套接字绑定到地址。address地址的格式取决于地址族。在AF_INET下,以元组(host,port)的形式表示地址。
sk.listen(backlog)
开始监听传入连接。backlog指定在拒绝连接之前,可以挂起的最大连接数量。
backlog等于5,表示内核已经接到了连接请求,但服务器还没有调用accept进行处理的连接个数最大为5
这个值不能无限大,因为要在内核中维护连接队列
sk.setblocking(bool)
是否阻塞(默认True),如果设置False,那么accept和recv时一旦无数据,则报错。
sk.accept()
接受连接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址。 接收TCP 客户的连接(阻塞式)等待连接的到来
sk.connect(address)
连接到address处的套接字。一般,address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
sk.connect_ex(address)
同上,只不过会有返回值,连接成功时返回 0 ,连接失败时候返回编码,例如:10061
sk.close()
关闭套接字
sk.recv(bufsize[,flag])
接受套接字的数据。数据以字符串形式返回,bufsize指定最多可以接收的数量。flag提供有关消息的其他信息,通常可以忽略。
sk.recvfrom(bufsize[.flag])
与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。
sk.send(string[,flag])
将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。
sk.sendall(string[,flag])
将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。
sk.sendto(string[,flag],address)
将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。该函数主要用于UDP协议。
sk.settimeout(timeout)
设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如 client 连接最多等待5s )
sk.getpeername()
返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。
sk.getsockname()
返回套接字自己的地址。通常是一个元组(ipaddr,port)
sk.fileno()
套接字的文件描述符
ip_port = ('127.0.0.1',9999)
sk = socket.socket(socket.AF_INET,socket.SOCK_DGRAM,0)
sk.bind(ip_port)
while True:
data = sk.recv(1024)
print data
import socket
ip_port = ('127.0.0.1',9999)
sk = socket.socket(socket.AF_INET,socket.SOCK_DGRAM,0)
while True:
inp = raw_input('数据:').strip()
if inp == 'exit':
break
sk.sendto(inp,ip_port)
sk.close()
UDP Demo
三、实例
智能机器人
ip_port = ('127.0.0.1',8888)
sk = socket.socket()
sk.bind(ip_port)
sk.listen(5)
while True:
conn,address = sk.accept()
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
Flag = True
while Flag:
data = conn.recv(1024)
if data == 'exit':
Flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
conn.close()
服务端
# -*- coding:utf-8 -*-
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
# print self.request,self.client_address,self.server
conn = self.request
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
Flag = True
while Flag:
data = conn.recv(1024)
if data == 'exit':
Flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
if __name__ == '__main__':
server = SocketServer.ThreadingTCPServer(('127.0.0.1',8009),MyServer)
server.serve_forever()
SocketServer模块
一、使用以源码剖析
对于默认Socket服务端处理客户端请求时,按照阻塞方式依次处理请求,SocketServer实现同事处理多个请求。
# -*- coding:utf-8 -*-
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
# print self.request,self.client_address,self.server
conn = self.request
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
Flag = True
while Flag:
data = conn.recv(1024)
if data == 'exit':
Flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
if __name__ == '__main__':
server = SocketServer.ThreadingTCPServer(('127.0.0.1',8009),MyServer)
server.serve_forever()
import socket
ip_port = ('127.0.0.1',8009)
sk = socket.socket()
sk.connect(ip_port)
sk.settimeout(5)
while True:
data = sk.recv(1024)
print 'receive:',data
inp = raw_input('please input:')
sk.sendall(inp)
if inp == 'exit':
break
sk.close()
客户端
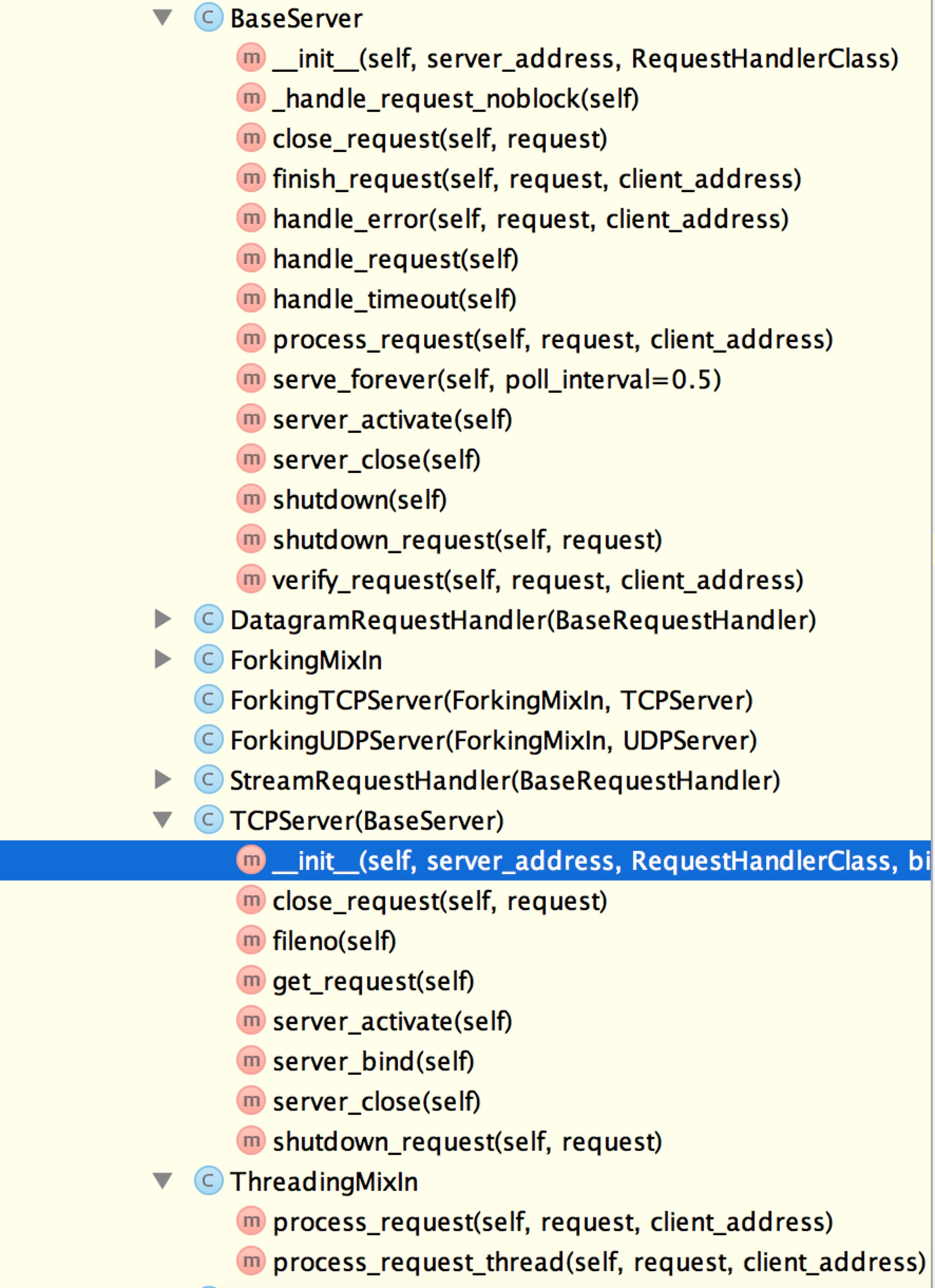
从剖析上述源码执行流程,对源码精简如下:
import socket
import threading
import select
def process(request, client_address):
print request,client_address
conn = request
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
flag = True
while flag:
data = conn.recv(1024)
if data == 'exit':
flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sk.bind(('127.0.0.1',8002))
sk.listen(5)
while True:
r, w, e = select.select([sk,],[],[],1)
print 'looping'
if sk in r:
print 'get request'
request, client_address = sk.accept()
t = threading.Thread(target=process, args=(request, client_address))
t.daemon = False
t.start()
sk.close()
如精简代码可以看出,SocketServer之所以可以同时处理请求得益于 select 和 Threading 两个东西,其实本质上就是在服务器端为每一个客户端创建一个线程,当前线程用来处理对应客户端的请求,所以,可以支持同时n个客户端链接(长连接)。
#coding:utf-8
import SocketServer
import os
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
base_path = 'G:/temp'
conn = self.request
print 'connected...'
while True:
pre_data = conn.recv(1024)
#获取请求方法、文件名、文件大小
cmd,file_name,file_size = pre_data.split('|')
# 防止粘包,给客户端发送一个信号。
conn.sendall('nothing')
#已经接收文件的大小
recv_size = 0
#上传文件路径拼接
file_dir = os.path.join(base_path,file_name)
f = file(file_dir,'wb')
Flag = True
while Flag:
#未上传完毕,
if int(file_size)>recv_size:
#最多接收1024,可能接收的小于1024
data = conn.recv(1024)
recv_size+=len(data)
#写入文件
f.write(data)
#上传完毕,则退出循环
else:
recv_size = 0
Flag = False
print 'upload successed.'
f.close()
instance = SocketServer.ThreadingTCPServer(('127.0.0.1',9999),MyServer)
instance.serve_forever()
FTP上传文件(服务端)
import sys
import os
ip_port = ('127.0.0.1',9999)
sk = socket.socket()
sk.connect(ip_port)
container = {'key':'','data':''}
while True:
# 客户端输入要上传文件的路径
input = raw_input('path:')
# 根据路径获取文件名
file_name = os.path.basename(path)
# 获取文件大小
file_size=os.stat(path).st_size
# 发送文件名 和 文件大小
sk.send(file_name+'|'+str(file_size))
# 为了防止粘包,将文件名和大小发送过去之后,等待服务端收到,直到从服务端接受一个信号(说明服务端已经收到)
sk.recv(1024)
send_size = 0
f= file(path,'rb')
Flag = True
while Flag:
if send_size + 1024 >file_size:
data = f.read(file_size-send_size)
Flag = False
else:
data = f.read(1024)
send_size+=1024
sk.send(data)
f.close()
sk.close()
FTP上传文件(客户端)
对于大文件处理:
send只会向缓冲区写一次,传入的内容不一定能发完,所以,返回值是实际发送的大小。
例如:
1023M = send(1g数据) 那么实际是发送了 1023M,其他 1M 就是漏发了
sendall,内部调用send会一直向缓冲区写,直到文件全部写完。
例如:
sendall(1g数据)
第一次:
send(1023M)
第二次:
send(1M)
==========
发送大文件时候,不可能全部读1G内存,需要open文件时,一点一点读,然后再发。
# 大文件大小
file_size=os.stat(文件路径).st_size
# 打开大文件
f = file(文件路径,'rb')
# 已经发送的数据
send_size = 0
while Flag:
# 大文件只剩下 不到 1024 字节,其他已经被发送。
if send_size + 1024 > file_size:
# 从大文件中读取小于 1024字节,可能是 10字节...
data = f.read(file_size-send_size)
Flag = False
else:
# 从大文件中读取 1024 字节
data = f.read(1024)
# 记录已经发送了多少字节
send_size += 1024
# 将大文件中的数据,分批发送到缓冲区,每次最多发 1024 字节
sk.sendall(data)
二、select
Linux中的 select,poll,epoll 都是IO多路复用的机制。
I/O多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
select select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。 select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点,事实上从现在看来,这也是它所剩不多的优点之一。 select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。 另外,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大量TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。 poll poll在1986年诞生于System V Release 3,它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。 poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。 另外,select()和poll()将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select()和poll()的时候将再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。 epoll 直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。 epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。 epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。 另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
Python select 用于监听多个文件描述符:
import threading
import select
def process(request, client_address):
print request,client_address
conn = request
conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
flag = True
while flag:
data = conn.recv(1024)
if data == 'exit':
flag = False
elif data == '0':
conn.sendall('通过可能会被录音.balabala一大推')
else:
conn.sendall('请重新输入.')
s1 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s1.bind(('127.0.0.1',8020))
s1.listen(5)
s2 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s2.bind(('127.0.0.1',8021))
s2.listen(5)
while True:
r, w, e = select.select([s1,s2,],[],[],1)
print 'looping'
for s in r:
print 'get request'
request, client_address = s.accept()
t = threading.Thread(target=process, args=(request, client_address))
t.daemon = False
t.start()
s1.close()
s2.close()
服务端
# -*- coding:utf-8 -*-
import socket
ip_port = ('127.0.0.1',8020)
sk = socket.socket()
sk.connect(ip_port)
sk.settimeout(5)
while True:
data = sk.recv(1024)
print 'receive:',data
inp = raw_input('please input:')
sk.sendall(inp)
if inp == 'exit':
break
sk.close()
客户端:8020
# -*- coding:utf-8 -*-
import socket
ip_port = ('127.0.0.1',8021)
sk = socket.socket()
sk.connect(ip_port)
sk.settimeout(5)
while True:
data = sk.recv(1024)
print 'receive:',data
inp = raw_input('please input:')
sk.sendall(inp)
if inp == 'exit':
break
sk.close()
客户端:8021
三、threading
问答:
- 应用程序、进程、线程关系?
- 为什么要使用多个CPU ?
- 为什么要使用多线程?
- 为什么要使用多进程?
- java和C#中的多线程和python多线程的区别?
- Python GIL?
- 线程和进程的选择:计算密集型和IO密集型程序。(IO操作不占用CPU)
1、Python线程
Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import threading
import time
def show(arg):
time.sleep(1)
print 'thread'+str(arg)
for i in range(10):
t = threading.Thread(target=show, args=(i,))
t.start()
print 'main thread stop'
上述代码创建了10个“前台”线程,然后控制器就交给了CPU,CPU根据指定算法进行调度,分片执行指令。
更多方法:
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止 - join 逐个执行每个线程,执行完毕后继续往下执行...
- run 线程被cpu调度后执行此方法
2、线程锁
由于线程之间是进行随机调度,并且每个线程可能只执行n条执行之后,CPU接着执行其他线程。所以,可能出现如下问题:


#!/usr/bin/env python
# -*- coding:utf-8 -*-
import threading
import time
gl_num = 0
def show(arg):
global gl_num
time.sleep(1)
gl_num +=1
print gl_num
for i in range(10):
t = threading.Thread(target=show, args=(i,))
t.start()
print 'main thread stop'
未使用线程锁
#!/usr/bin/env python
#coding:utf-8
import threading
import time
gl_num = 0
lock = threading.RLock()
def Func():
lock.acquire()
global gl_num
gl_num +=1
time.sleep(1)
print gl_num
lock.release()
for i in range(10):
t = threading.Thread(target=Func)
t.start()
扩展:进程
1、创建多进程程序
from multiprocessing import Process
import threading
import time
def foo(i):
print 'say hi',i
for i in range(10):
p = Process(target=foo,args=(i,))
p.start()
注意:由于进程之间的数据需要各自持有一份,所以创建进程需要的非常大的开销。
2、进程共享数据
进程各自持有一份数据,默认无法共享数据
#!/usr/bin/env python
#coding:utf-8
from multiprocessing import Process
from multiprocessing import Manager
import time
li = []
def foo(i):
li.append(i)
print 'say hi',li
for i in range(10):
p = Process(target=foo,args=(i,))
p.start()
print 'ending',li
from multiprocessing import Process,Array
temp = Array('i', [11,22,33,44])
def Foo(i): temp[i] = 100+i
for item in temp:
print i,'----->',item
for i in range(2):
p = Process(target=Foo,args=(i,))
p.start()
p.join()
#方法二:manage.dict()共享数据
from multiprocessing import Process,Manager
manage = Manager()
dic = manage.dict()
def Foo(i):
dic[i] = 100+i
print dic.values()
for i in range(2):
p = Process(target=Foo,args=(i,))
p.start()
p.join()
进程间共享数据
3、进程池
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from multiprocessing import Process,Pool
import time
def Foo(i):
time.sleep(2)
return i+100
def Bar(arg):
print arg
pool = Pool(5)
#print pool.apply(Foo,(1,))
#print pool.apply_async(func =Foo, args=(1,)).get()
for i in range(10):
pool.apply_async(func=Foo, args=(i,),callback=Bar)
print 'end'
pool.close()
pool.join()
