Language-only Efficient Training of Zero-shot Composed Image Retrieval
概
本文提出了一种仅在文本上训练的 Zero-Shot Composed Image Retrieval (ZS-CIR) 方法.
LinCIR

-
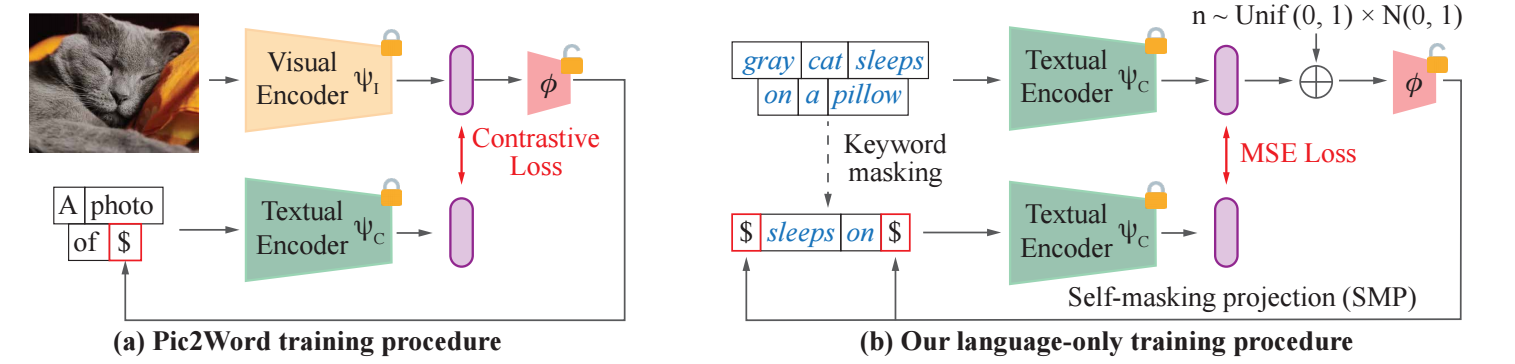
上图展示了一种最为常见的 ZS-CIR 方法: 其将 query image 映射到 token embedding 空间, 然后通过 text encoder 得到可用于 text-to-image rtrieval 的表征.
-
注意到, 这种方式需要训练 , 其通常依赖一个缺乏多样性的模板 'A photo of [$]' 来实现.
-
然而作者发现, 这种方式限制了其推广到更大的模型中去. 如下图所示, 当 encoder 变得更大的时候, 遵循上图的方法反而会产生更差的性能.
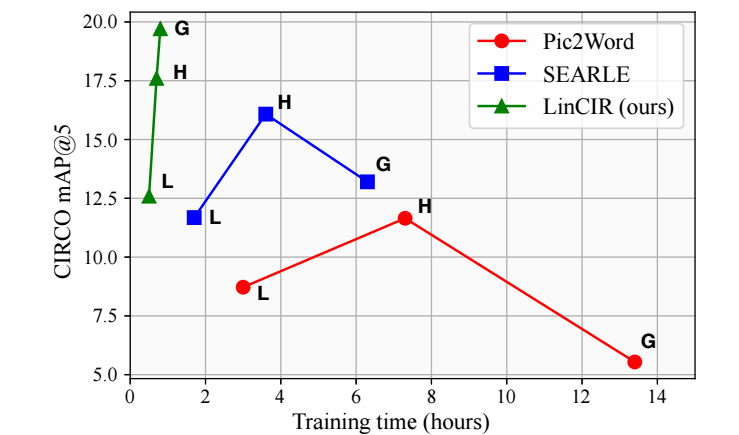
-
本文提出了一种 self-masking projection (SMP) 的任务, 仅仅依赖文本进行训练. 步骤如下:
- 给定文本 , 通过 tokenizer .
- 给定文本 , 通过 text encoder 得到表征:
- 添加一定噪声, 然后通过 映射为 token embedding 空间:
- 将 中对应 'keywords' 的 token 替换为 . 这里 'keywords' 为名词和形容词.
- 再次通过 text encoder 得到:
- 利用 MSE loss 要求 靠近 .
-
注意, 上述训练过程仅 部分是可训练的. 和之前的方法一样, 是映射回 token embedding 空间的工具. 但是相交于之前的训练, 这里没有固定的模板, 从而能够保证训练的稳定.
-
此外, 这里添加的 noise 为均匀分布和高斯分布的组合, 而非简单的高斯分布. 作者认为, 需要涉及一个合适的分布从而保证 可以直接作用在 image feature 上. 经验上, 作者发现 LinCIR 所采用的这种 noise 能够降低 modality gap.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2024-02-24 ROLAND Graph Learning Framework for Dynamic Graphs
2024-02-24 EvolveGCN Evolving Graph Convolutional Networks for Dynamic Graphs
2023-02-24 Self-Attentive Sequential Recommendation
2020-02-24 The Expressive Power of Neural Networks: A View from the Width