Spherical Linear Interpolation and Text-Anchoring for Zero-shot Composed Image Retrieval
概
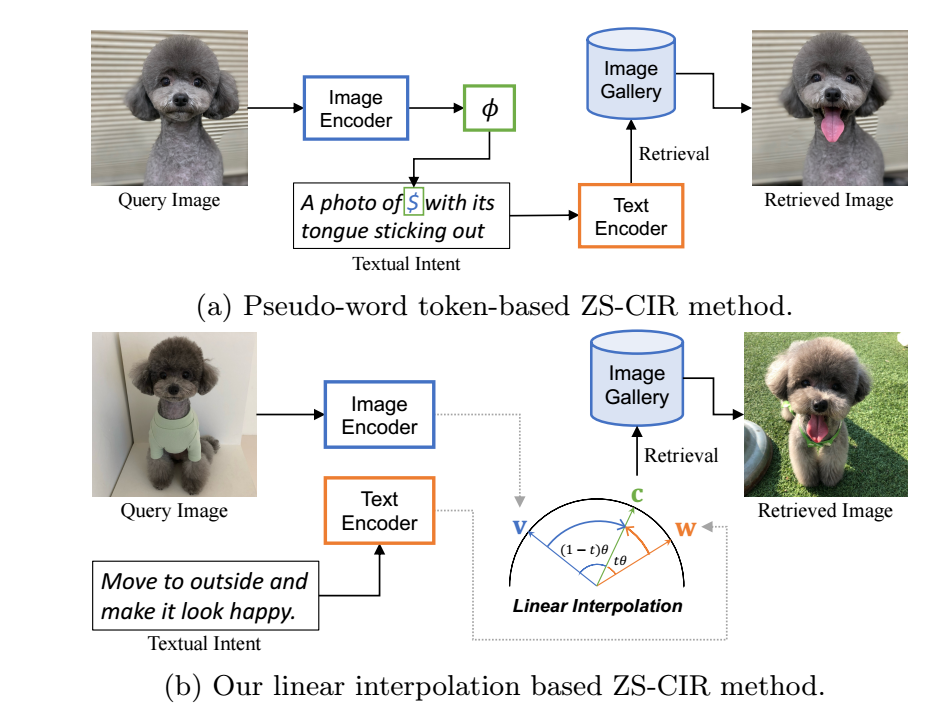
本文提出了一种非常简单的 Zero-Shot Composed Image Retrieval (ZS-CIR) 方法. 仅通过 image feature 和 text feature 间的球面线性插值就可以得到 SOTA 的结果.
Spherical Linear Interpolation (Slerp)
-
ZS-CIR 的目标是找到匹配图片 和一段文本描述 的其它图片.
-
通过 visual/textual encoder 我们可以得到二者的向量表示 (normalize 过后的):
-
本文提出了一种非常简单的方式: Slerp. 即通过两个向量的球面线性插值得到
其中 为两个向量间的夹角.
注: 上面的系数是通过三角形三边三角如下的关系得到的:
其中 分别为角 所对应的边.
- 作者发现, 通常情况下, text-only 的检索比 image-only 的检索效果要好很多很多, 所以作者推荐设置一个 , 从而 实际上更偏向于文本描述.
Text-Anchored-Tuning (TAT)
-
注意到, 到目前为止, 我们只用到了预训练的 encoder 而没有进行任何额外的训练, 实际上根据实验结果可以发现, 仅此就可以取得非常好的结果了.
-
但是, 作者发现效果可以进一步提升, 提升的空间来自譬如 CLIP 的得到 image/text 表示实际上有很大的 gap. 于是作者希望通过微调 image encoder 来进一步将 image 表示推向文本表示.
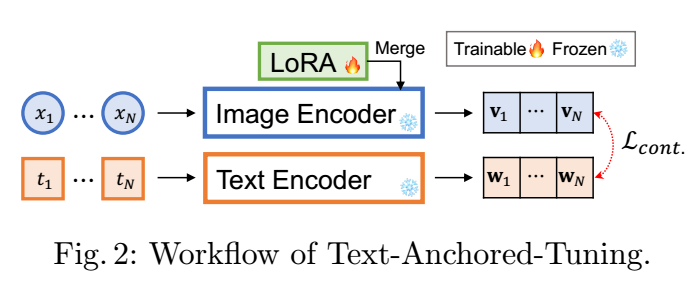
- 如上图所示, 除了用 LoRA 微调 image encoder 外, 其余部分均是固定的. 训练目标和 CLIP 所用的对比学习保持一致, 所以整体上是非常简单的.
代码
注: 作者仅开源了部分代码.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2024-02-24 ROLAND Graph Learning Framework for Dynamic Graphs
2024-02-24 EvolveGCN Evolving Graph Convolutional Networks for Dynamic Graphs
2023-02-24 Self-Attentive Sequential Recommendation
2020-02-24 The Expressive Power of Neural Networks: A View from the Width