Knowledge-Enhanced Dual-stream Zero-shot Composed Image Retrieval
概
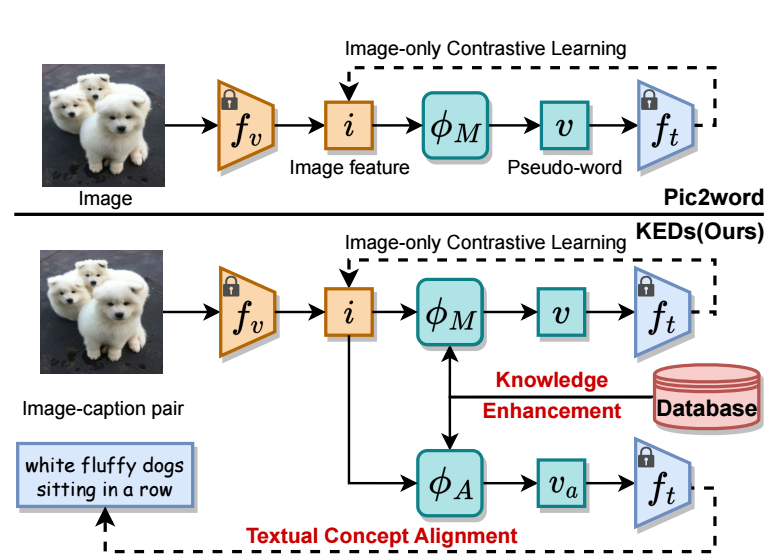
以往的 zero-shot Composed Image Retrieval (ZS-CIR) 方法将 visual feature 映射到 textual token embedding 空间中, 从而使得我们可以通过文本来操控这些 visual features. 然后, 作者认为这种方式虽然效果不错, 但是还是太粗略了, 很难指望如 Pic2Word 那样仅仅依赖 image-only 的对比学习就能够使得学习到的 visual feature 会有足够细节可操控性.
KEDs
-
以往的 zero-shot 方法, 实际上并没有用到 caption 信息, 本文希望引入额外的 textual concept alignment (以及一些额外的 knowdege enhancement).
-
首先, 对于一个图片 \(\bm{I}\) 以及其标题 \(\bm{T}\), 我们通过 (比如 CLIP) 可以得到 visual 和 textual 表征:
\[\bm{i} = f_v (\bm{I}) \in \mathbb{R}^d, \quad \bm{t} = f_t (\bm{T}) \in \mathbb{R}^d. \] -
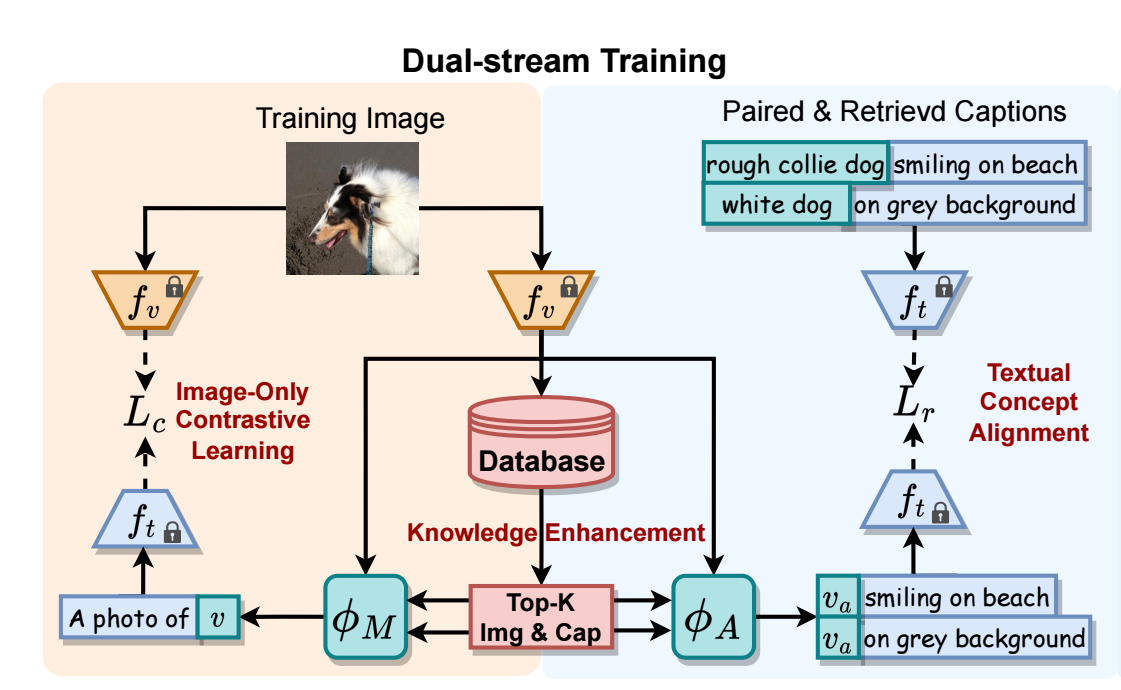
除了之前的 ZS-CIR 方法常用的 imgae-only contrastive learning 分支, KEDs:
- 首先从整个数据集中 (随机) 挑选大约 0.5M 的 image-caption 对;
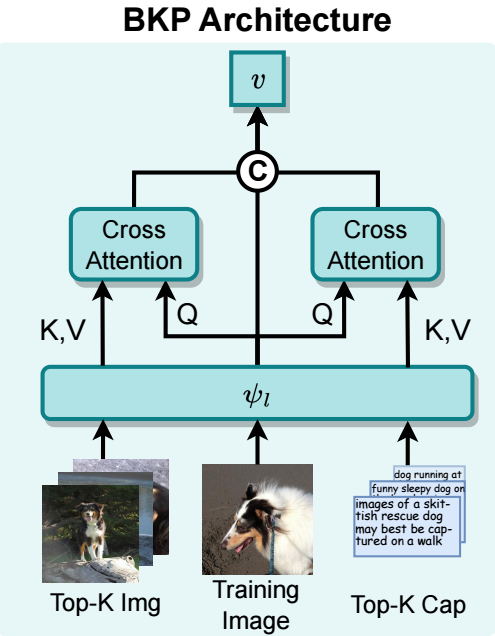
- 对于图片特征 \(\bm{i}\), 通过 faiss library (Facebook AI Similarity Search) 挑选 top-\(K=16\) 的 image features \(\{\bm{t}_k^r\}_{k=1}^K\) 和 caption features \(\{\bm{i}_k^r\}_{k=1}^K\);
- 将这些信息进行融合, 分别得到\[\bm{v}_i = \text{CrossAttn}( \psi_l(\bm{i}), \psi_l (\{\bm{i}_k^r\}_{k=1}^K), \psi_l (\{\bm{i}_k^r\}_{k=1}^K), ), \\ \bm{v}_c = \text{CrossAttn}( \psi(\bm{i}), \psi_l (\{\bm{t}_k^r\}_{k=1}^K), \psi_l (\{\bm{t}_k^r\}_{k=1}^K), ); \]
- 最后我们得到一个拼接后的向量, 该向量用于 image-only 部分的对比学习:\[\bm{v} = \text{concat}( \psi(\bm{i}), \bm{v}_i, \bm{v}_c ) \in \mathbb{R}^{3d}. \]
-
上述最后两步的图示过程如下, 直觉是通过 top-\(K\) image/textual features 进行一个加权融合, 从而得到的向量更易于用于检索.
-
除此之外, 我们想要进一步用到 query image 本身的 caption 信息:
- 对于图片 \((\bm{I}, \bm{T})\), 通过 spacy 来得到额外的 context description, 在得到的 pseudo-triplets 上训练一个额外的 projection \(\phi_A\), 假设 \(\hat{\bm{v}}_a\) 是把经过 \(\phi_A\) 投影后的图片特征加到描述后经过 textual encoder \(f_t\) 得到的特征, 我们要求其和标题特征一致:\[\mathcal{L}_{cos} = 1 - \cos(\hat{\bm{v}}_a, \bm{t}); \]
- 对每个标题 \(\bm{T}\) 额外检索一些标题用于丰富描述, 比如 "Husky on the sofa" 和 "A sleeping white dog" 两个标题其实内在语义上是比较一致的, 假设有两个标题, 我们要求 \(\hat{\bm{v}_a}\) 平均地和两个标题一致:\[\mathcal{L}_{sup} = 1 - \frac{1}{2}\cdot \big( \cos(\hat{\bm{v}}_a, f_t (\bm{T})) + \cos(\hat{\bm{v}}_a, f_t (\bm{T}')) \big). \]
- 对于图片 \((\bm{I}, \bm{T})\), 通过 spacy 来得到额外的 context description, 在得到的 pseudo-triplets 上训练一个额外的 projection \(\phi_A\), 假设 \(\hat{\bm{v}}_a\) 是把经过 \(\phi_A\) 投影后的图片特征加到描述后经过 textual encoder \(f_t\) 得到的特征, 我们要求其和标题特征一致:
-
由于现在我们实际上有 \(\hat{\bm{v}}\) 和 \(\hat{\bm{v}}_a\) 两种可以用于检索的特征, 在实际推理的时候, 采用如下的加权的方式:
\[\bm{v}_h = \alpha \hat{\bm{v}} + (1 - \alpha) \hat{\bm{v}}_a. \]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号