Pic2Word
概
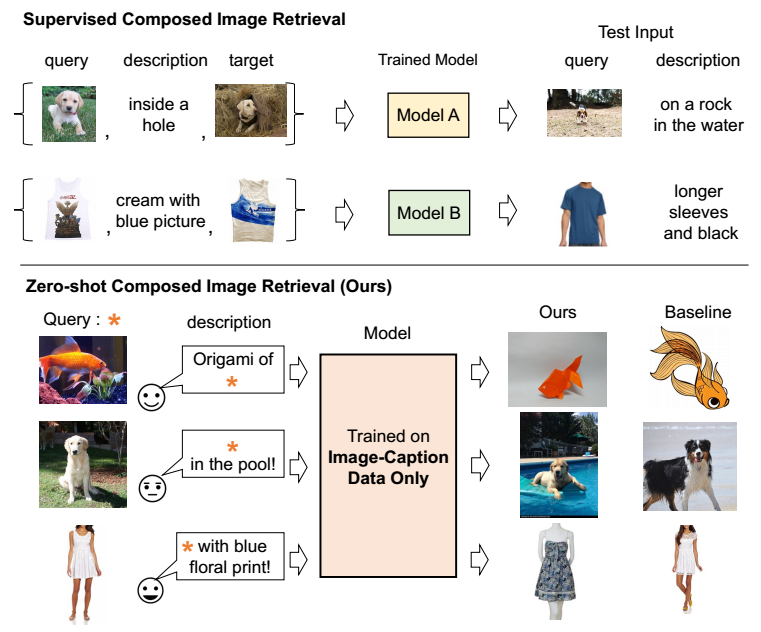
本文关注的是 Composed Image Retrieval (CIR) 任务: 给定一个 reference (query) image 和一段文本描述, 检索同时满足二者需求的图片. 比如给定一张狗狗趴在草地上的图片, 和一段描述 "在泳池中", 那么理应检索出在泳池中的狗狗的图片.
Pic2Word
-
一般的带监督的 CIR 任务, 其模型训练时依赖三元组: (reference, text, target), 从而能够设计逼近 target 的学习任务.
-
但是这种三元组的获得是很难的 (费时费力). 现存的数据广泛存在的是 (image, text) 这种类型数据.
-
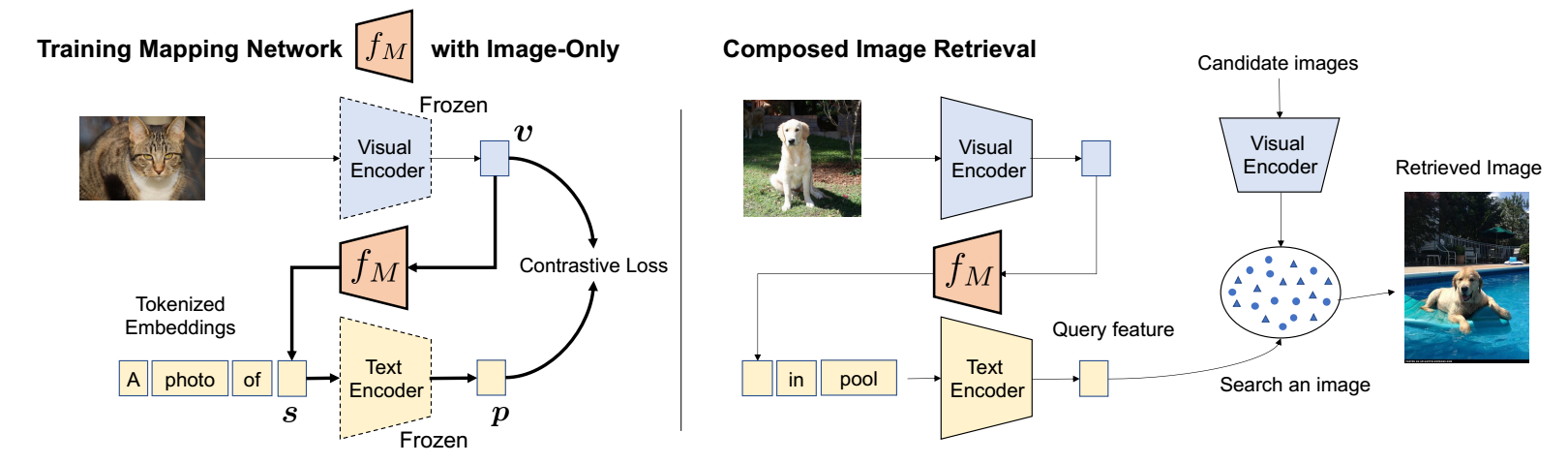
于是, 本文提出了 Pic2Word 在这种情况下也能够获得足够的性能. 如上图所示, 我们需要训练一个 mapping network , 其
将通过 CLIP 得到图片的表征 映射到 token embedding 所在的空间.
这里 是 CLIP 中的 visual encoder. -
然后在要求图片和描述 'A photo of ' 对齐 (文本描述实际上会有多个模板).
-
具体流程如下:
- 提取图片 的表征:
- 通过 mapping network 得到 visual 的 token embedding:
- 通过 text encoder 提取:
- 各自 normalized 后的表征用对比损失进行对齐.
- 提取图片 的表征:
-
训练完之后, 我们就可以把通过 提取得到的图片 token embedding 作为对象插入到任意的语句中, 此时 ' in pool' 很大程度就近似于 'dog in pool', 于是凭借之后的 textual 表征可以进行直接的检索 (candidate 为图片的 visual 表征).
注: 在这之前以及之后也有类似的用 CLIP 的方法, 但是还是 Pic2Word 更加简练.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix