Training Transformers with 4-bit Integers
目录
Xi H., Li C., Chen J. and Zhu J. Training transformers with 4-bit integers. NeurIPS, 2023.
概
本文针对 4-bit 中训练中一些特点 (针对 transformers) 提出了一系列解决方法.
符号说明
- 本文主要考虑 transformer 的 4-bit 量化训练, 其中主要涉及如下的矩阵乘法操作:
4-bit FQT
Learned Step Size Quantization
-
首先, 作者采用 learned step size quantizer (LSQ):
其中 是可学习的参数, 旨在保证将输入的范围放缩到 . 量化后的值属于: , 对于 4-bit 量化, .
-
反量化过程为:
-
给定 LSQ, 量化后的矩阵乘法可以用如下方式近似:
Hadamard Quantization
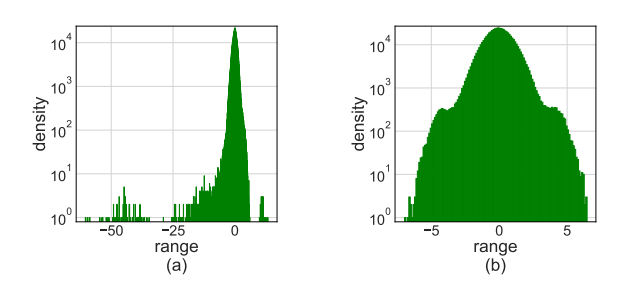
-
但是, 单纯使用 LSQ 会产生很大的误差, 主要原因是, 数据的分布如上图 (a) 所示极不均匀, 所以提出用 Hadamard matrix 来进行一个 smooth.
-
Hadamard matrix 是一个 大小的正交矩阵:
容易证明 . 如 (b) 所示, 明显分布更加均匀了.
-
而且, 这种方式下的量化矩阵乘法的计算也是方便的:
Bit Splitting and Leverage Score Sampling
- 在 Backpropagation 过程中, 作者发现, transformers (但是卷积网络不行) 的梯度呈现出明显的结构稀疏性, 经常一整行为 0. 作者选择抛弃对很小的梯度的量化, 用省下的空间去建模那些较大的值. 这些操作通过 bit splitting 和 leverage score sampling 实现. 感兴趣的请回看原文.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2020-01-08 Conditional Generative Adversarial Nets