Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation
概
对比学习用在协同过滤中通常会对图的结构进行变换, 但是作者发现其实并没有这个必要, 只需要对 Embedding 添加扰动就能获得最好的性能.
Graph CL
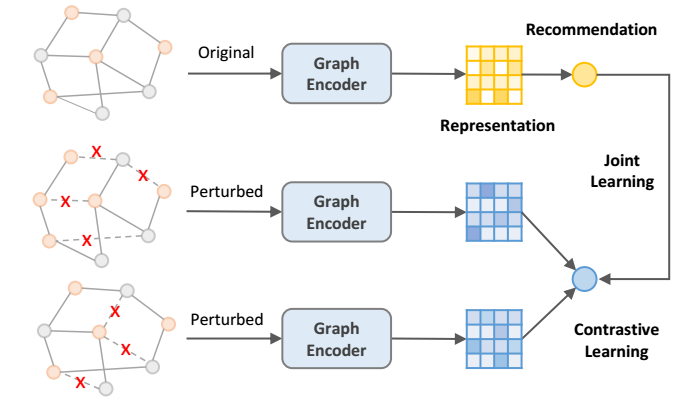
-
协同过滤中的对比学习, 通常采用如下的损失:
\[\mathcal{L}_{joint} = \mathcal{L}_{rec} + \lambda \mathcal{L}_{cl}, \]其中
\[\mathcal{L}_{cl} = \sum_{i \in \mathcal{B}} -\log \frac{ \exp({\mathbf{z}_i'}^T \mathbf{z}_i'' / \tau) }{ \sum_{j \in \mathcal{B}} \exp({\mathbf{z}_i'}^T \mathbf{z}_j'' / \tau) }, \]其中 \(\mathbf{z}', \mathbf{z}''\) 分别 embedding 的两个 view, 比如 SGL 中通过对图结构 mask 得到两个 view. 此外, \(\|\mathbf{z}'\|= \|\mathbf{z}''\|=1\) 是 normalization 后的.
-
作者探究了如下的一种有趣的变种 (称为 SGL-WA):
\[\mathcal{L}_{cl} = \sum_{i \in \mathcal{B}} -\log \frac{ \exp(1 / \tau) }{ \sum_{j \in \mathcal{B}} \exp({\mathbf{z}_i}^T \mathbf{z}_j / \tau) }. \]即, 只有一个 view.
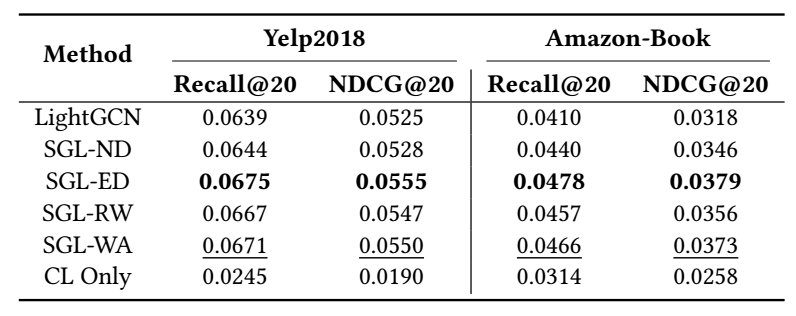
- 如上表所示, SGL-WA 的结果几乎和 SGL-ED 差不多了, 这说明, SGL 真正有用的部分其实是对比损失部分而不是 view 的产生方式.
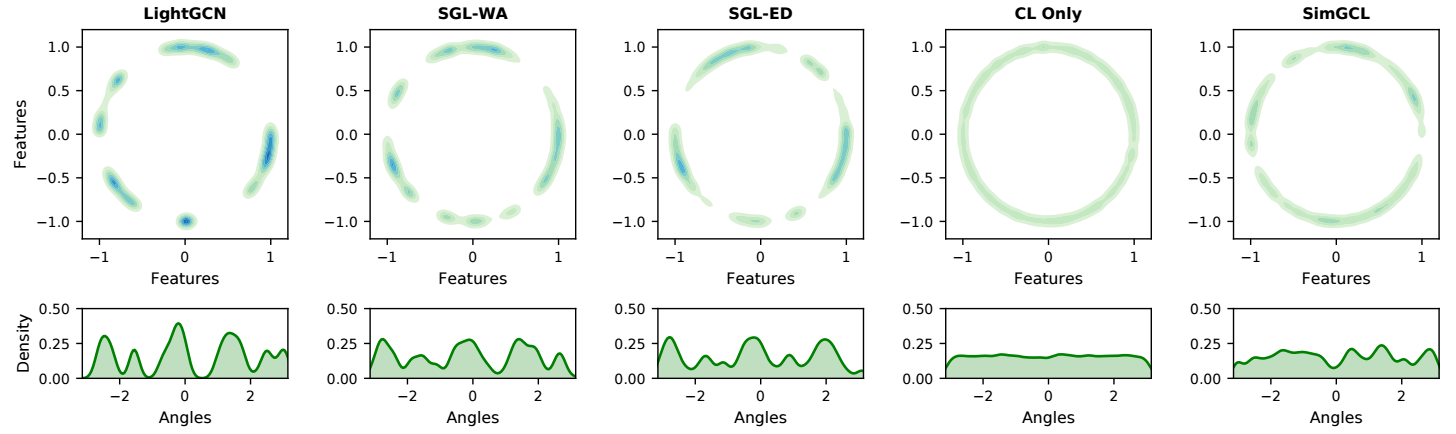
- 进一步地, 作者探究对比损失能够带来些什么呢? 作者发现, 对比损失的作用, 实际上是让 embedding 分布更加均匀 (这个其实纯研究对比损失的已经指出来了).
SimGCL

-
于是, 作者的相反就很简单了, 通过如下的方式制造两种不同的 view:
\[\mathbf{e}_i' = \mathbf{e}_i + \epsilon \cdot \frac{\Delta_i'}{\|\Delta_i'\|}, \mathbf{e}_i'' = \mathbf{e}_i + \epsilon \cdot \frac{\Delta_i''}{\|\Delta ''\|}, \]其中 \(\Delta = \bar{\Delta} \odot \text{sign} (\mathbf{e}_i), \bar{\Delta} \sim U(0, 1)\)?
-
对于 LightGCN 这个 backbone, 每一层都会添加独立的噪声.
代码
[official]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号