Long-Sequence Recommendation Models Need Decoupled Embeddings
概
通过 embedding 选择短序列, 最好从一个独立的 embedding table 中选择.
Decoupled Attention and Representation Embeddings (DARE) model
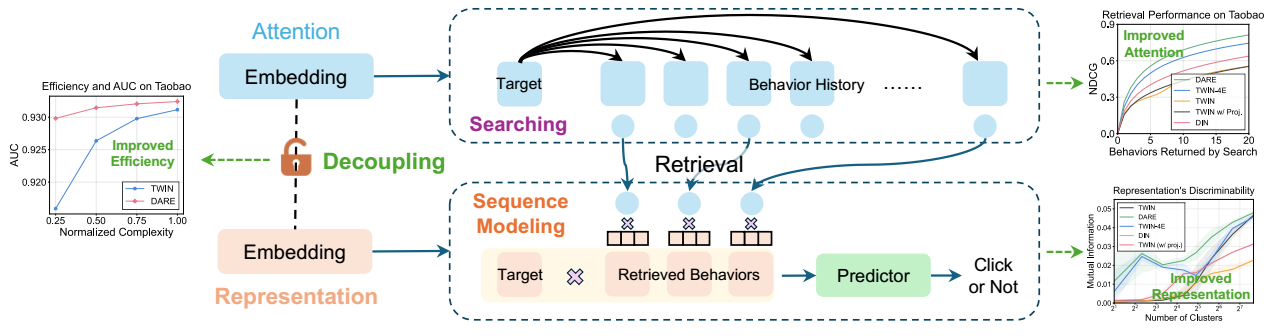
- 现在推荐系统中常常会出现很长很长的序列, 这个时候, 出于效率的角度考虑, 我们通常会从中挑选出一个更为合适的短序列. 最流行的挑选方式就是利用 attention 来进行选择. 但是作者发现这么做有一些问题.
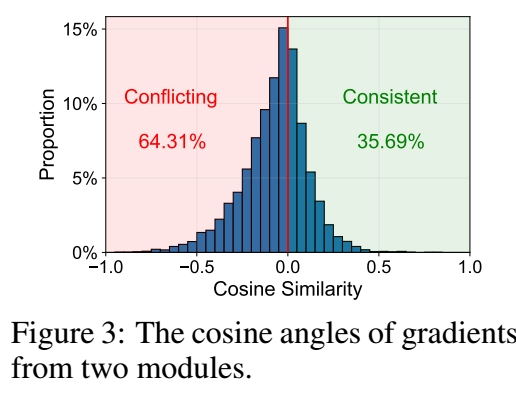
- 作者分别对从 attention 出得到的梯度和从 embedding 本身得到的梯度进行分析, 如上图所示, 发现二者的梯度方向大部分是不一致的.

-
一种看似可行的方案是利用投影矩阵, 但是作者发现这个在推荐领域似乎并不那么有用. 如上图所示, 在 Taobao 这个数据集上, 加入了投影反而起到了反作用.
-
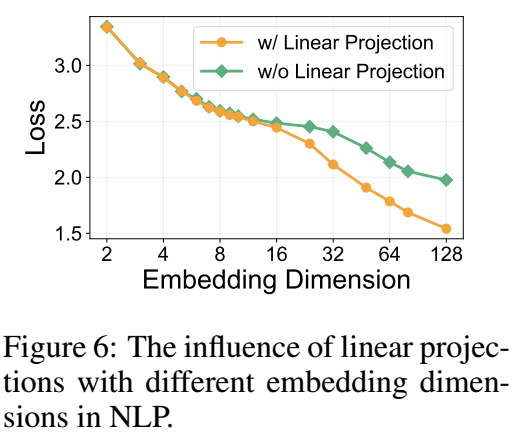
作者认为这可能是因为投影矩阵过于小导致的. 因为在推荐中, embedding 的维度通常不会设置的很大, 所以这导致投影矩阵的表达能力有限 (个人认为, 从空间的角度考虑, 其实是 embedding 所表示的空间太小了).
-
如上图所示, 作者在 NLP 的任务做了一个测试, 当 embedding dimension 增加的时候, 投影矩阵的大小也随之增加, 在 dimension 很小的时候, 线性投影没啥作用, 之后当大到一定程度才会有所作用.
-
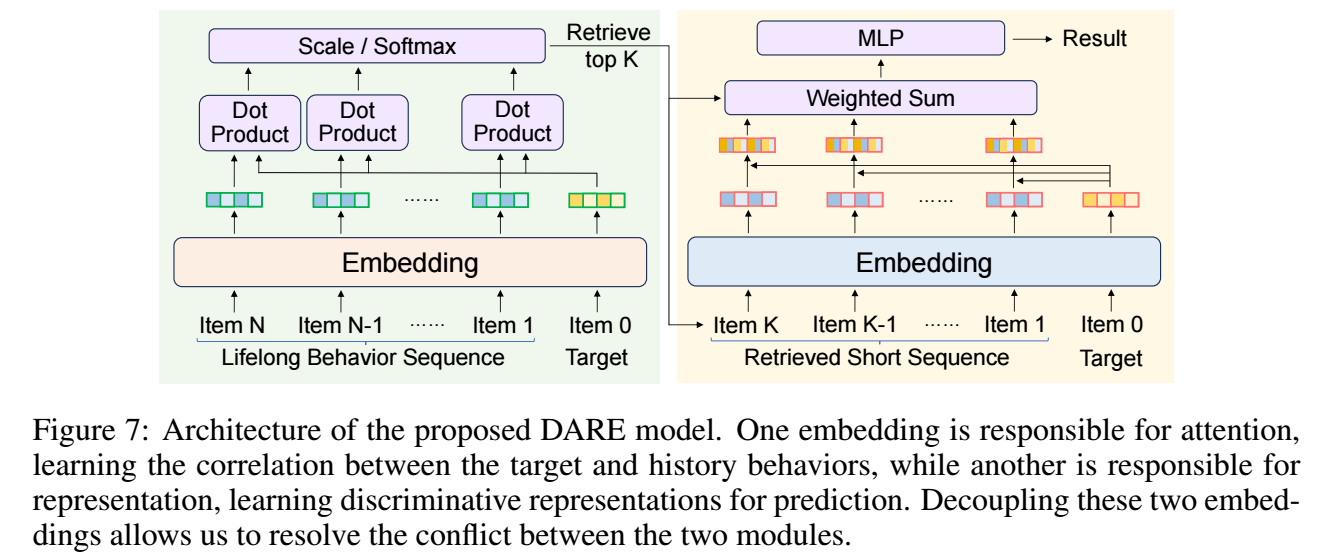
所以最终的方案就是, embedding 的表示和检索采取两个独立的 embedding table:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2023-10-06 Graph-less Collaborative Filtering
2022-10-06 Topology Attack and Defense for Graph Neural Networks: An Optimization Perspective
2020-10-06 ROC and AUC
2019-10-06 样条函数