[1] Newman M. E. J. and GirvanM. Finding and evaluating community structure in networks. Physical review E, 2004.
[2] Newman M. E. J. Fast algorithm for detecting community structure in networks. Physical Review E, 2004.
[3] Blondel V. D>, Guillaume J., Lambiotte R. and Lefebvre E. Fast unfolding of communities in large networks. JSTAT, 2008.
[4] Shiokawa H., Fujiwara Y. and Onizuka M. Fast algorithm for modularity-based graph clustering. AAAI, 2013.
[5] Arai J., Shiokawa H., Yamamuro T., Onizuka M. and Iwamura S. Rabbit order: Just-in-time parallel reordering for fast graph analysis. IPOPS, 2016.
概
介绍一类基于 modularity 指标的 graph 的聚类方法.
符号说明
- G=(V,E), 图;
- Gk=(Vk,Ek),Ek:={(vi,vj)∈E|vi,vj∈Vk}, 子图;
注: 这里讨论的边 (vi,vj) 是有向的, 无向图可以扩展成 (vi,vj),(vj,vi) 同时存在即可.
Modularity
-
我们的目标是将图 G 切分成 K 个子图, 而且我们希望子图之内的点关系紧密, 子图和子图之间尽可能关系不那么紧密.
-
首先, 我们需要定义一个指标来形式化这一点.
- 假设我们已经有了一个划分, 得到了 K 个子图, 由此我们可以计算:
eij=|{(v,v′)∈E|v∈Vi,v′∈Vj}||E|
为子图 i 到子图 j 的边的数量占全部边的比重.
- 接着我们可以计算行和:
ai=K∑j=1eij,
为子图 Gi 到所有点的连边占所有边的一个比重.
-
由此, 我们可以定义如下指标来刻画子图分化的优劣 (越大越好):
Q=∑i(eii−a2i).
-
让我们来理解下这么设计的原因:
- 假设 G 是一个随机图, 任意两个节点都有 p>0 的概率相连.
- 容易证明, 此时对于任意两个不交的子图 Gi,Gj, 我们有:
eij=|Vi||Vj|p|V|2p=|Vi||Vj||V|2.
于是ai=K∑j=1eij=|Vi|∑j|Vj||V|2=|Vi||V|.
- 于是, 当 G 为随机图的时候, 我们有
eij=aiaj→eii=a2i.
- 于是 Q≈0 表明实际上整个图是趋向于随即图的, 反之 Q 变大的时候, 里随机图越远.
-
让我们进一步分析 Q. 令 E=[eij]∈RK×K. 我们有
Q=Tr(E)−∥E∥2F,
若 eij=eji (E 对称):
Q=Tr(E)−∥E∥2F=K∑k=1λk−K∑k=1λ2k,
容易证明, 在 λk=1/K 的时候取得最大值. 即:
eij={1Ki=j0i≠j.
-
换言之, 这个目前会带一点均匀分割的倾向.
Agglomerative Hierarchical Clustering
-
既然如此, 我们可以以这个指标为导向, 每个节点一开始作为独立的类别, 然后逐步地选择能够最大化 Q 的合并方式聚类.
-
假设, 我们要将 Gi,Gj 合并, 则合并前后的 Q 的变化值为:
ΔQ=eii+eij+ejj−(ai+aj)2i∪j−[eii−a2i]i−[ejj−a2j]j=2(eij−aiaj).
Louvain

-
特别地, 在 networkx 的实现以及后续的方法的提及中, 都是引入 resolution γ>0 的指标:
Q=∑i(eii−γ⋅a2i).
γ 越大, 则最后的结果容易产生越多的类, 反之类别数目越少.
-
仅凭此公式可能有点难以理解, 实际上, 我们有:
ΔQ=2(eij−γ⋅aiaj).
显然, ΔQ 是随着 γ 增大而减小的, 因此, 原本可以合并的节点 i,j 可能随着 γ 的增加而导致 ΔQ<0 而不能合并. 合并的机会降低自然会导致最后类别数目的增加.
Modularity-based Graph Clustering
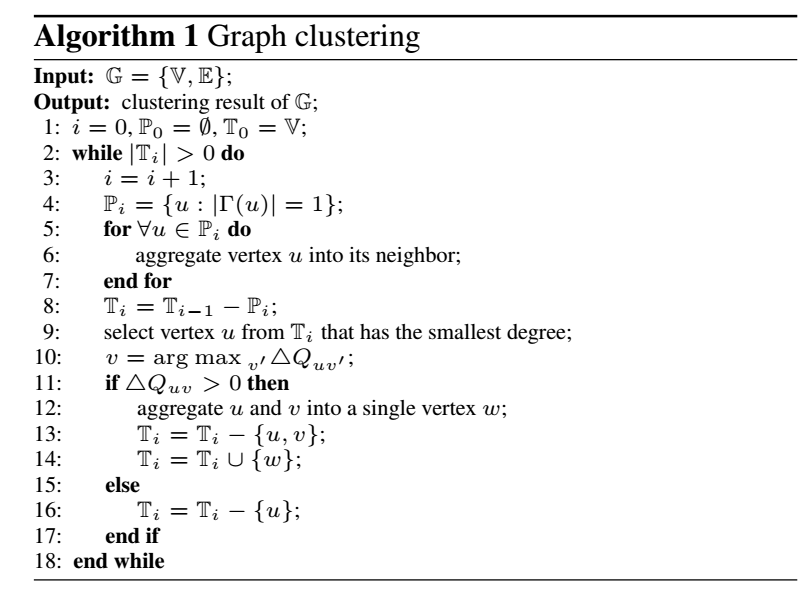
-
这篇文章, 也是直接以 modularity 为目标进行的. 与之前的算法相比, 主要多了一个 pruning 过程.
-
注意到, 每次合并前, 首先统计:
Pi={u:|Γ(u)|=1},
即邻居个数为 1 的节点, 然后直接将这些节点融入他们的邻居之中. 这是因为, 这种情况下:
eij=ai.
注意, 这里 Γ(u):={v∈Ti:(u,v)∈Ei}. 此外, 如果 u 本身是一个 cluster, 那就没法加入到 Pi 中了.
-
另一个有意思的点是, 每一次合并前, 作者挑选的是具有最小 degree 的点, 这确保每次比较的次数是比较少的.
-
另外, 一旦发现 ΔQuv≤0,v=argmaxv′ΔQuv′, 则直接把 u 从 Ti 中剔除. 这是因为 (可以通过归纳法证明), 一旦在某一次出现与周围邻居均有 ΔQuv≤0,v∈Γ(u) 的情况, 即使经过多轮聚类之后, 依然如此.
Rabbit
这个方法的目的是对节点重排序, 使得关系紧密的节点尽可能在一起从而能够降低之后任务的存取的内存开销. 主要是先用之前所说地方法进行聚类, 然后 reording. 特别之处在于, 这个方法是并行处理的, 所以会快很多.


代码
[1] 的代码: NetworkX: girvan_newman
[2] 的代码: NetworkX: greedy_modularity_communities
[3] 的代码: NetworkX: louvain_partitions
[5] 的代码: araji/rabbit_order



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2023-09-20 Relational Knowledge Distillation
2023-09-20 Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System