BAdam: A Memory Efficient Full Parameter Optimization Method for Large Language Models
概
本文介绍了一种 Block corrdinate descent (BCD) 的训练方式.
BAdam
-
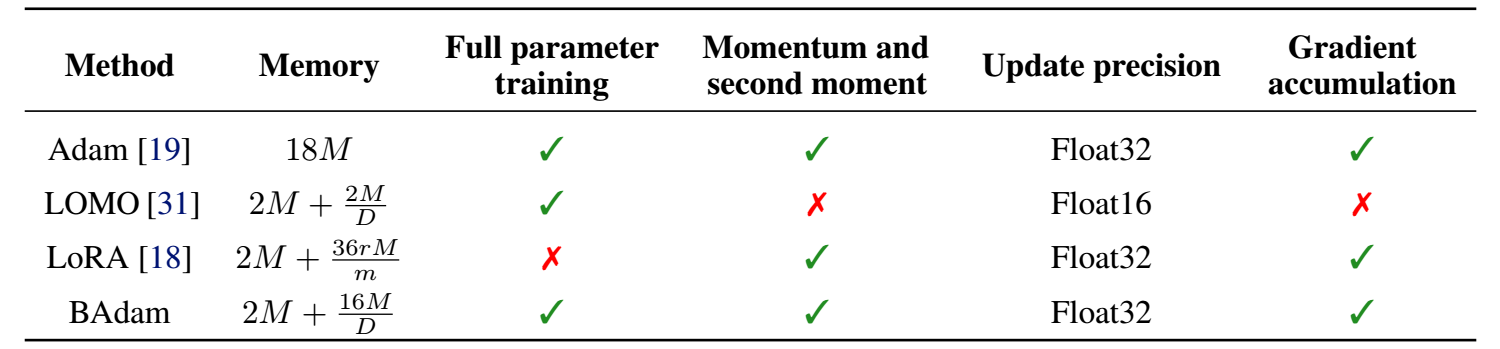
当模型本身很大的时候, 训练它会成为一个很大的问题, 所以现在会流行一些 LoRA 等低质方法用于更快速地更新模型.
-
这个问题其实很大程度上是因为常用地 Adam 至少需要缓存 2x 模型的量, 所以本文提出的 BAdam 就是希望能够每次仅更新其中的一个 block.
-
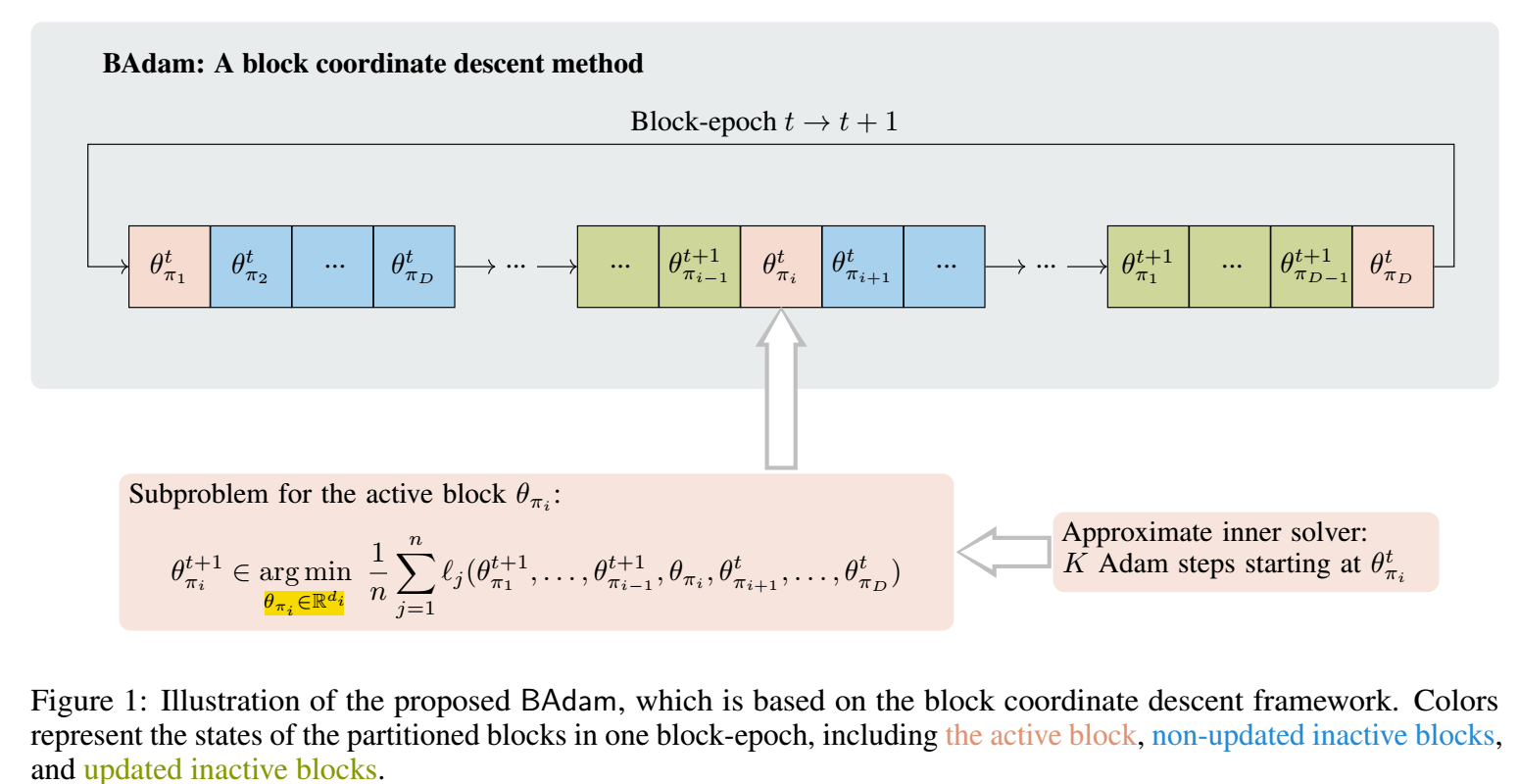
BAdam 将整个模型分成 \(D\) 份: \(\pi_1, \ldots, \pi_i, \ldots, \pi_D\), 并假设其中的参数为 \(\theta = \{\theta_{\pi_1}, \ldots, \theta_{\pi_i}, \ldots, \theta_{\pi_D}\}\).
-
每一次那个更新, 仅更新其中的某一个 block:
\[\theta_{\pi_i}^{t+1} \in \mathop{\text{argmin}} \limits_{\theta_{\pi_i} \in \mathbb{R}^{d_i}} \frac{1}{n} \sum_{j=1}^n \ell_j ( \theta_{\pi_1}^{t+1}, \ldots, \theta_{\pi_{i-1}}^{t+1}, \theta_{\pi_i}, \theta_{\pi_{i+1}}^t, \ldots \theta_{\pi_{D}}^t ). \] -
具体的算法如下, 注意到, 对每个 block 会更新 K 次:

代码
[official]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号