优化与收敛率小记
概
近来对优化和收敛速度有了一些新的感悟, 特此一记. 这些感悟有的来自博客 (如 here), 有的来自书籍. 以往只是套一些收敛的模板, 这里我会讲一下如何从几何的角度去理解这些收敛性.
基本的设定
-
假设我们希望优化:
\[\tag{1} \min_{x \in \mathbb{R}^d} \quad f(x), \]可行域这里就暂不讨论了.
-
我们采取最一般的梯度下降:
\[x_{t+1} = x_t - \eta \nabla f(x), \]其中 \(\eta > 0\) 是学习率, \(\nabla f(x) \in \mathbb{R}^d\) 为 \(f\) 关于 \(x\) 的梯度.
非凸优化
-
基本的条件 (L-smooth):
\[\tag{C.1} f(y) - f(x) - \langle \nabla f(x), y - x \rangle \le \frac{L}{2} \|y - x\|_2^2, \: L > 0 \] -
我们来看看 L-smooth 这个条件实际上为我们带来的是啥:
\[\tag{2} \begin{array}{ll} f(x_{t+1}) - f(x_t) & \le \langle \nabla f(x_t), x_{t+1} - x_t \rangle + \frac{L}{2} \| x_{t+1} - x_t\|_2^2 \\ & = \langle \nabla f(x_t), -\eta \nabla f(x_t) \rangle + \frac{L \eta}{2} \| \nabla f(x_t)\|_2^2 \\ & = \underbrace{(\frac{L \eta^2}{2} - \eta)}_{\alpha_{\eta}} \| \nabla f(x_t)\|_2^2. \end{array} \] -
倘若我们希望收敛速度尽可能快, 那么一个贪心的方法就是每一步的下降都尽可能多, 即我们应当尽可能使得 (3) 的右边项小于 0 的同时进一步变小, 这等价于约束我们的迭代步长:
- 根据 \(\alpha_{\eta}\) 可知, 当 \(\eta = 1 / L\) 的时候近似会有一个'最优'的迭代步长;
- 退而求其次, 我们也应当确保 \(\eta \in (0, 2 / L)\) 以确保\[f(x_{t+1}) < f(x_t). \]
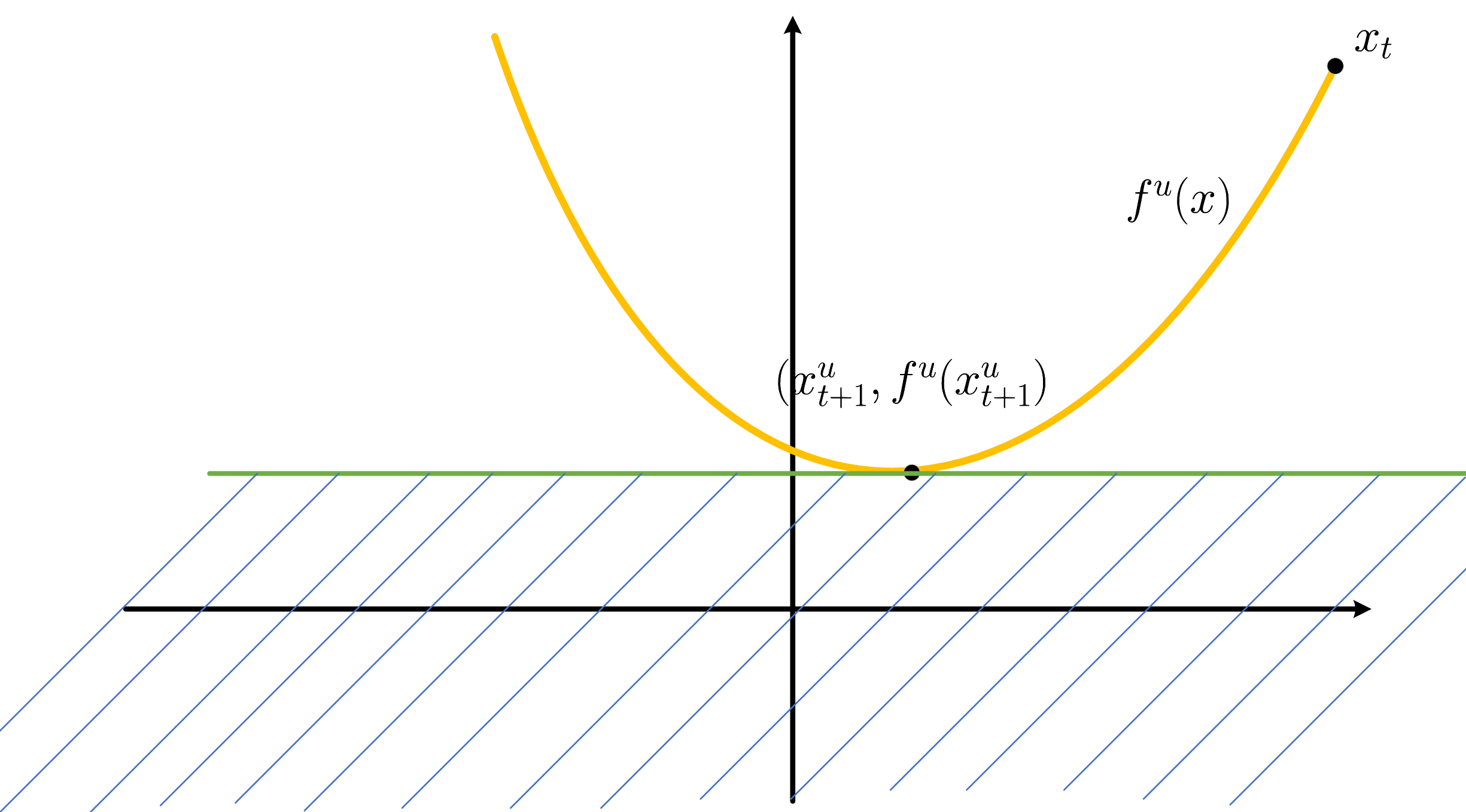
-
我们可以几何上去理解 L-smooth, 定义:
\[f^u(x) = f(x_t) + \langle \nabla f(x_t), x - x_t \rangle + \frac{L}{2} \|x - x_t\|_2^2, \]由于
\[f(x) \le f^u(x) \]故而 L-smooth 实际上是用一个抛物线为 \(f(x)\) 定义了一个上界. 而
\[x_{t+1}^u = x_t - \frac{1}{L} \nabla f(x_t) \]就是这个抛物线的最低点, 所以 \(\eta = 1/L\) 是沿着这条抛物线下降的最优路线.
-
真正的最优点 \((x^*, f(x^*))\) 的区域, 其实是在上图的蓝色画线区域内, 当然了, 由于没有其它条件, 我们既无法 bound 住 \(f(x_t) - f(x^*)\), 更无法 bound 住 \(\|x_t - x^*\|\), 后面当我们引入更多的条件的时候, 我们可以获得更多更好的性质.
-
所以, 我们来证明一个不坏的收敛性:
\[\begin{array}{lll} & f(x_{t+1}) - f(x_t) \le \alpha_{\eta} \| \nabla f(x_t) \|_2^2 \\ \Rightarrow & \sum_{t=0}^{T-1} (f(x_{t+1}) - f(x_t)) \le \alpha_{\eta} \sum_{t=0}^{T-1} \| \nabla f(x_t) \|_2^2 \\ \Rightarrow & \sum_{t=0}^{T-1} \| \nabla f(x_t) \|_2^2 \le \frac{1}{\alpha_{\eta}} \sum_{t=0}^{T-1} (f(x_{t+1}) - f(x_t) ) & \leftarrow \alpha_{\eta} < 0, \text{ if } \eta \in (0, 2 / L) \\ \Rightarrow & \mathop{\min} \limits_{t=0, \ldots, T-1} \|\nabla f(x_t)\|_2^2 \le \frac{1}{T} \sum_{t=0}^{T-1} \| \nabla f(x_t) \|_2^2 \le \frac{1}{\alpha_{\eta} T} \sum_{t=0}^{T-1} (f(x_{t+1}) - f(x_t)) \\ \Rightarrow & \mathop{\min} \limits_{t=0, \ldots, T-1} \|\nabla f(x_t)\|_2^2 \le \frac{1}{-\alpha_{\eta} T} (f(x_0) - f(x_T)) \le \frac{1}{-\alpha_{\eta} T} (f(x_0) - f(x^*)) \\ \Rightarrow & \mathop{\min} \limits_{t=0, \ldots, T-1} \|\nabla f(x_t)\|_2^2 \le \frac{2}{(2 \eta - L \eta^2) T} (f(x_0) - f(x^*)). \end{array} \]当 \(\eta\) 取 \(1 / L\), 左边项可以被
\[\mathcal{O}(\frac{2L}{T}) \]bound 住.
凸优化
- 除了 L-smooth 条件 (C.1) 外, 凸优化额外引入:\[\tag{C.2} f(y) \ge f(x) + \langle \nabla f(x), y - x \rangle. \]

-
它的用处是什么呢? 我们依旧通过几何的方式去理解:
\[f^l(x) \le f(x) \le f^u(x), \]其中
\[f^l(x) := f(x_t) + \langle \nabla f(x_t), x - x_t \rangle. \] -
相比较普通的 L-smooth 而言, 凸优化实际上是为函数 \(f(x)\) 设定了一个下界, 这使得 \((x^*, f(x^*))\) 所在的区域 (蓝色划线部分) 进一步缩小.
-
首先, 对于一般的函数, 我们都有:
\[\begin{array}{ll} \|x_{t+1} - x^*\|_2^2 & = \|x_{t} - \eta \nabla f(x_t) - x^*\|_2^2 \\ & = \|x_{t} - x^*\|_2^2 - 2\eta \underbrace{\langle \nabla f(x_t), x_t - x^*}_{f^l(x_t) - f^l(x^*)} \rangle + \eta^2 \|\nabla f(x_t) \|_2^2, \end{array} \]于是:
\[f^l(x_t) - f^l(x^*) = \frac{\eta}{2} \|\nabla f(x_t) \|_2^2 + \frac{1}{2\eta} \Big( \|x_t - x^*\|_2^2 - \|x_{t+1} - x^*\|_2^2 \Big). \]
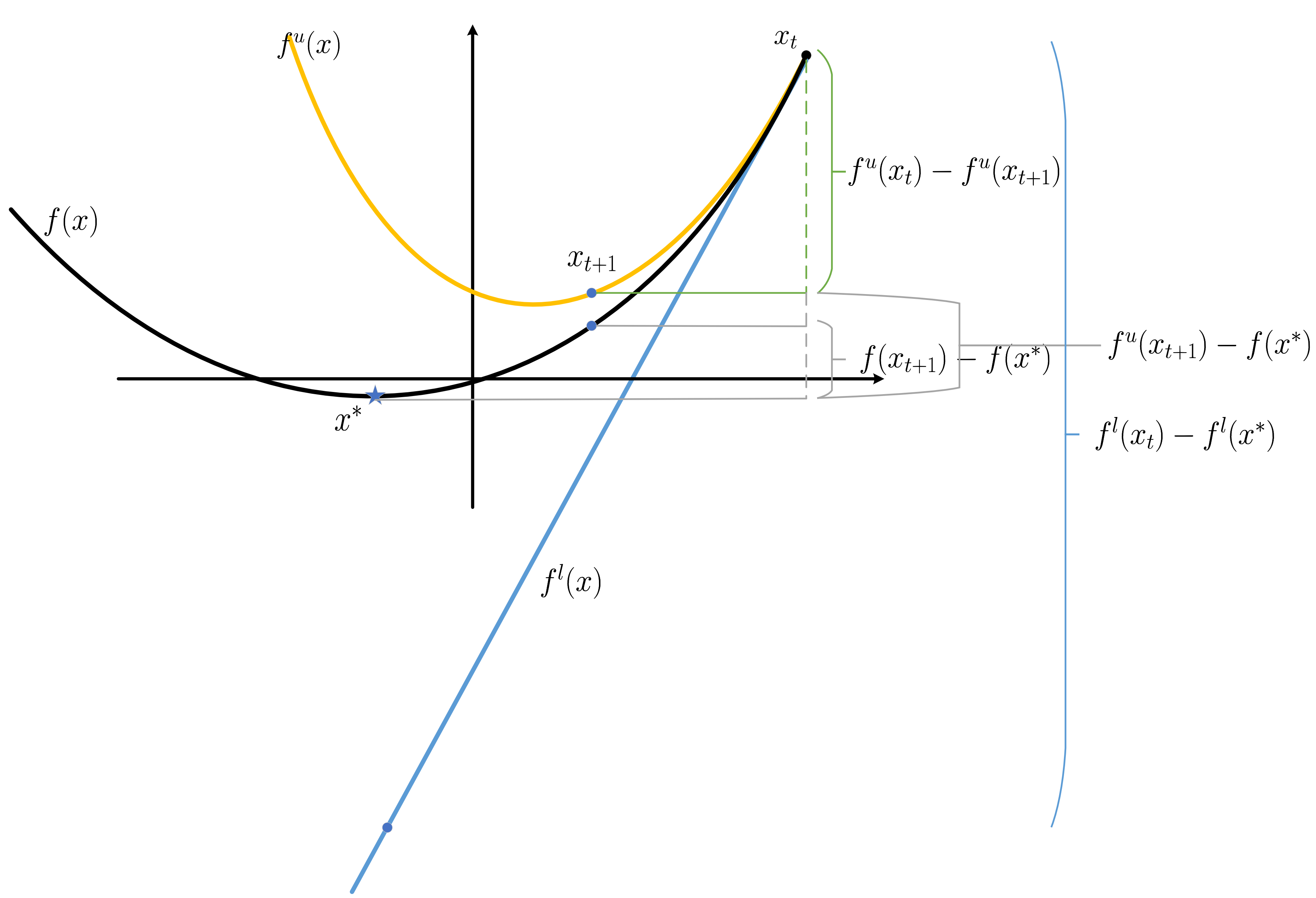
- 于是, 我们有:\[\begin{array}{ll} f(x_{t+1}) - f(x^*) & \le f^u(x_{t+1}) - f(x^*) \\ & = (f^l(x_t) - f(x^*)) - (f^l(x_t) - f^u(x_{t+1})) \\ & \le (f^l(x_t) - f^l(x^*)) - (f^u(x_t) - f^u(x_{t+1})) \\ & = (f^l(x_t) - f^l(x^*)) + \alpha_{\eta} \|\nabla f(x_t)\|_2^2 \\ & \le \frac{1}{2\eta} \Big( \|x_t - x^*\|_2^2 - \|x_{t+1} - x^*\|_2^2 \Big) + (\alpha_{\eta} + \frac{\eta}{2}) \|\nabla f(x_t) \|_2^2 \end{array} \]当我们假定 \(\eta \in (0, 1/L)\), 有 \(\alpha_{\eta} + \frac{\eta}{2} < 0\) 可得\[\begin{array}{ll} & f(x_{t+1}) - f(x^*) \le \frac{1}{2\eta} \Big( \|x_t - x^*\|_2^2 - \|x_{t+1} - x^*\|_2^2 \Big) \\ \Rightarrow & \sum_{t=1}^{T-1} f(x_{t+1}) - f(x^*) \le \frac{1}{2\eta} \Big( \|x_{0} - x^*\|_2^2 - \|x_{T} - x^*\|_2^2 \Big) \\ \Rightarrow & \frac{1}{T} \sum_{t=1}^{T-1} f(x_{t+1}) - f(x^*) \le \frac{1}{2\eta T} \Big( \|x_{0} - x^*\|_2^2 - \|x_{T} - x^*\|_2^2 \Big) \\ \Rightarrow & f(x_{t+1}) - f(x^*) \le \frac{1}{T} \sum_{t=1}^{T-1} f(x_{t+1}) - f(x^*) \le \frac{1}{2\eta T} \Big( \|x_{0} - x^*\|_2^2 - \|x_{T} - x^*\|_2^2 \Big) \\ \Rightarrow & f(x_{t+1}) - f(x^*) \le \frac{1}{2\eta T} \Big( \|x_{0} - x^*\|_2^2 - \|x_{T} - x^*\|_2^2 \Big) \le \frac{\|x_0 - x^*\|_2^2}{2\eta T}. \end{array} \]倒数第二步成立是因为 \(f(x_{t}), t=0, \ldots\) 是递减的 (\(\eta \in (0, 1 / L)\) 保证了这一点).
强凸优化
- 强凸函数是 (C.2+) 的一个增强版:\[\tag{C.2+} \frac{\sigma}{2} \|y - x\|_2^2 \le f(y) - f(x) - \langle \nabla f(x), y - x \rangle, \quad \sigma > 0. \]
注: \(\sigma = 0\) 时 \(f\) 为凸函数.
-
实际上, 若 \(f\) 的 Hessian 矩阵满足 \(\sigma \le \lambda_{\min}(H) \le \lambda_{\max} (H) \le L\), 就可以很自然地推导出上面的不等式. 于是乎, 我们常常会听闻条件数 \(\kappa = L / \sigma\) 对于收敛速率的影响, 通常 \(\kappa \rightarrow 1\) 收敛速度越快.
-
现在的问题是, L-smooth 这个条件 (C.1) 能够保证我们每一次迭代都有 \(f(x_{t+1}) < f(x_t)\), 那 (C.2) 这种对于左边的控制于收敛有什么帮助?
\[\begin{array}{ll} f(x_{t+1}) - f(x_t) & \ge \langle \nabla f(x_t), x_{t+1} - x_t \rangle + \frac{\sigma}{2} \|x_{t+1} - x_t \|_2^2 \\ & \ge \langle \nabla f(x_t), -\eta \nabla f(x_t) \rangle + \frac{\sigma \eta^2}{2} \|\nabla f(x_t)\|_2^2 \\ & \ge \underbrace{(\frac{\sigma \eta^2}{2} - \eta)}_{\beta_{\eta}} \|\nabla f(x_t)\|_2^2. \end{array} \]
注: \(\eta \in (0, 2 / \sigma) \supset (0, 2 / L)\) 能够保证 \(\beta_{\eta}\) 是负的.
-
于是, 我们可以证明:
\[\underbrace{(\frac{\sigma \eta^2}{2} - \eta)}_{\beta_{\eta}} \|\nabla f(x_t)\|_2^2 \le f(x_{t+1}) - f(x_t) \le \underbrace{(\frac{L \eta^2}{2} - \eta)}_{\alpha_{\eta}} \| \nabla f(x_t)\|_2^2. \] -
倘若, 我们沿着之前的思路分析, 容易发现 \(\beta_{\eta}\) 会随着 \(\sigma \rightarrow L\) 而增大 (绝对值 \(|\beta_{\eta}|\) 减小), 也就是说, 当 \(\sigma \Rightarrow\) 的时候,
\[f(x_{t+1}) - f(x_t) \]的下降的最大可能幅度是在减小的. 这实在不符合我们的预期, 如果按照这种思路分析, 正当的结论应该是 \(\sigma \rightarrow L\) 收敛性变差才对.
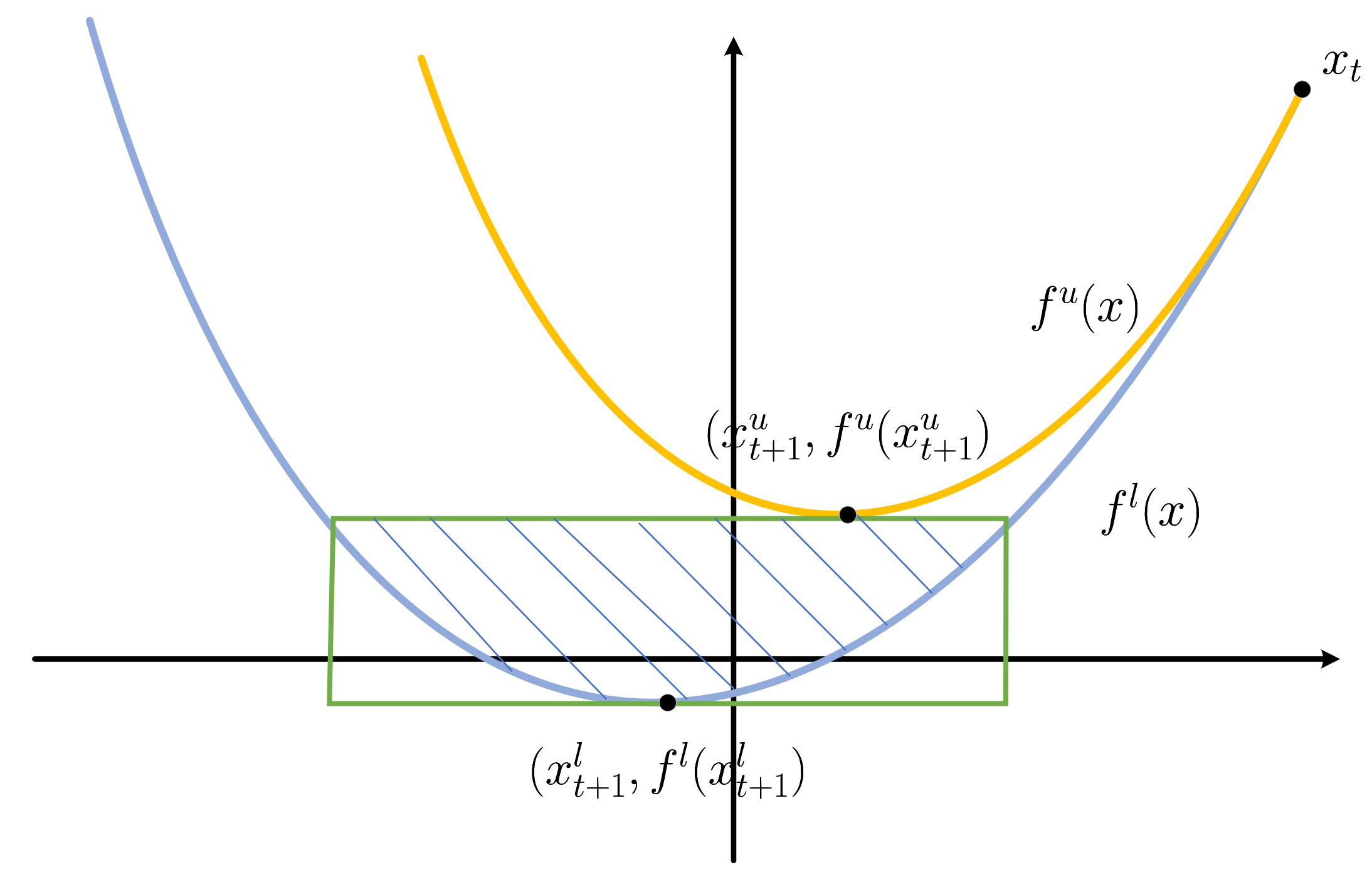
-
这里, 我们修改下之前 \(f^l\) 的定义:
\[f^u(x) = f(x_t) + \langle \nabla f(x_t), x - x_t \rangle + \frac{L}{2} \|x - x_t\|_2^2, \\ f^l(x) = f(x_t) + \langle \nabla f(x_t), x - x_t \rangle + \frac{\sigma}{2} \|x - x_t\|_2^2. \]我们有:
- \(f^l(x) \le f(x) \le f^u(x)\), 所以最小值点 \(x^*\) 比在二者的中间区域;
- 我们可以进一步压缩 \((x^*, f(x^*))\) 可能的所在区域, 实际上在上图的绿色框框内部 (更准确的是画线区域):\[f^l(x_{t+1}^l) \le f(x^*) \le f^u(x_{t+1}^u), \\ x_{t+1}^l = x_t - \frac{1}{\sigma}\nabla f(x_t) \Rightarrow f(x_{t+1}^l) = f(x_t) - \frac{1}{2\sigma} \|\nabla f(x_t)\|_2^2, \\ x_{t+1}^u = x_t - \frac{1}{L}\nabla f(x_t) \Rightarrow f(x_{t+1}^u) = f(x_t) - \frac{1}{2 L} \|\nabla f(x_t)\|_2^2. \]此外, \(x^*\) 所在区域为:\[x^* \in \bigg\{ x \in \mathbb{R}^d : \| x - x_t + \frac{1}{\sigma} \nabla f(x_t)\|_2^2 \le \frac{L - \sigma}{L\sigma^2} \|\nabla f(x_t)\|_2^2 \bigg\} =: \mathcal{S}_t. \]这是以 \(x_t - \frac{1}{\sigma} \nabla f(x_t)\) 为圆心, \(\sqrt{\frac{L - \sigma}{L\sigma^2}} \|\nabla f(x_t)\|_2\) 为半径的球内.
- 由此, 我们可以进一步得到 \((x_t, f(x_t))\) 与 \((x^*, f(x^*))\) 的关系:\[\frac{1}{2L} \|\nabla f(x_t)\|_2^2 \le f(x_{t}) - f(x^*) \le \frac{1}{2\sigma} \|\nabla f(x_t) \|_2^2, \\ \frac{1}{\sigma} \Big(1 - \sqrt{\frac{L - \sigma}{L}} \Big) \| \nabla f(x_t)\|_2 \le \|x_t - x^*\|_2 \le \frac{1}{\sigma} \Big(1 + \sqrt{\frac{L - \sigma}{L}} \Big) \| \nabla f(x_t)\|_2, \]所以, 当 \(\sigma \rightarrow L\) 的时候, \(f(x_t) - f(x^*)\) 可容易接近, 同时 \(x_t\) 与 \(x^*\) 的距离可能越小.
-
总而言之, \(\sigma > 0\) 的作用其实是告诉我们这个强凸函数的 \((x^*, f(x^*))\) 可以被限制在一个区域里面, 倘若 \(\sigma = 0\), 实际上 \(f^u\) 的之下的区域都是有可能, 自然就不会有上述的性质, 自然收敛性会差一点.
-
ok, 接下来, 让我们具体地证明一下收敛性, 令 \(\eta \in (0, 1/L)\), 于是我们有 (根据图示了然):
\[\begin{array}{ll} & f(x_{t+1}) - f(x_t) \le \alpha_{\eta} \|\nabla f(x_t) \|_2^2 \\ \Leftrightarrow & f(x_{t+1}) - f(x^*) \le f(x_{t}) - f(x^*) + \alpha_{\eta} \|\nabla f(x_t) \|_2^2 \\ \Leftrightarrow & f(x_{t+1}) - f(x^*) \le f(x_{t}) - f(x^*) + 2 \alpha_{\eta} \sigma (f(x_t) - f(x^*)) \\ \Leftrightarrow & f(x_{t+1}) - f(x^*) \le (1 + 2 \alpha_{\eta} \sigma) (f(x_t) - f(x^*)) \\ \Leftrightarrow & f(x_{T}) - f(x^*) \le (1 + 2 \alpha_{\eta} \sigma)^T (f(x_0) - f(x^*)) \\ \Leftrightarrow & f(x_{T}) - f(x^*) \le (1 + \sigma(L\eta^2 - \eta))^T (f(x_0) - f(x^*)). \end{array} \]由于 \(1 + \sigma(L\eta^2 - \eta) < 1\), 我们便证明了收敛性 (而且是很强的收敛性).
注: 我们也可以模仿凸优化里的收敛性证明来证明一个稍差的收敛性:
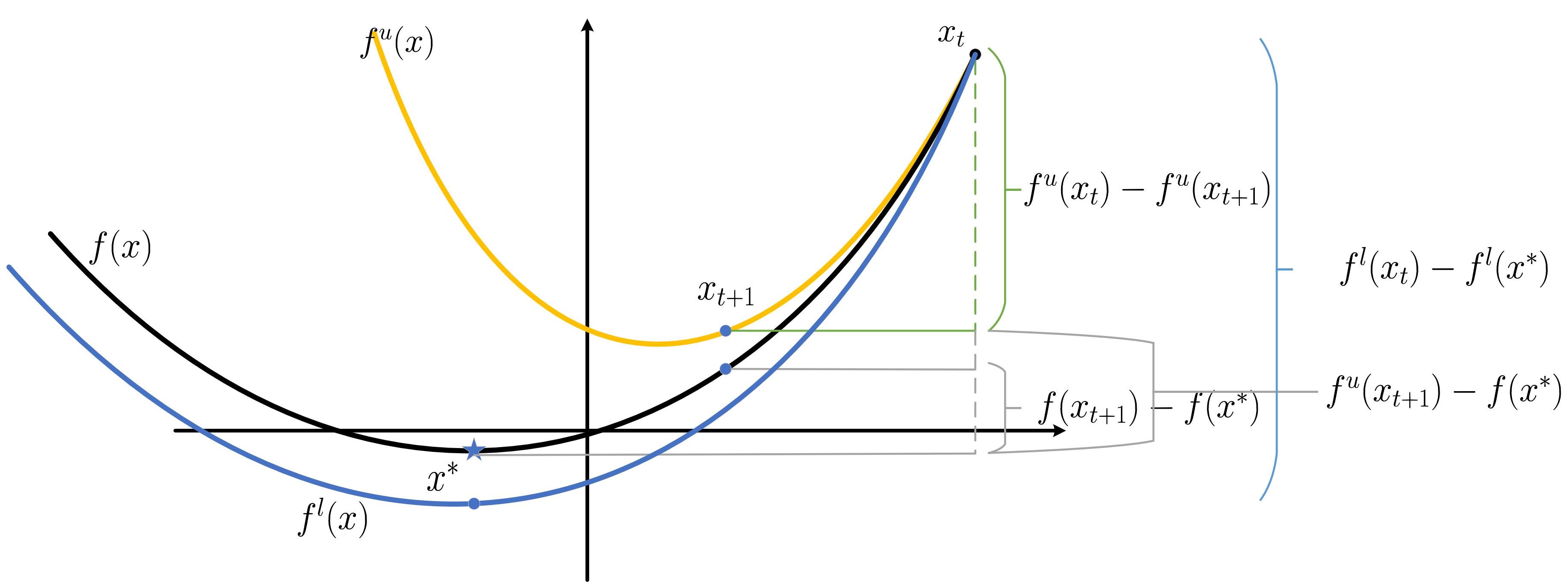
-
可以发现:
\[\begin{array}{ll} f(x_{t+1}) - f(x^*) & \le f^u(x_{t+1}) - f(x^*) \\ & = (f^l(x_t) - f(x^*)) - (f^l(x_t) - f^u(x_{t+1})) \\ & \le (f^l(x_t) - f^l(x^*)) - (f^u(x_t) - f^u(x_{t+1})) \\ & = (f^l(x_t) - f^l(x^*)) + \alpha_{\eta} \|\nabla f(x_t)\|_2^2 \\ & \le \frac{1}{2\eta} \Big( \|x_t - x^*\|_2^2 - \|x_{t+1} - x^*\|_2^2 \Big) - \frac{\sigma}{2} \|x_t - x^*\|_2^2 + (\alpha_{\eta} + \frac{\eta}{2}) \|\nabla f(x_t) \|_2^2 \end{array} \]其中, 最后一步略有不同之处, 因为这里 \(f^l\) 是原来的直线加上一个二次项.
-
于是, 当 \(\eta_t \le \frac{1}{t\sigma}\) 且 \(\eta_t < 2 / L\) 时我们有:
\[\begin{array}{ll} & f(x_{t+1}) - f(x^*) \le \underbrace{ \frac{1}{2\eta_t} \Big( \|x_t - x^*\|_2^2 - \|x_{t+1} - x^*\|_2^2 \Big) - \frac{\sigma}{2} \|x_t - x^*\|_2^2 }_{\le 0} + (\alpha_{\eta_t} + \frac{\eta_t}{2}) \|\nabla f(x_t) \|_2^2 \\ \Rightarrow & f(x_{t+1}) - f(x^*) \le (\alpha_{\eta_t} + \frac{\eta_t}{2}) \|\nabla f(x_t) \|_2^2 \\ \Rightarrow & f(x_{t+1}) - f(x^*) \le \frac{\eta_t}{2} \|\nabla f(x_t) \|_2^2 \\ \Rightarrow & \sum_{t=1}^{T} (f(x_{t+1}) - f(x^*)) \le \sum_{t=1}^{T} \frac{\eta_t}{2} \|\nabla f(x_t) \|_2^2 \\ \Rightarrow & \sum_{t=1}^{T} (f(x_{t+1}) - f(x^*)) \le \sum_{t=1}^{T} \frac{\eta_t L}{2} \\ \Rightarrow & \sum_{t=1}^{T} (f(x_{t+1}) - f(x^*)) \le \frac{L}{2\sigma} \sum_{t=1}^{T} \frac{1}{t} \\ \Rightarrow & \sum_{t=1}^{T} (f(x_{t+1}) - f(x^*)) \le \frac{L}{2\sigma} (1 + \ln T) \\ \Rightarrow & f(x_{T+1}) - f(x^*) \le \frac{1}{T}\sum_{t=1}^{T} (f(x_{t+1}) - f(x^*)) \le \frac{L}{2\sigma} \frac{(1 + \ln T)}{T}. \end{array} \] -
在特殊的情况下 (\(\sigma / L > 8 / 9\)), 我们可以证明, \(\|x_t -x^*\|_2\) 也是单调下降的:
\[\begin{array}{lll} \|x_{t+1} - x^*\|_2 & \le 2 \frac{1}{\sigma} \sqrt{\frac{L - \sigma}{L}} \|\nabla f(x_t)\|_2 & \leftarrow x_{t+1} \in \mathcal{S}_t \\ & \le 2 \frac{1}{\sigma} \sqrt{\frac{L - \sigma}{L}} \frac{\sigma}{1 - \sqrt{\frac{L-\sigma}{L}}} \|x_t - x^*\|_2 & \leftarrow x^* \in \mathcal{S}_t \\ & = 2 \frac{1}{\sqrt{\frac{L}{L - \sigma}} - 1} \|x_t - x^*\|_2 < \|x_t -x^*\|_2 & \leftarrow \sigma / L > 8 / 9 \end{array}. \]这也进一步说明了 \(\sigma \rightarrow L\) 的重要性.
注: 我本来想证明一般情况下也有这个性质来着, 但是似乎是困难的, 因为仅凭画图我们就可以做出 \(x^*\) 位于 \(x_{t}, x_{t+1}\) 之间的情况. 所以我感觉除非上述条件成立 (即区域非常小), 不然很难保证 \(\|x_t - x^*\|_2\) 是恒下降的. 当然了, 或许我们能够通过约束 \(x_{t+1}\) 的范围来保证这一点. 比如, 我们取
此时 \(x_{t+1}\) 恰在 \(x_t\) 在 \(\mathcal{S}_t\) 的投影上, 所以必有:
但是, 想要设计一个算法近似这种应该是很难的吧.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号