AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients
概
本文提出了一种 Adam 优化器上的改进, 能够更加有效地设计步长.
AdaBelief

-
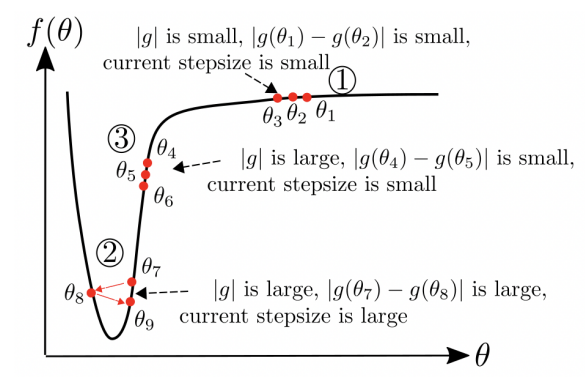
AdaBelief 的初衷很简单, 如上图所示, 据此我们分析三种情况下的合理步长.
-
对于第一种情况, 梯度 \(|g|\) 很小, 此时理想的 optimizer 理应给予一个较大的步长, Adam 的确有能力做到这一点 (估计的方差比较小);
-
对于第二种情况, 梯度 \(|g|\) 很大, 且位于极小值附近, 理应设置一个较小的步长, Adam 也有能力做到这一点 (此时估计的方差比较大);
-
对于第三种情况, 梯度 \(|g|\) 很大, 但是此时可以设置一个较大的步长, 但是实际上 Adam 依然给予一个较小的步长. 由于前后梯度差异很大, 所以 AdaBelief 实际上依然可以给予一个较大的步长.
注: 根据 github 的 issue 里, 有人发现 \(\epsilon\) 对于替代 SGD 的一个重要性, 注意到, 当 \(\epsilon\) 足够大的时候, \(s_t\) 后面会收敛到相同的值, 此时 AdaBelief 的表现就和 SGD 类似了. 所以这也可能是为什么 AdaBelief 也能够在 CV 上取得比较好的结果原因之一.
注: 我不是很清楚 Update
\[\theta_{t} \leftarrow \prod_{\mathcal{F}, \ldots} (\cdots)
\]
是怎么来的, 好像和 online learning 有点关系.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号