An Attentive Inductive Bias for Sequential Recommendation beyond the Self-Attention
概
本文在 attention block 中引入高低频滤波.
符号说明
-
, users;
-
, items;
-
, sequence;
-
, sequence embeddings;
-
attention matrix:
-
, 维 DFT (Discrete Fourier Transform) 的第 个基底, 这里 表示 imaginary unit.
BSARec (Beyond Self-Attention for Sequential Recommendation)
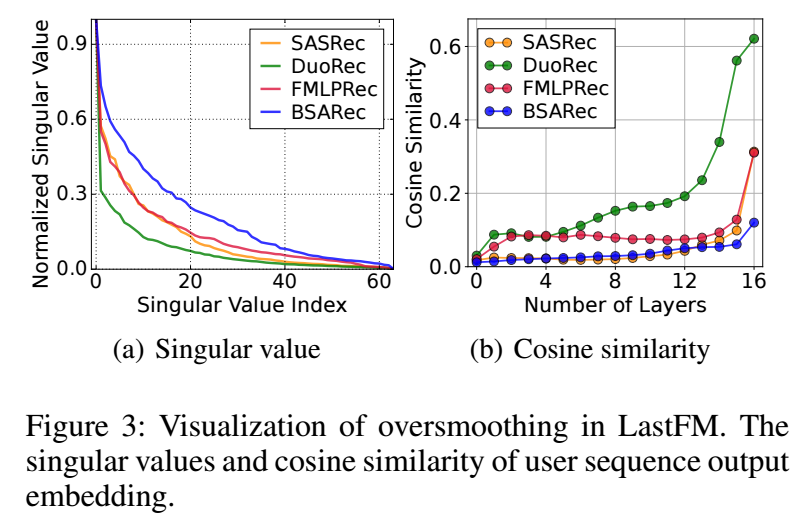
-
首先, 作者对一般的序列推荐模型如 SASRec, FMLPRec 的演进过程中的 embedding 的奇异值变化和 user embedding 的 cosine similarity 进行比较, 可以发现 embedding 主特征值的主导地位相当明显, 而且随着层数的加深, 越发变得相似. 故而, 作者得出结论, 认为现在的主流的序列推荐模型主要是在学习一个 low-pass 的滤波.
-
令 DFT 的基底矩阵为 , 对于任意的向量 我们可以得到它的频域上的表示
并令 表示 的最低频位置的 个元素, 表示 的最高频位置的 个元素.
-
由此, 我们可以通过 Inverse DFT 得到
- 的低频信号:
- 的高频信号:
- 的低频信号:
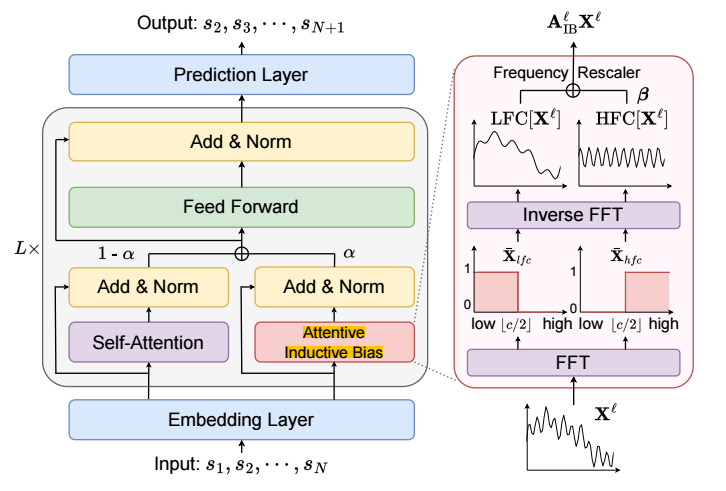
- 令 表示第 层的输入, 则 attention 后的结果为其中 对应正常的 attention 机制, 而 则其中 是可训练的参数, 它可以是每个维度设置一个, 也可以不同维度共享一个 (代码里的是这种方案).
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2023-07-07 Memory Augmented Graph Neural Networks for Sequential Recommendation
2022-07-07 A Framework for Understanding Sources of Harm throughout the Machine Learning Life Cycle