Structure-Aware Transformer for Graph Representation Learning
概
Graph + Transformer + 修改 attention 机制.
SAT
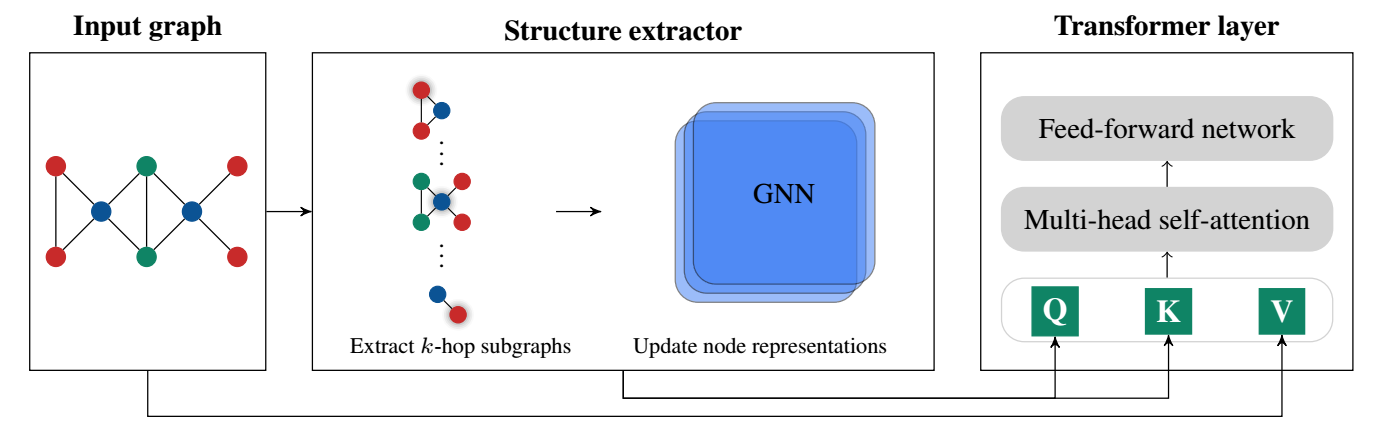
-
Transformer 最重要的就是 attention 机制:
\[\text{Attn}(x_v) = \sum_{ v \in V } \frac{ \kappa_{\text{exp}} (x_v, x_u) }{ \sum_{w \in V} \kappa_{\text{exp}} (x_v, x_w) } f(x_u), \: \forall v \in V, \]其中
\[\kappa_{\text{exp}}(x, x') := \exp\big( \langle \mathbf{W}_Q x, \mathbf{W}_K x' \rangle / \sqrt{d_{out}} \big). \] -
作者希望让 attention 的计算是 structure-aware 的:
\[\text{SA-attn}(v) := \sum_{v \in V} \frac{ \kappa_{\text{graph}} (S_{G} (v), S_{G} (u)) }{ \sum_{w \in V} \kappa_{\text{graph}} ( S_G(v), S_G(w) ) } f(x_u) \]这里 \(S_G(u)\) 表示以 \(u\) 为中心的 \(k\)-hop 子图, \(\kappa_{\text{graph}}\) 是衡量两个图相似度的 kernel, 可以通过过往的图实现.
-
最后, 在完成 attention 后, skip connection:
\[x_v' = x_v + 1 / \sqrt{d_v} \text{SA-attn}(v). \]这里 \(d_v\) 是结点 \(v\) 的度数, 为了避免度数高的结点占据主导.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号