Visual Instruction Tuning
Liu H., Li C., Wu Q. and Lee Y. J. Visual Instruction Tuning. NeurIPS, 2023.
概
LLaVA.
LLaVA
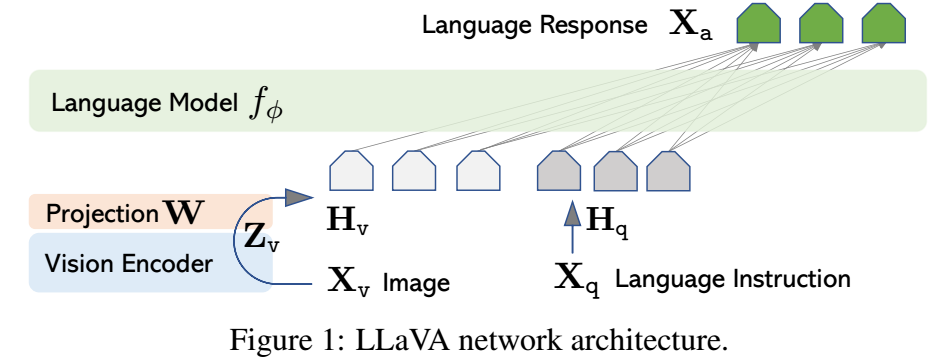
-
LLaVA 希望用 LLM 推理模态特征, 想法很简单:
- 用 Vision Encoder 得到模态特征:
- 用 Linear 投影:
- 把 和指令 凭借起来作为 LLM 的输入.
- 用 Vision Encoder 得到模态特征:
-
训练的 Instruct 是这么构造的: , 对于每个图片都有 轮的对话数据 (question, answer). 然后
即就第一次的时候加一个图片 (可以是图片在前, 也可以是指令在前, 这比较符合实际的使用习惯).
-
Pre-training: 预训练的时候固定 Vision encoder 和 LLM, 之训练 projecter:
-
Fine-tuning: 固定 Vision encoder, 微调 LLM 和 projecter, 在一些 QA 数据集上微调.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2022-06-14 Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System
2021-06-14 SMOOTHING (LOWPASS) SPATIAL FILTERS
2021-06-14 Data Augmentation
2021-06-14 TriggerBN ++