HiPPO: Recurrent Memory with Optimal Polynomial Projections
概
看下最近很火的 Mamba 的前身. 本文其实主要介绍的是一个如何建模历史信息在正交基上的稀疏的变化情况.
Motivation
-
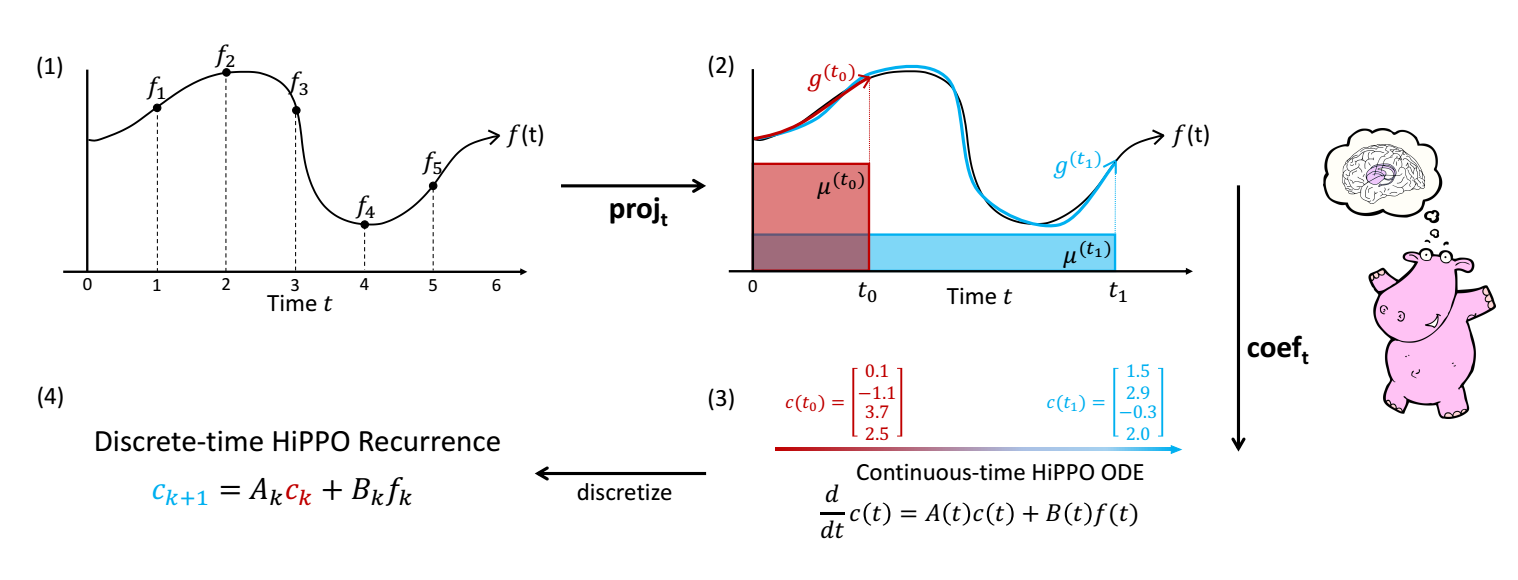
对于一个函数 \(f(t) \in \mathbb{R}\) (如上图 (1)), 我们希望找到一个东西去记忆它. 需要注意的是, 我这里用的词是 '记忆' 而不是 '建模'. 这二者有些相似, 但是侧重点不一样:
- 建模: 如果是一个建模问题, 那大概的思路就是通过一个模型 (如神经网络) 去拟合 \(f(t)\), 故而往往是一个 \(f(t)\) 一个模型;
- 记忆: 给定过去的序列 \(f_1, f_2, \ldots\), 通过某种方式去 '压缩' 它. 毫无疑问, 最直接的记忆手段就是把过去的历史全部存起来, 但是其实这种方式或许是不那么优雅的 (当然这种方式也有成功的例子, 如 transformer). 故而 记忆 是动态的, 一个模型是可以应对多个 \(f(t)\) 的.
-
下面我们先把视角放到连续的版本上去, 后面在介绍如何离散化. 故我们现在的目标是: **通过有限的单元去记忆 \(f_{\le t} := f(x)|_{x\le t}\).
-
作者的思想其实很简单, 把 \(f_{\le t}\) 投影到 \(N\) 个正交基 \(P_k^{(t)}, k=0,1,\ldots, N-1\) 上, 然后保存在其上的系数:
\[c_k(t) = \langle f_{\le t}, P_k^{(t)} \rangle_{\mu^{(t)}}, \quad k=0, 1, \ldots, N-1. \] -
其实我认为作者做出的最大的贡献就是正交基 \(P_k^{(t)}\) 随着时间 \(t\) 有规律的变化, 测度 \(\mu^{(t)}\) 随着时间 \(t\) 有规律的变化.
-
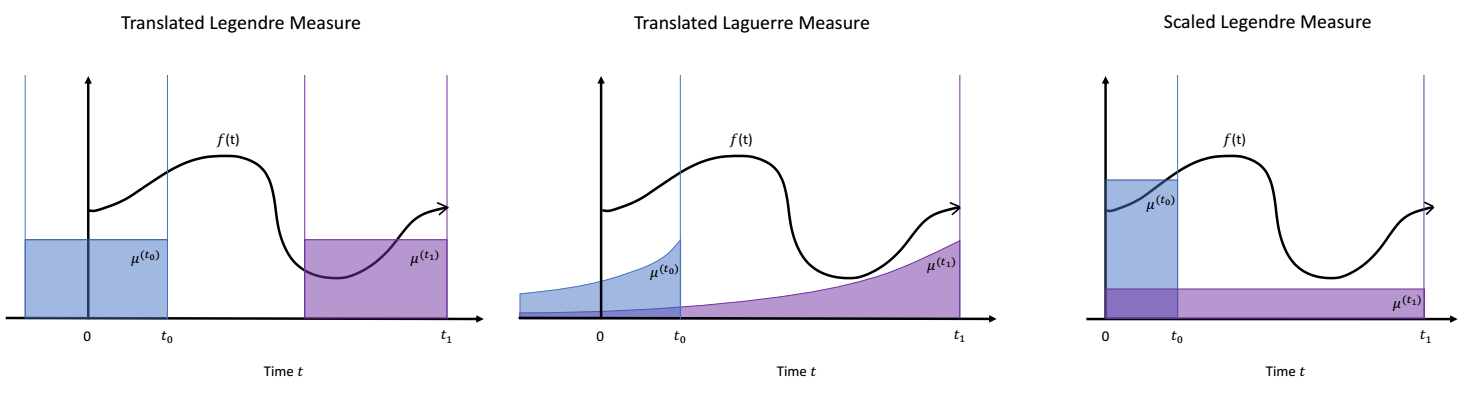
让我们来先理解测度 \(\mu^{(t)}\) 的含义, 我们可以把它简单理解成一个概率分布, 我们假设 \(w(t, x)\) 为它的密度函数, 通过它可以描述过去时刻的重要性:
- 短期均匀记忆 (Translated Legendre Measure):\[w(t, x) = \frac{1}{\theta} \mathbb{I}_{[t - \theta, t]}(x). \]它对过去 \(\theta\) 时间段赋予了相同的权重;
- 指数衰减记忆 (Translated Laguerre Measure):\[w(t, x) = \left \{ \begin{array}{ll} (t - x)^{\alpha} e^{x - t} & \text{if } x \le t, \\ 0 & \text{if } x > t. \end{array} \right. \]越久远的记忆, 衰减的越厉害, 它有一个问题, \(x < 0\) 的时候它也会有权重.
- 长期均匀记忆 (Scaled Legendre Measure):\[w(t, x) = \frac{1}{t} \mathbb{I}_{[0, t]}. \]对过去的记忆统一进行均匀记忆.
- 短期均匀记忆 (Translated Legendre Measure):
-
故, HiPPO 可以通过设计不同的测度 \(\mu^{(t)}\) 来反映不同的记忆方式, 虽然指数衰减记忆直觉上更符合, 但是实际中长期均匀记忆作者更为推荐.
-
到此, 问题其实依旧非常严峻, \(c_k(t)\) 的表达式其实是比较困难 (对于我来说), 牛逼的是, 作者证明了对于上述的三种记忆方式, 大体上可以统一表示为:
\[\tag{1} \frac{d}{d t} c(t) =Ac(t) + B f(t), \\ c(t) = [c_0(t), c_1(t), \ldots, c_{N-1}(t)]^T, \quad A \in \mathbb{R}^{N \times N}, \quad B \in \mathbb{R}^{N \times 1}. \] -
实际上 (1) 就定义了 \(c(t)\) 的变化过程, 描绘了测度 \(\mu^{(t)}\) 下最优的一种压缩模式. 我们可以通过一些离散方法来近似这个 ODE. Generalized Bilinear Transformation (GBT):
-
(1) 等价于
\[c(t + \Delta t) - c(t) = \int_t^{t + \Delta t} Ac(s) + B f(s) \mathrm{d}s; \] -
(2) 取近似点为 \((1 - \alpha) [Ac(t) + Bf(t)] + \alpha [Ac(t + \Delta t) + Bf(t + \Delta t)]\), 可得近似:
\[c(t + \Delta t) - c(t) \approx \bigg\{ (1 - \alpha) [Ac(t) + Bf(t)] + \alpha [Ac(t + \Delta t) + Bf(t + \Delta t)] \bigg\} \Delta t, \]可得:
\[\tag{2} c(t + \Delta t) \approx (I - \alpha \Delta t A)^{-1} \bigg\{ \big( I + \Delta t (1 - \alpha)A \big) c(t) + \Delta t B f(t) \bigg\}. \] -
\(\alpha = 0\) 即为 Euler 近似, \(\alpha = 1\) 为 Backward Euler 近似, \(\alpha = 1/2\) 为 Bilinear 近似.
-
-
故而, 我们只需要算出 \(A, B\), 就可以迭代更新 \(c\) 了, 下面直接给出上述三种方式的 \(A, B\):
- 短期均匀记忆 (Translated Legendre Measure):
\[A_{nk} = -\frac{1}{\theta} \left \{ \begin{array}{ll} (-1)^{n-k} (2n + 1) & \text{if } n \ge k, \\ 2n + 1 & \text{if } n \le k. \\ \end{array} \right ., \\ B_n = \frac{1}{\theta}(2n + 1)(-1)^n. \]- 指数衰减记忆 (Translated Laguerre Measure):
\[A_{nk} = \left \{ \begin{array}{ll} -1 & \text{if } n \ge k, \\ 0 & \text{if } n < k, \end{array} \right ., \\ B_n = 1. \]- 长期均匀记忆 (Scaled Legendre Measure): 首先它的形式为:
\[\frac{d}{dt} c(t) = -\frac{1}{t} A c(t) + \frac{1}{t} B f(t), \]其中
\[A_{nk} = \left \{ \begin{array}{ll} (2n + 1)^{1/2} (2k + 1)^{1/2} & \text{if } n > k, \\ n + 1 & \text{if } n = k, \\ 0 & \text{if } n < k. \end{array} \right ., \\ B_n (2n + 1)^{1/2}. \] -
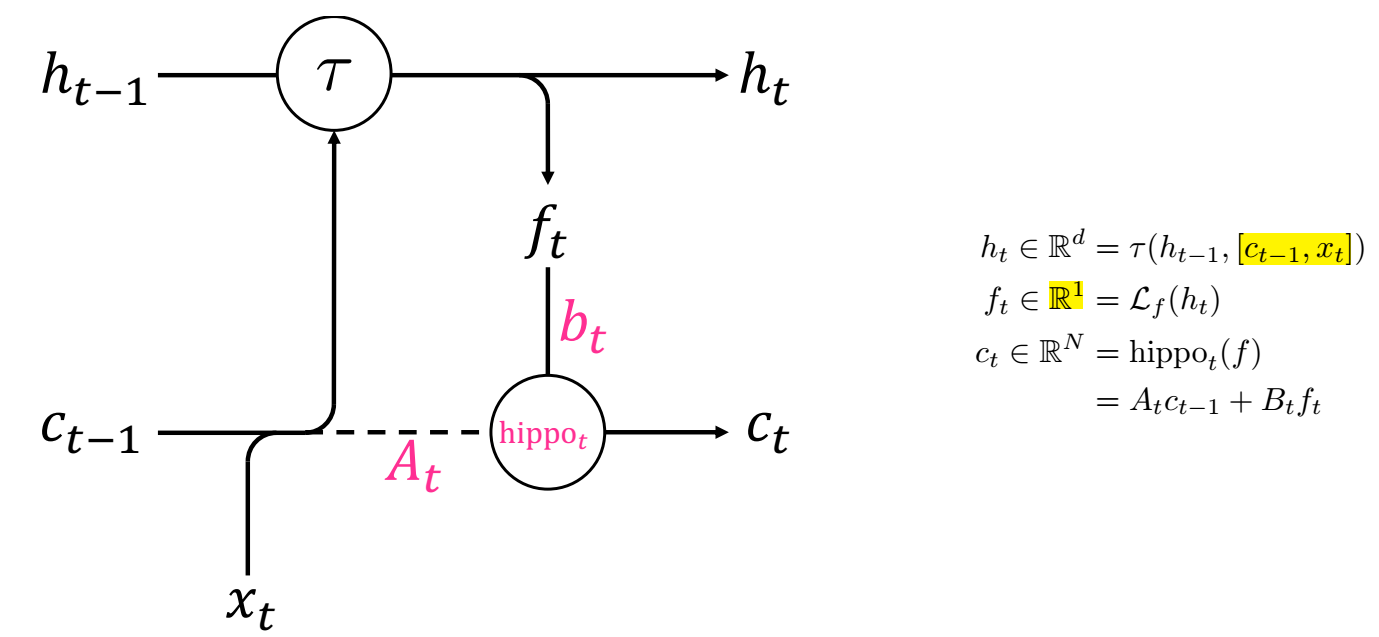
OK, 现在让我们看看如何把这个记忆功能用到 RNN 中:
-
如上图所示, 在更新 RNN 的状态 \(h_t\) 的时候, 除了 \(h_{t-1}, x_t\), 额外把系数 \(c_{t-1}\) 作为输入, 特别的 \(c\) 的信号来源是通过 \(\mathcal{L}_f\) 把 \(h\) 压缩到 1 维实现的. 从这一点来看, 目前的 Hippo 设计的还是比较粗糙的?
-
最后讲一下证明关键点:
- 对于上述的测度, 它的正交基是现成的 (有很好的求导的性质);
- 分布积分的求导和转换 \(\frac{\partial}{\partial t} g_n \rightarrow c_{n-1}, c_{n-3}, \ldots\) 的变换很巧妙.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号