Unlearn What You Want to Forget Efficient Unlearning for LLMs
Chen J. and Yang D. Unlearn what you want to forget: efficient unlearning for llms. 2024.
概
本文提出一种 Unlearning layer 去帮助 LLMs '遗忘' 一些数据.
符号说明
- \(F(\cdot)\), large language model (LLM):
- \(F'(\cdot)\), updated model;
- \(D = \{(x, y)\}\), training dataset;
- \(D^f = \{(x^f, y^f)\}\), data to be forgot;
- \(D^r = D - D^f = \{(x^r, y^r)\}\).
Unlearning Layers
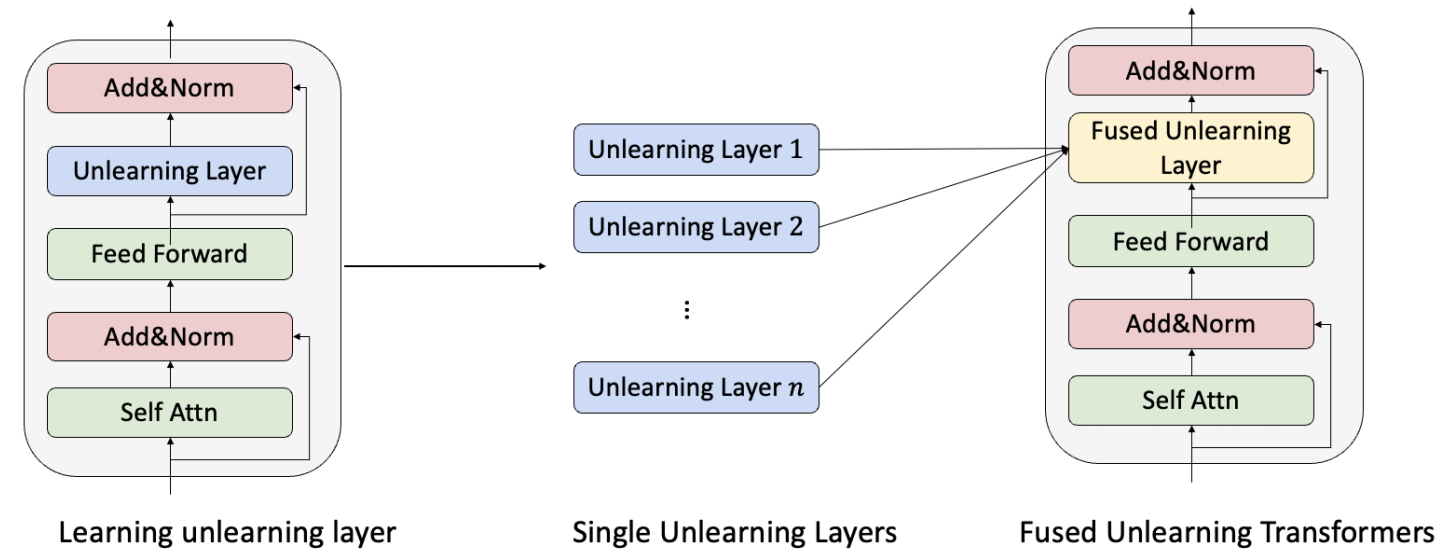
-
作者希望通过微调 Unlearning Layer \(f\) 来使得模型能够忘掉数据 \(D^f\), 如上图所示, 就是加载每个 block 中, 它的结构式一个简单的线性层.
-
为了达到这个目标作者首先引入 KL 散度:
\[L_{KL} = \alpha \sum_{x^r} KL(F(x^r) \| F'(x^r)) -\sum_{x^f} KL(F(x^f) \| F'(x^f)), \]即对于一般的数据点, \(F'\) 的输出要和原来的 \(F\) 靠近, 对于需要遗忘的数据点, 则需要和原来的数据点原理 (难道远离就是遗忘吗? 我感觉比较均匀分布会不会更好一点?)
-
其次为了保证下游任务的性能, 引入 task loss:
\[L_{Task} = \sum_{x^r} l(F'(x), y^r). \] -
最后是 LM 的预训练损失, 确保 LM 本身也忘掉数据 \(D^f\),
\[L_{LM} = -\sum_{x^f} l(F'(X^f)). \] -
最后总的损失为:
\[L_{EUL} = L_{KL} + \lambda L_{TASK} + \gamma L_{LM}. \]
Fusing Unlearning Layers
- 作者还讨论了, 假如我们依次遗忘了 \(m\) 次数据, 即有 \(f_1, f_2, \ldots, f_m\), 如何将这些 unlearning layers 综合起来呢? 作者选择求解如下的 \(W\):\[\min_{W_m} \sum_i \|W_m^T X_i^f - W_i^T X_i^f\|^2, \]它有显式解如下:\[W_m = (\sum_i {X_i^f}^T X_i^f)^{-1} \sum_i ({X_i^f}^T X_i^f W_i). \]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号