Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks
概
本文讨论如果预训练模型在训练的时候存在噪声, 会对后续的任务有什么影响, 并提出了一些解决方案.
符号说明
- \(\mathbf{x} \sim \mathcal{X}\), inputs;
- \(y \sim \mathcal{Y}\), labels;
- \(\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i \in [N]}\), clean dataset, \([N] := \{1, \ldots, N\}\);
- \(\hat{\mathcal{D}} = \{(\mathbf{x}_i, \hat{y}_i)\}_{i \in [N]}\), noisy pre-training dataset.
- \(\mathbf{F} \in \mathbb{R}^{M \times D}\), pre-trained features;
经验性的结果
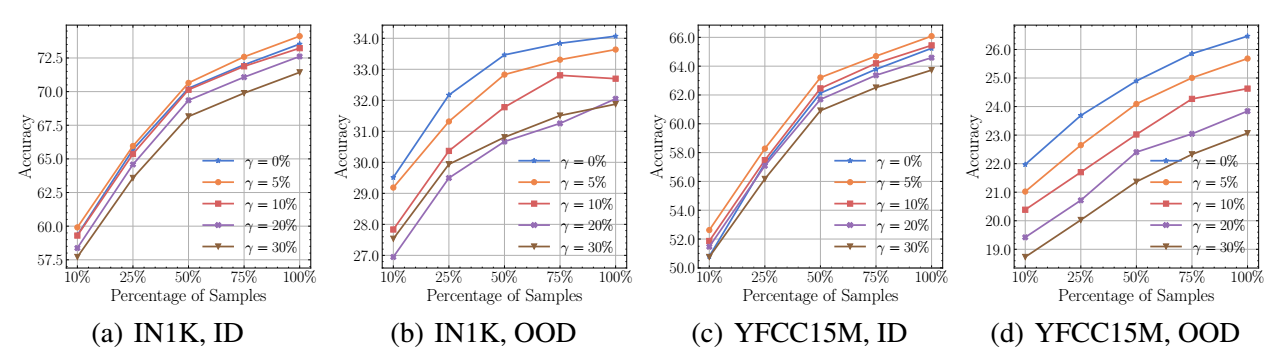
-
如上图所示, 当给数据集添加不同比例的噪声, ID (In-domain) 的情况会比 OOD (Out-of-domain) 的情况好很多.
-
让我们额外定义一些指标, 它们会告诉我们噪声的一些其它影响.
-
Singular Value Entropy (SVE):
\[\text{SVE} = -\sum_{i=1}^D \frac{\sigma_i}{ \sum_{j=1}^D \sigma_j } \log \frac{ \sigma_i }{ \sum_{j=1}^D \sigma_j }, \]奇异值谱的熵反映了预训练得到的特征蕴含的结构, 越大说明其中的结构越丰富.
-
Largest Singular Value Ratio (LSVR):
\[\text{LSVR} = -\log \frac{ \sigma_1 }{ \sum_{i=1}^D \sigma_i }. \]LSVR 反映的是最大奇异值的情况.
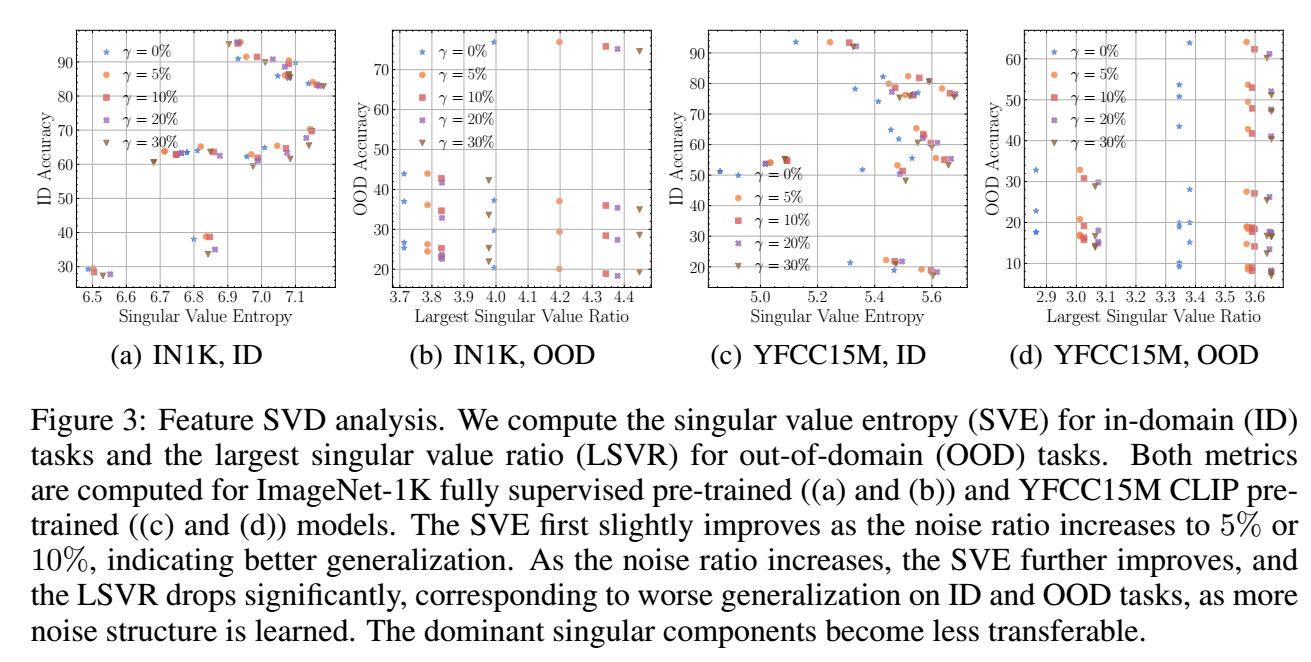
- 如上图所示 (没看懂), 结论如下:
- 稍稍增加一定比例的噪声数据反而有利特征的泛化性;
- 当继续增加噪声数据的比例的时候, SVE 和 LSVR 继续增加 (即 pre-trained faetures 具有越来越多的结构性), 这个时候就没法再继续提高泛化性了.
Noisy Model Learning
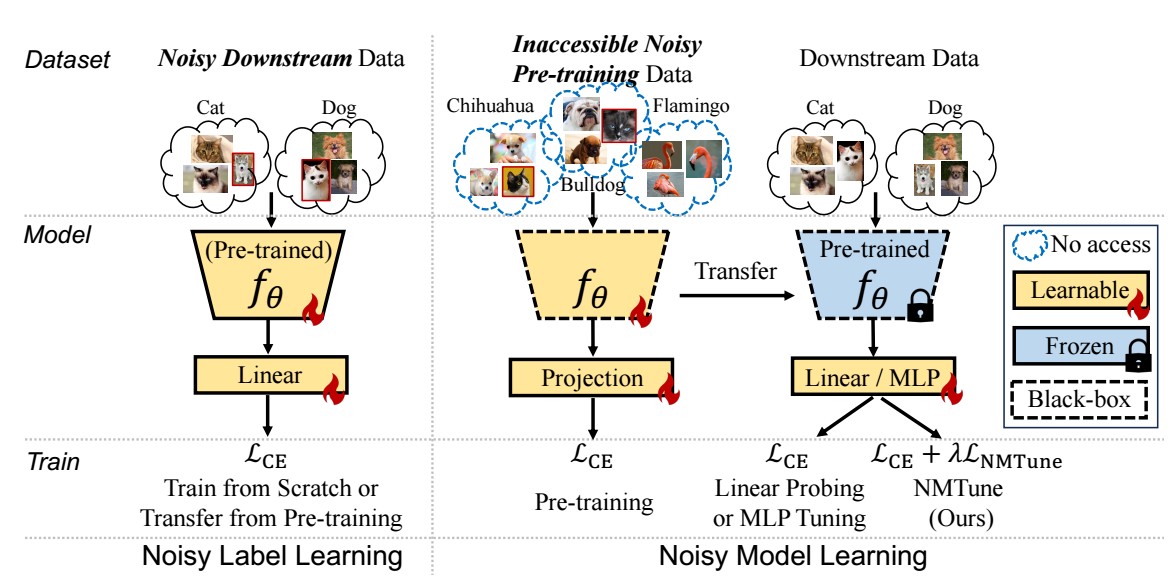
- 于是作者提出了一宗 noisy model learning 的方法, 它实际上一个训练的时候的正则化项:\[\mathcal{L}_{\text{NMTune}} = \mathcal{L}_{\text{MSE}} + \mathcal{L}_{\text{COV}} + \mathcal{L}_{\text{SVD}}. \]其中\[\mathcal{L}_{\text{MSE}} = \bigg\| \frac{\mathbf{F}}{\|\mathbf{F}\|_2} - \frac{\mathbf{Z}}{\|\mathbf{Z}\|_2} \bigg\|_2^2. \]\[\mathcal{L}_{\text{COV}} = \frac{1}{D} \sum_{i\not = j}[ C[\mathbf{Z}] ]_{i, j}^2, \quad C(Z) = \frac{1}{M - 1} \sum_{i=1}^M (z_i - \bar{z}) (z_i - \bar{z})^T, \bar{z} = \frac{1}{M} \sum_{i=1}^M z_i. \]\[\mathcal{L}_{\text{SVD}} = -\frac{\sigma_1}{\sum_{j=1}^D \sigma_j}. \]注意, \(\mathbf{Z} = \text{MLP}(\mathbf{F})\).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号