Towards Universal Sequence Representation Learning for Recommender Systems
概
本文提出了一个用 text 替代 ID 的序列模型.
符号说明
- , item text;
- , temperature;
- , batch size.
UniSRec
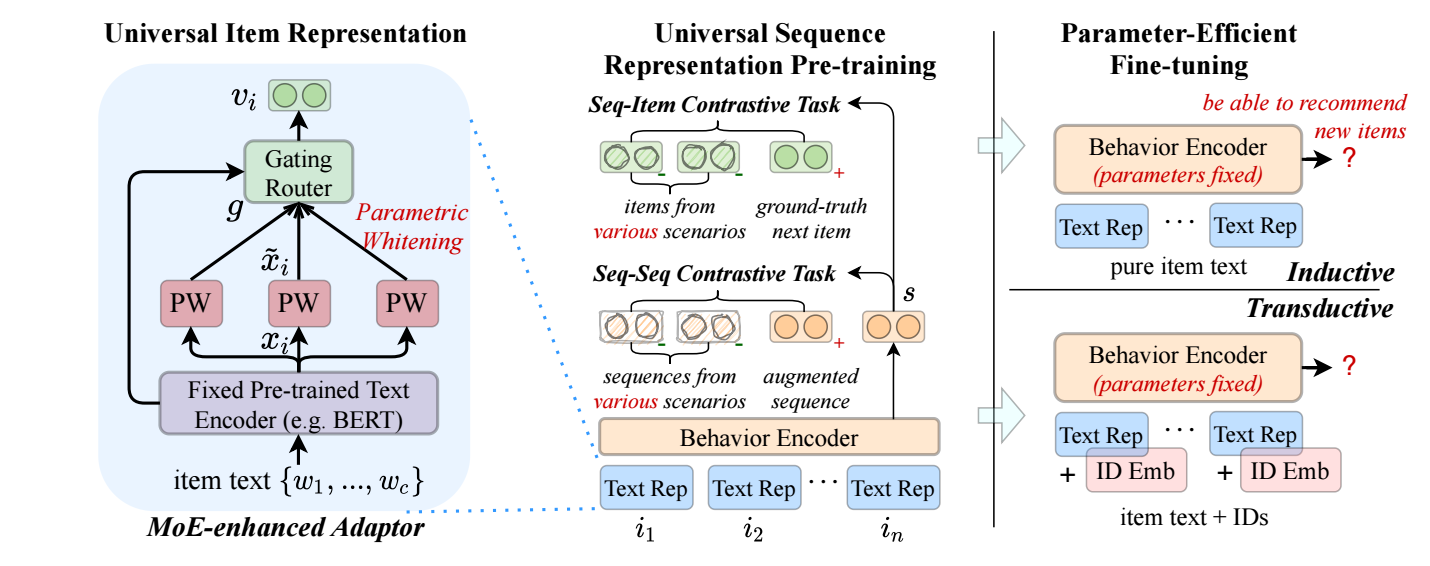
统一的文本表示
-
首先, 我们用预训练模型 (e.g., BERT) 来得到 item 的一个统一表示:
其中 是一个特殊的 token, 最后 就是取的 位置的 emedding.
-
接下来, 进行 Parametric whitening, 这被证明能够提高 embedding 的质量, 不同之处在于, 作者这里采用可学习的 ():
-
Domain Fusion and Adaptation. 为了是的 UniSRec 能够拓展到不同的 domain 上, 作者利用 MoE 进行 fusion:
统一的序列表示
-
通过 transformer 进行序列建模 .
-
训练的时候, 假设一个 batch 有 , 设计如下的 sequence-item 对比损失:
-
此外, 还有一个 sequence-sequence 的对比损失, 旨在区分来自不同 domain 的序列:
其中 是通过 Item/Word drop 后得到的另一个 view.
-
于是预训练的损失为:
Parameter-Efficient Fine-tuning
- 想要扩展到一个新的 domain 很简单, 只需要微调 MoE adaptor 就可以了.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2020-05-28 DEFENSE-GAN: PROTECTING CLASSIFIERS AGAINST ADVERSARIAL ATTACKS USING GENERATIVE MODELS
2020-05-28 Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples