End-to-end training of Multimodal Model and ranking Model
概
本文提出了一个 End-to-End 的多模态模型 (虽然实际上模态 encoder 依旧是不训练的), 利用 Fusion Q-former 进行特征融合.
主要内容
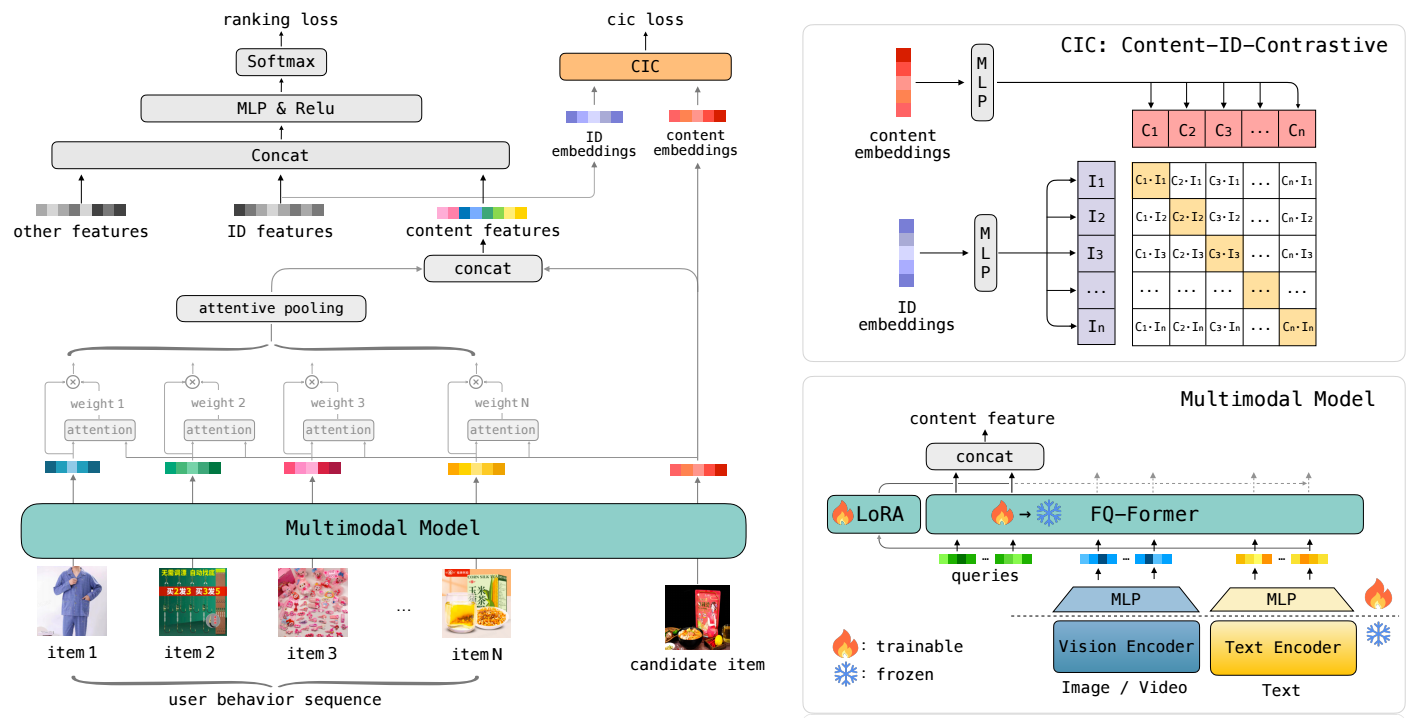
- 由于我只对 Fusion Q-former 感兴趣, 这里只是简单介绍下它的流程:
-
对每个 item, 通过 Vision/Text Encoder 得到对应的模态 embeddings:
\[\bm{v}_A = \{v_1(A), \ldots, v_M(A)\}, \\ \bm{t}_A = \{t_1(A), \ldots, t_K(A)\}. \]注意, 这里假设每个 item 有 M 个图片和 K 个文本描述.
-
通过 FQ-Former 进行特征融合:
\[c_{A} = f_{\text{FQ-Former}} (\bm{q}, \bm{v}_A, \bm{t}_A) = \text{TRM}(\text{concat}([\bm{q}, \bm{v}_A, \bm{t}_A]))[:Q], \\ \bm{q} = \{q_1, \ldots, q_Q\}, \]其中 \(q_i\) 表示某个 query, 所以每个 item 最后只有固定长度的特征 (即使图片和文本数量不一致).
-
整个序列的 item 通过上述方式得到 embeddings 后, 通过 attentive pooling 得到 content features.
-
content features 结合其它 features 可以用于后续的 raning.
-
此外, 训练的时候, 要求 ID features 和 content features 对齐 (类似 CLIP).
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号