LGMRec Local and Global Graph Learning for Multimodal Recommendation
概
本文采用分解的方法进行对 ID 和 模态信息进行独立处理, 再加上利用超图对模态信息进行 global 的处理.
符号说明
- , users;
- , items;
- , user ID embeddings;
- , item ID embeddings;
- , ID embeddings;
- , interaction matrix;
- , 模态;
- , item 对应模态 embedding;
- , 经过模态映射后的
- , 邻接矩阵;
- , normalized 邻接矩阵
Motivation
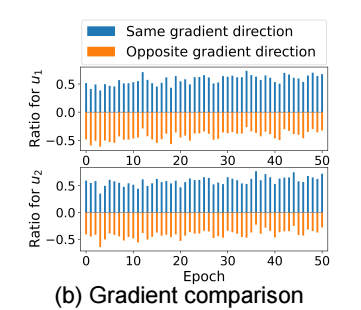
- 过往的方法, 往往模态 embeddings 和 ID embeddings 共享一个 user embeddings, 但是作者发现这种情况会导致在训练的时候, 二者对于 user embeddings 的更新的贡献可能是截然相反的:
-
如上图所示, 在训练的开始, 这种情况更外明显.
-
此外, 作者认为, 模态信息的很重要的一个点是能够反映用户对于 color, style, shape 等属性信息的偏好, 所以应该特别显式建模出这一点.
LGMRec
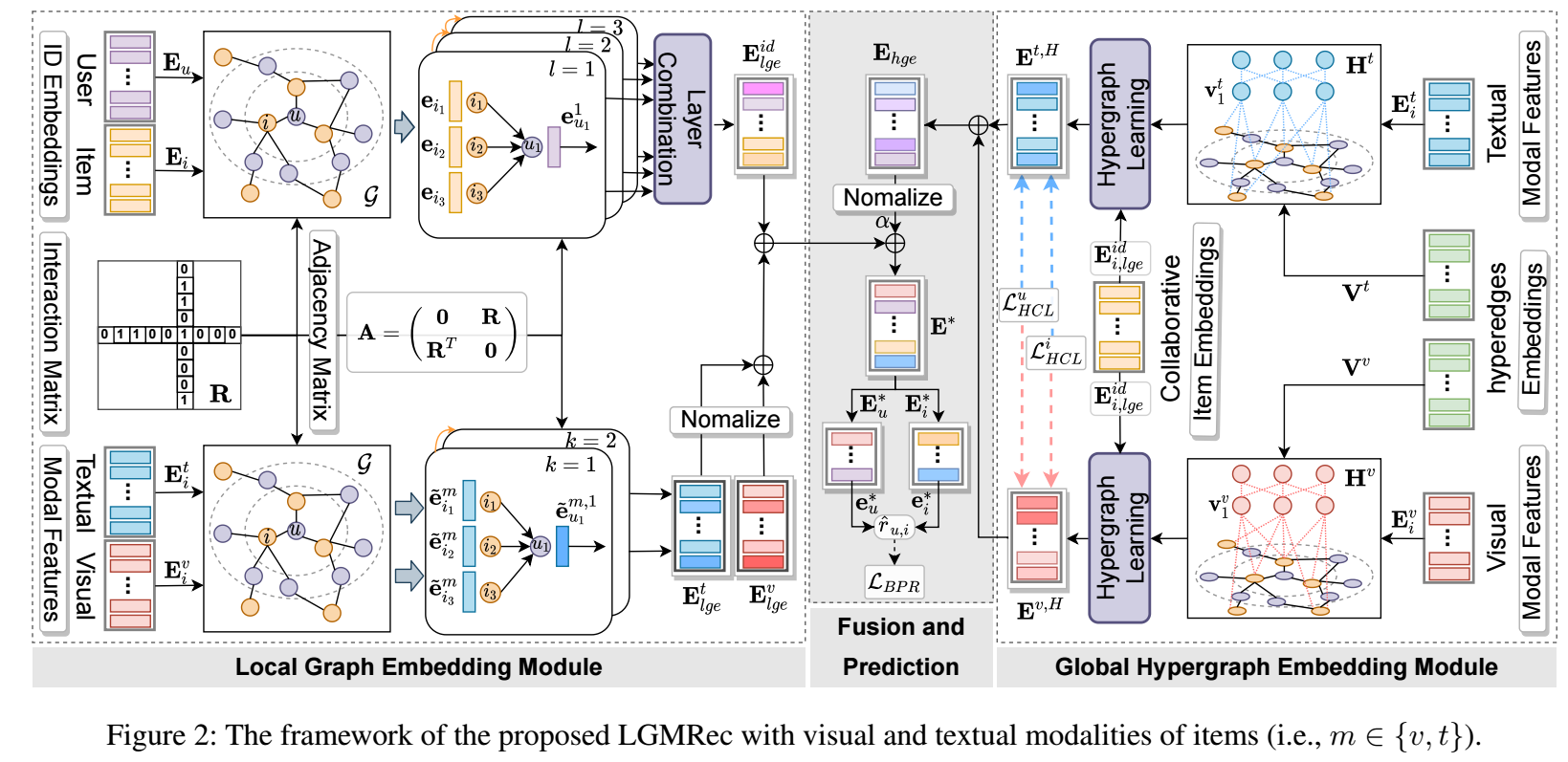
Local Graph Embedding
-
首先对于 ID, 采用 LightGCN 进行信息传播:
-
其次对于模态, 首先我们初始化 user 的 embeddings 为
-
接着
Global Graph Embedding
-
作者首先引入 去学习 item, user 的属性偏好,
其中 是 user-related adjacency matrix (是不是 的行归一化?).
-
这样一来, 每个 item, user 都映射到了一个属性 , 为了确保每个 item 都尽可能映射到一个属性上, 作者额外通过 Gumbel-Softmax 来强化.
-
接下来, item 的 embeddings 更新方式如下:
Drop 表示 dropout.
需要注意的是, 这里 . 对于 user, 更新方式是类似的. -
最后,
-
为了保证不同模态学到的兴趣是一致的, 作者引入对比损失:
表示 cosine 相似度.
对于 item 的 是类似定义的.
Fusion
-
最后的 embeddings 为
-
score 通过内积完成, 损失采用的是 BPR 损失加上上面说的对比损失.
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2021-05-27 BBN
2021-05-27 DAGs with NO TEARS: Continuous Optimization for Structure Learning
2019-05-27 Python Revisited Day 09 (调试、测试与Profiling)