Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
概
本文介绍了一种推荐大模型的框架的训练方法.
GRs (Generative Recommenders)
任务形式
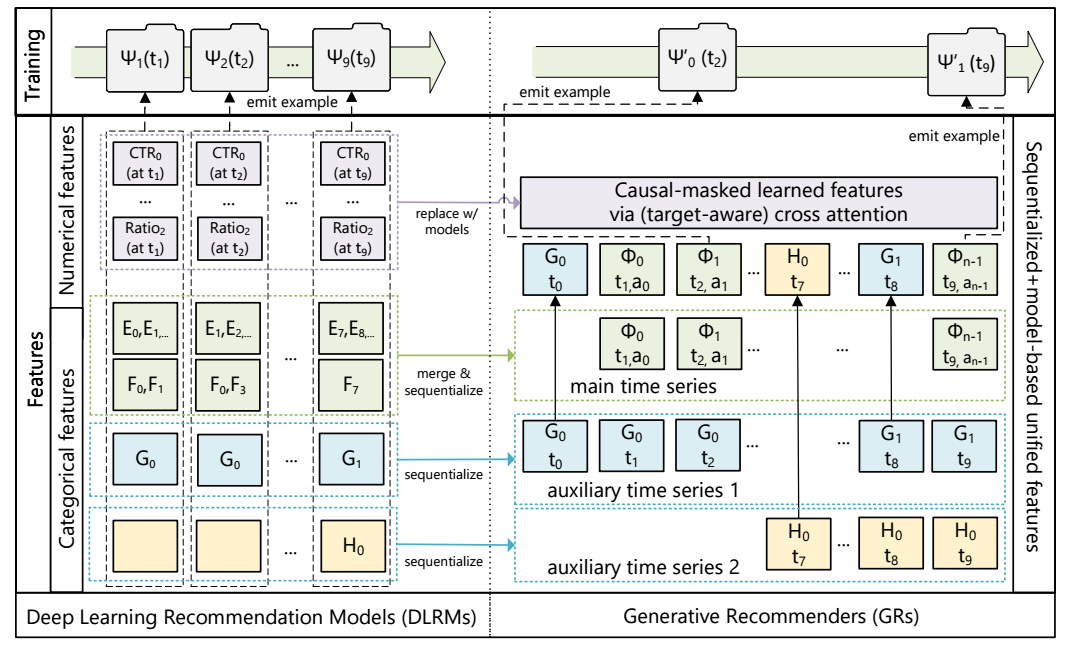
- 如上图所示, DRs 这里把 E/F, G, H 分别进行 merge and sequentialize, 这里 (E, F) 表示哪些用户的交互行为, merge 后得到的是 \((\Phi, a, t)\): (Context, action, timestamp), 二 G, H 则是一些 "not related to user-content engagements".

-
对于 ranking, 作者设计的任务是:
\[P(a_{i}| \Phi_{i}, a_{i-1}, \ldots, a_0, \Phi_0), \]即通过过往的信息预测下一个 action.
-
对于 retrieval, 作者设计的任务是仅对那些 \(a_i\) 为 positive 的情况进行:
\[P(\Phi_{i}| a_{i-1}, \Phi_{i-1}, \ldots, a_0, \Phi_0). \]negative 的 action 不进行预测.
模型设计
- 作者为了兼顾效率, 特别改进了模型框架:
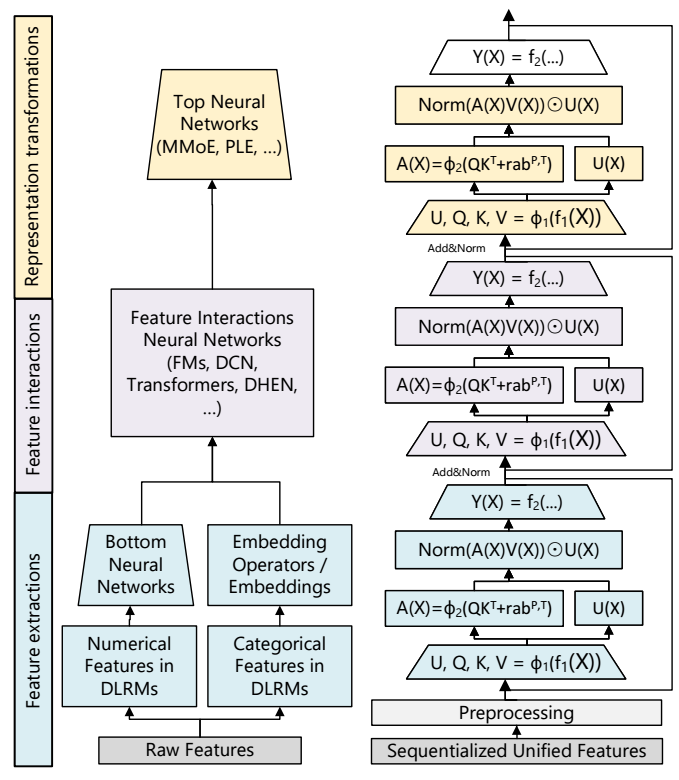
- 注意到, 其中的每个模块变成了:
 o
o
- 虽然形式上和 attention 还是比较像的, 但是注意到:
- \(Q(X) K(X)^T\) 并没有经过 softmax 处理, 作者认为这样除了效率外, 还能够保证不同的参与度能够有所区分;
- \(U(X)\), 门控机制的引入 (作者用来模拟 MoE).

-
可以发现, softmax 这个点的影响很大.
-
此外, 还有数据集的切分, 优化器的选择等等.
虽然最后的效果并没有特别夸张, 但是这些尝试是值得肯定的.
代码
[official]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号