Bridging Language and Items for Retrieval and Recommendation
概
本文提出了一种利用对比损失训练的预训练模型, 能够把握数据集中的交互信息.
BLaIR
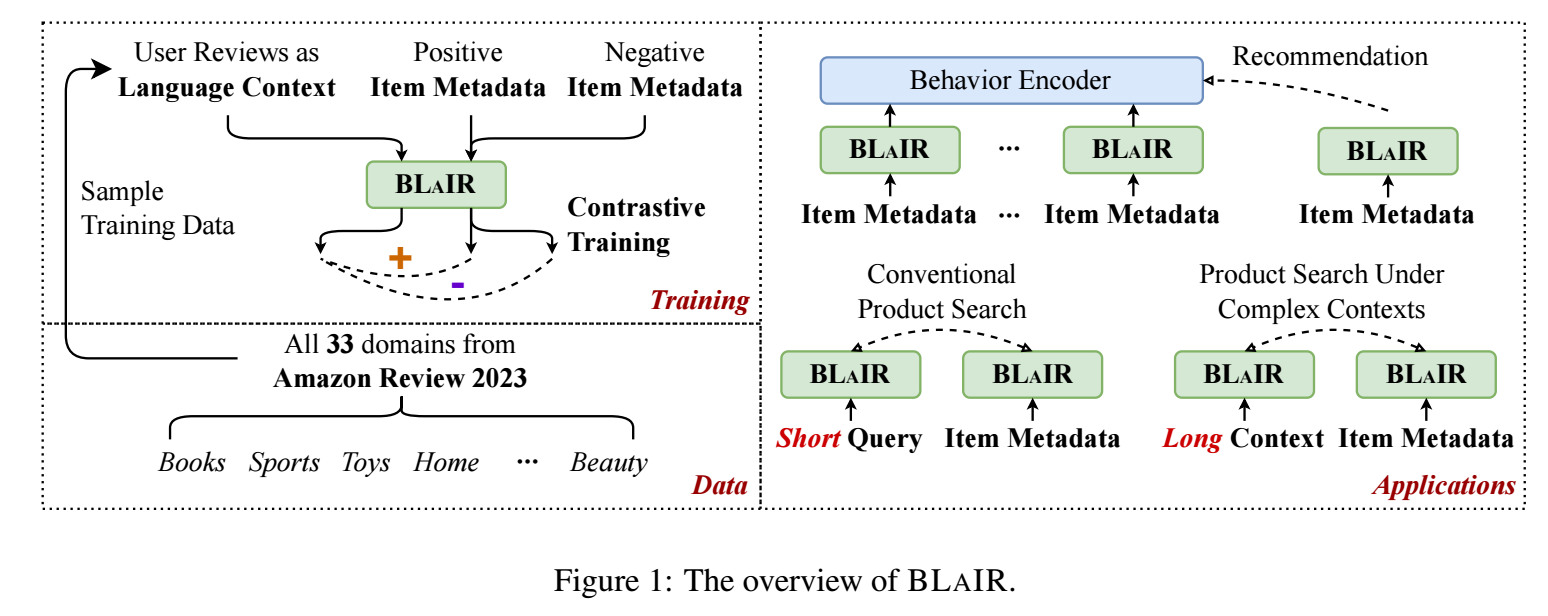
-
BLaIR 的思想很简单如上图所示, 输入为用户的评论, 然后以交互过的商品的 metadata 作为正样本, 没交互过的商品的 meatdata 为负样本, 构成对比损失:
\[\mathcal{L}_{CL} = -\sum_{i}^B \log \frac{ \exp(\bm{c}_i \cdot \bm{m}_i / \tau) }{ \sum_{j}^B \exp(\bm{c}_j \cdot \bm{m}_j / \tau) }, \]其中 \(\bm{c}_i, \bm{m}_i\) 分别是 context 和 item metadata 经过编码后得到的特征, 注意到, 这里负样本直接是采用 in-batch 的负样本.
-
然后结合一般的训练损失, 综合的损失为
\[\mathcal{L} = \mathcal{L}_{CL} + \lambda \mathcal{L}_{PT}. \]注意, \(\mathcal{L}_{PT}\) 即预训练损失区别 BLaIR 选择哪个 backbone, 比如是 BERT 类的就是 MLM 损失, GPT 类的就是自回归损失.
-
实验部分, 作者拿了 Beauty, Games, Baby 三个子数据集进行实验, 得到的结果如下:
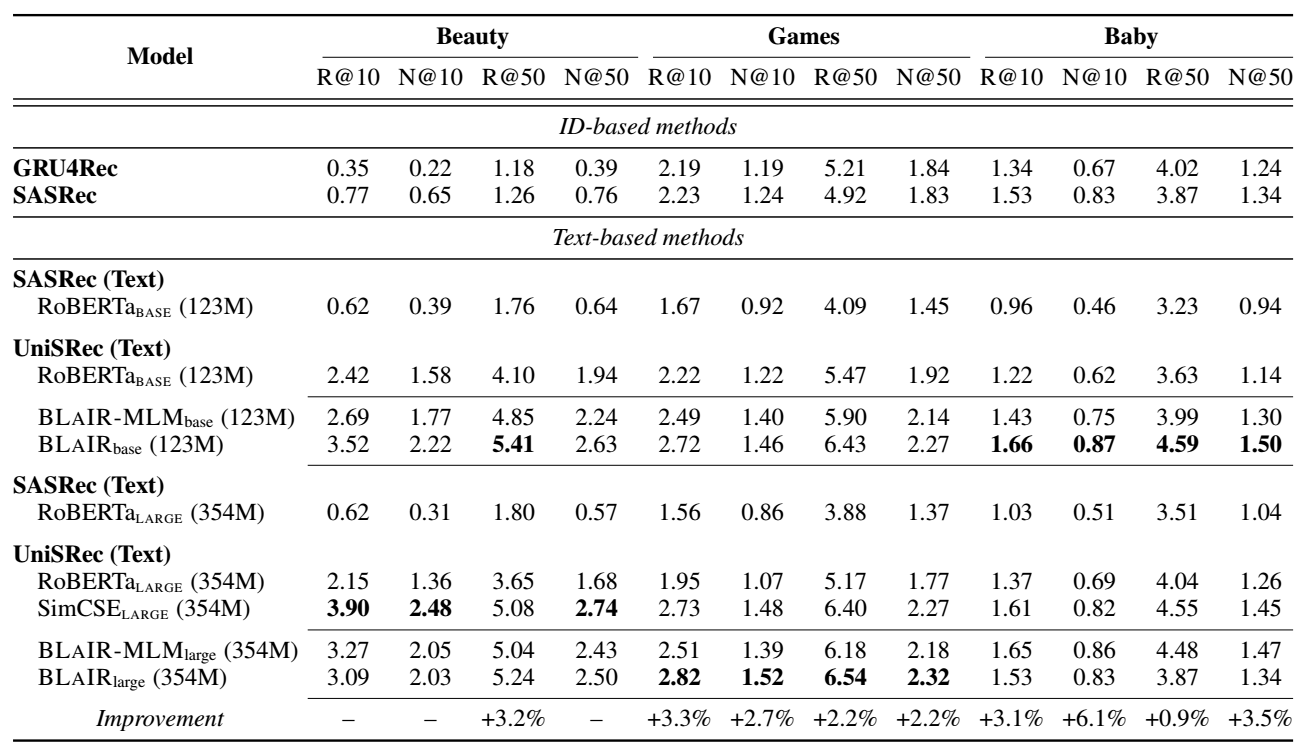
- 可以发现, UniSRec 以 BLaIR 为 encoder 可以取得最好的效果 (而且有一定的 scaling law 现象存在).
注: 本文的数据处理并没有进行 k-core filtering, 而且切分是按照全局的 8:1:1 切分的, 不是常见的 leave-one-out.
代码
[official]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号