Shazeer N., Mirhoseini A., Maziarz K., Davis A., Le Q., Hinton G. and Dean J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. ICLR, 2017.
概
Mixture-of-Experts (MoE).
MoE
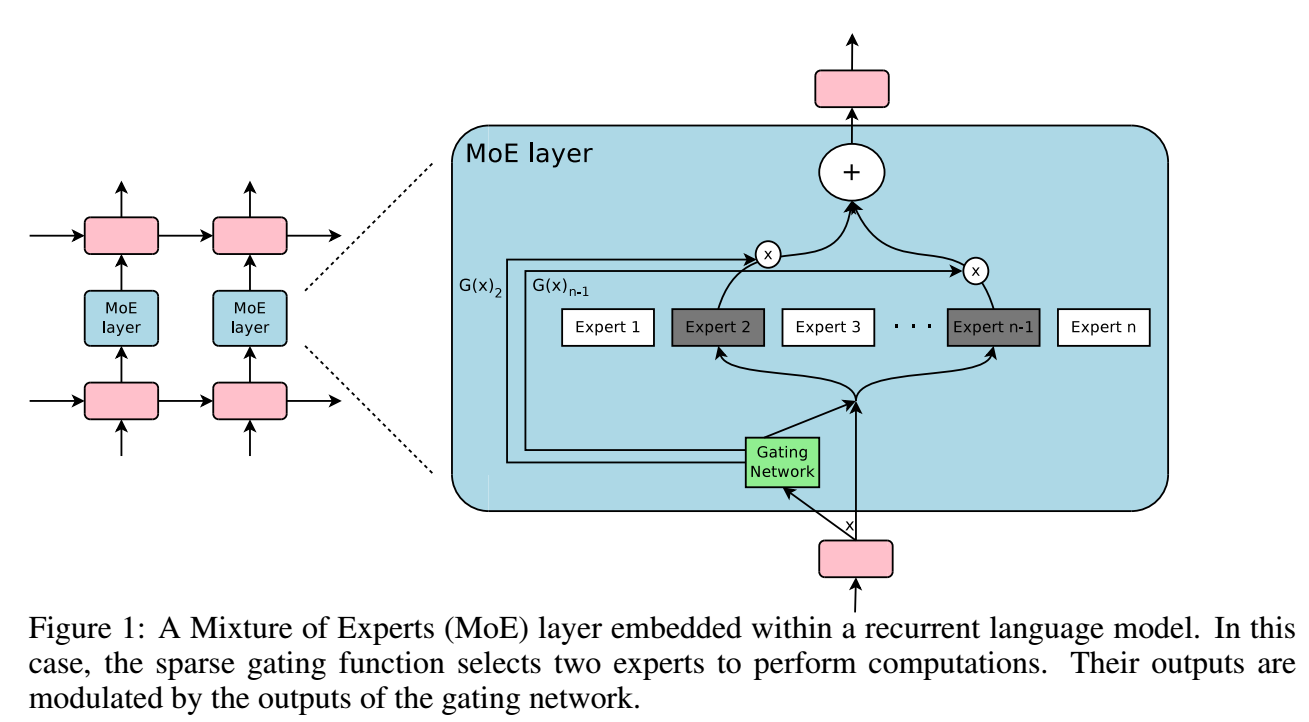
-
通过一 gating network 选择不同的 expert:
y=n∑i=1G(x)iEi(x),
若 G(x)i=0, 则我们不需要计算 Ei(x).
-
Ei(x) 可以是任意的网络, 所以现在的问题主要是如何设计 G. 倘若我们希望选择 k 给 experts, 可以:
G(x)=Softmax(KeepTopK(H(x),k),)H(x)i=(x⋅Wg)i+StandardNormal()⋅Softplus((x⋅Wnoise)i),KeepTopK(v,k)i={viif vi is in the topk elements of v.−∞otherwise.
-
特别的是, 这里加了高斯噪声, 并用 Wnoise 去调节不同位置的噪声的比重, 从而可以实现负载平衡 (?).
训练
-
如果不对 G 加以额外的限制, 容易出现某些 experts 持续获得较大的权重, 所以本文引入了一个 soft constraint
Limportance(X)=wimportance⋅CV(Importance(X))2,Importance(X)=∑x∈XG(x)
CV 作者说是 variation, 是方差吗?
-
有了 soft constraint, 依然会出现每个 expert 接受的样本数量的差别很大 (有些 expert i 可能会接受很少的样本但是其上 G(x)i 都很大, 有些 expert i 可能接受很多的样本, 但是其上 G(x)i 都很小). 所以作者额外添加了对于选择概率的约束.
-
对于样本 x, expert i 被选择的概率为 (感觉这个定义应该是有问题的)
P(x,i)=Pr((x⋅Wg)i+StandardNormal()⋅Softplus((x⋅Wnoise)i)>kthexcluding(H(x),k,i)).
其中 kthexcluding(v,k,i) 表示 v 中的 k-th 大的值 (排除 i).
-
所以,
P(x,i)=Φ((x⋅Wg)i−kthexcluding(H(x),k,i)Softplus((x⋅Wnoise)i)).
-
定义
Load(X)i=∑x∈XP(x,i),
则
Lload(X)=wload⋅CV(Load(X))2.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2023-05-10 Diffusion models as plug-and-play priors
2022-05-10 Pareto Multi-Task Learning
2022-05-10 Neural Collaborative Filtering
2019-05-10 Robust De-noising by Kernel PCA