Lightweight Modality Adaptation to Sequential Recommendation via Correlation Supervision
目录
概
解决多模态序列推荐中的 modality forgetting 问题.
符号说明
- , 结点;
- , 模态特征;
- , 模态特征通过 encoder 得到的 embedding;
- , 通过 embedding initialization module 得到的 embedding;
- , 随机初始化的 id embedding;
Motivation
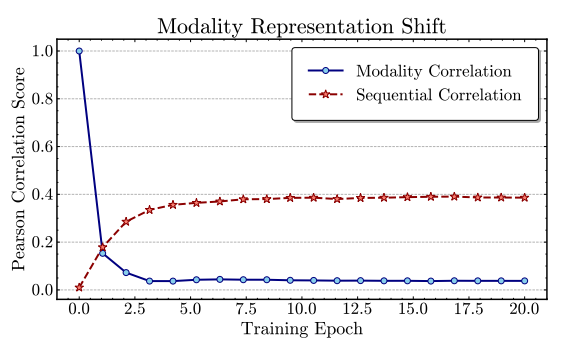
- 同一个序列模型, 使用 item 的模态信息作为表示和利用随机初始化的 ID embedding 进行训练, 二者随着训练的进行, 他们间的 Pearson score 如上图蓝色线所示, 可以发现, 一下子就降到了 0 附近. 这意味着模态信息在训练过程中被遗忘了.
注: 我不清楚模态信息是怎么被完全遗忘的? 因为维度不一样, 不能直接作为初始化吧. 难不成简单用 MLP 降维就能起到这个效果?
Knowledge Distillation framework for modality-enriched Sequential Recommenders (KGSR)

- 作者解决上面的问题的思想和简单, 就是希望 embedding 在训练过程中, 尽可能保持原先模态特征的相关性.
相似度建模
-
首先计算原先模态的相似度:
- 将原先 encoder 得到的模态 embedding 通过一个自编码进行去噪:
- 通过 correlation scoring function 计算两两的相似度
- 将原先 encoder 得到的模态 embedding 通过一个自编码进行去噪:
-
codebook 编码. 上面的模态相似度比较粗粒度, 这里作者额外采用一种更为复杂的方式. 它就是采用向量量化, 把两个模态的相似度隐射为一个类别 . 可以认为每个类别代表 在哪个层面是相似的. 我们希望后续的训练的 embedding 能够预测出这些类别.
相似度预测
-
接下来, 对于可训练的 embedding , 我们将上面的得到的相似度约束加在其中.
-
对于粗粒度的相似度:
- 计算
- 计算损失:其中 为 temperature parameter 用于条件 match 的程度.
- 计算
-
对于类别的相似度:
-
计算每个类别的概率
其中 .
-
计算损失:
-
训练
- 最后的训练目标就是



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2023-05-08 Understanding Dataset Difficulty with V-Usable Information
2022-05-08 Multi-Task Learning as Multi-Objective Optimization
2022-05-08 Multiple-gradient descent algorithm (MGDA) for multiobjective optimization
2021-05-08 Propensity Scores
2019-05-08 代数基础
2019-05-08 Kernel PCA and De-Noisingin Feature Spaces
2019-05-08 Python Revisited Day 08 (高级程序设计技术)