A Critical Study on Data Leakage in Recommender System Offline Evaluation
概
本文讨论了现在的推荐系统评价方式 (如 Leave-one-out) 存在的数据泄露的问题, 以及所导致的一些风险.
主要内容
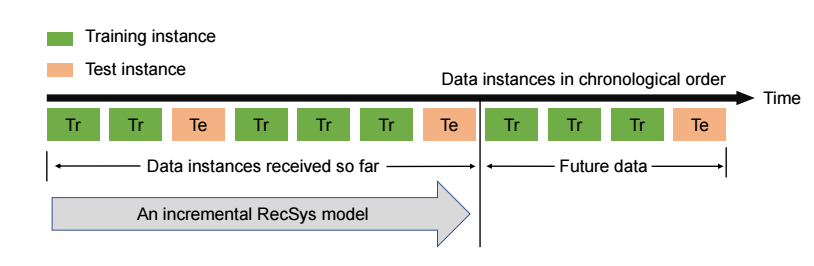
- 由于大部分的数据切分方法并没有严格遵守 global timeline 进行划分, 如下图所示
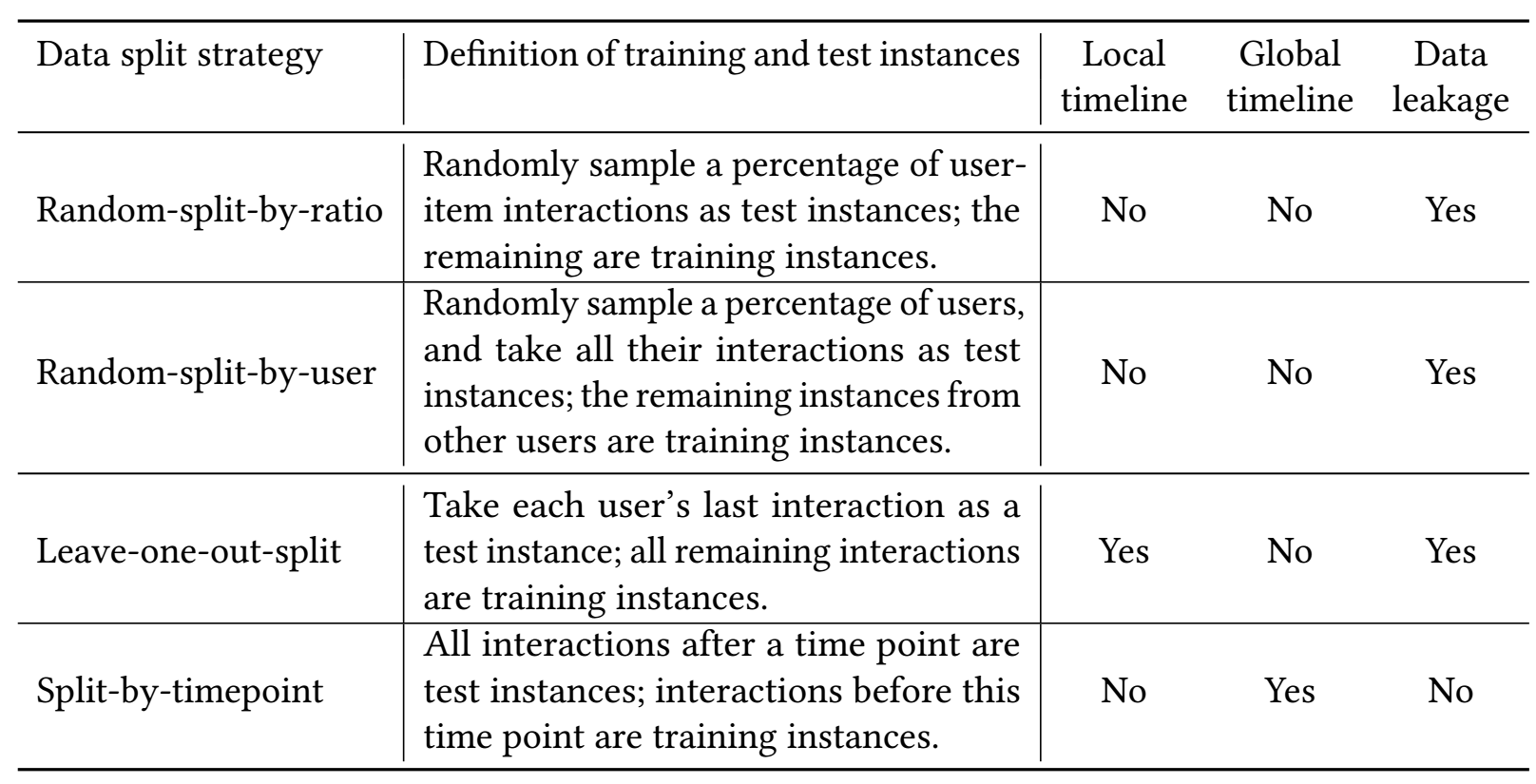
-
所以, 在评估的时候可能会导致:
- 为某个用户预测下一个他可能感兴趣的商品, 但是预测出来的结果在当前时刻实际上可能还没上架;
- 由于训练中接触到了一些未来的信息, 这在实际中也是不太可能的.
-
实验设置:
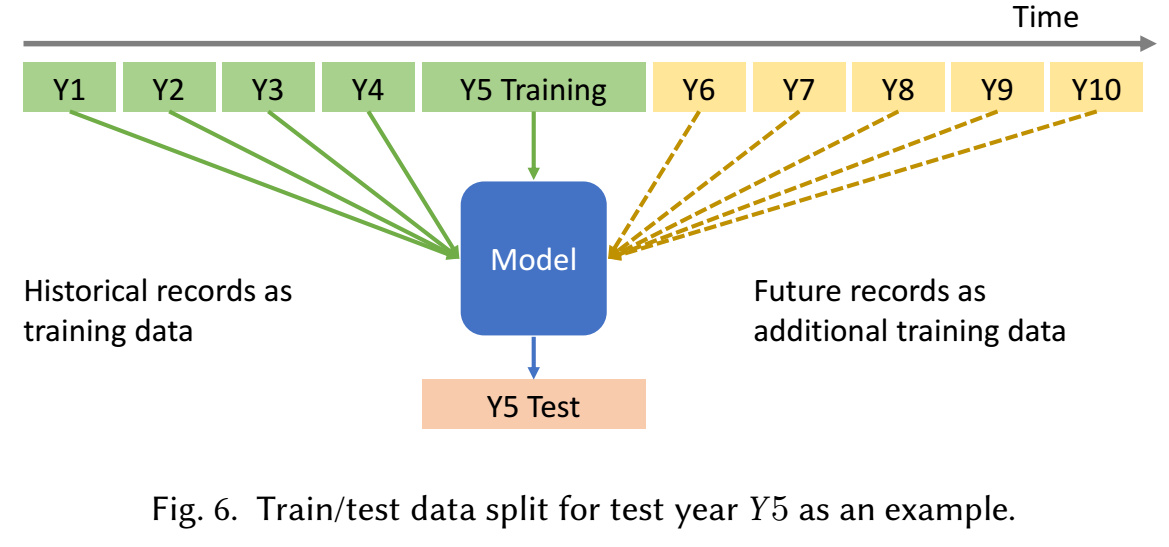
-
如上图所示, 将整个数据集按照年份分成 10 份, 选择 Y5, Y7 作为测试集. 然后训练的时候, 比如 Y6, 表示用 Y1-Y6 的数据作为训练集.
-
需要注意的是, Y5/Y7 作为测试集, 不是指把整个年份的交互作为测试, 是那些 users 的最后一个交互在 Y5/Y7 中的作为测试, 所以训练集和测试集是不会有重叠的.
数据集统计信息
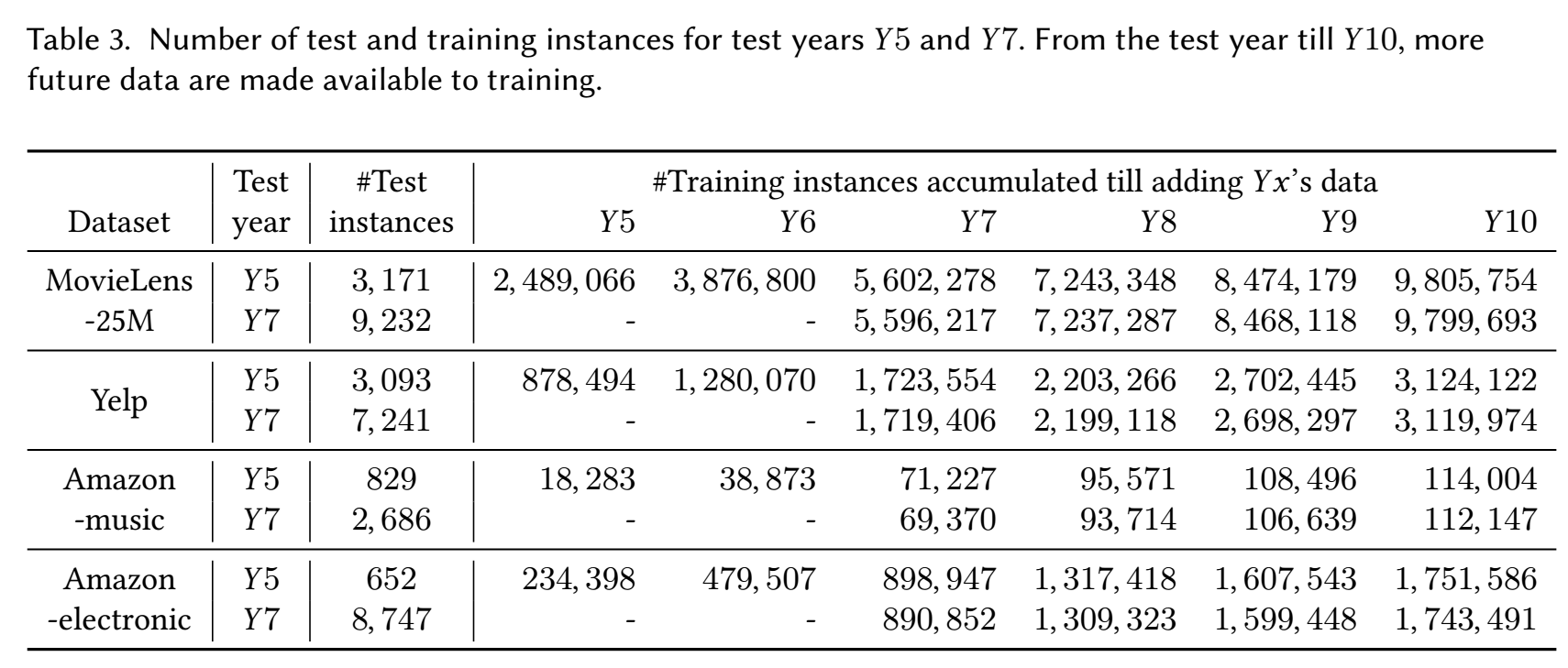
Top-N Recommendation List
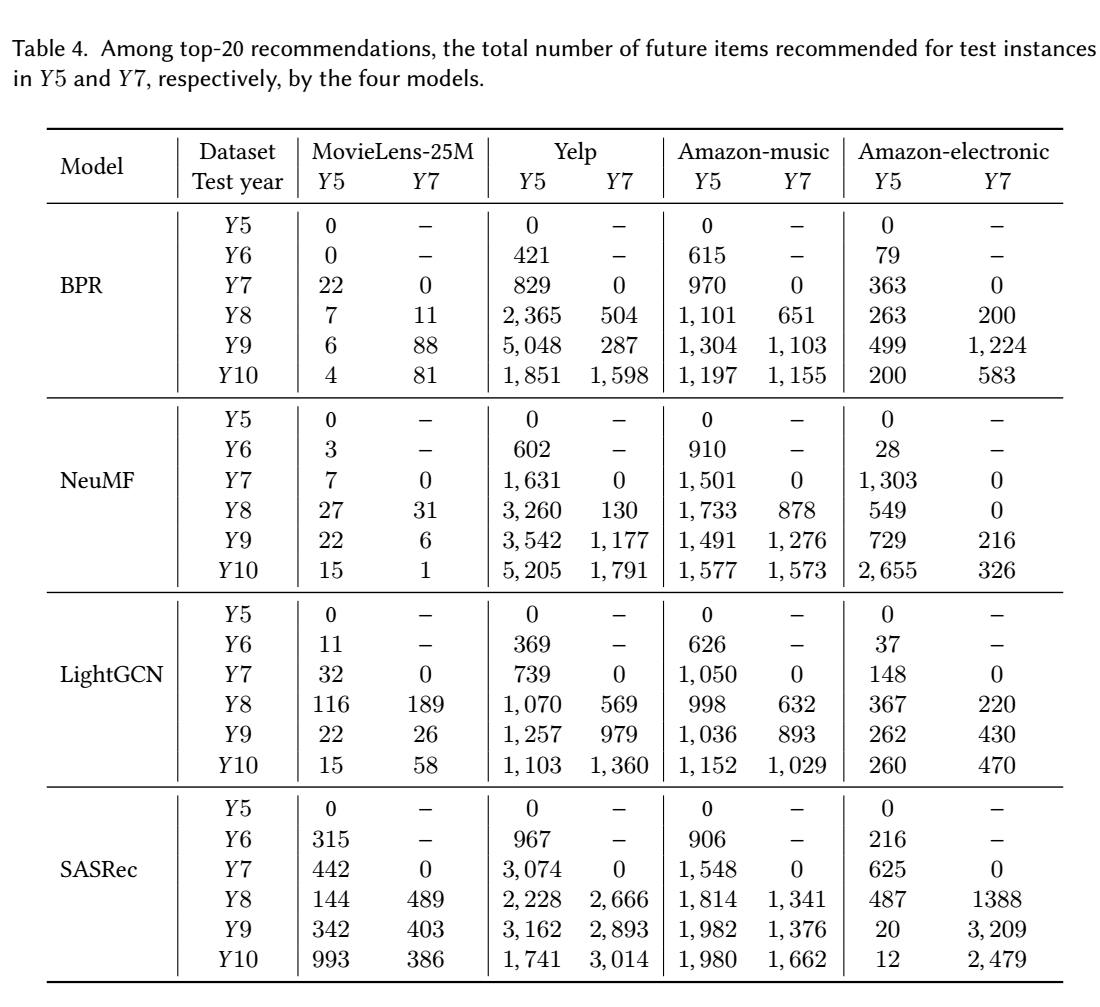
- 如上图所示, 大抵有如下的结论:
- 一旦未来的训练数据集被使用, 模型的推荐结果就会推荐只有在未来才有可能出现的 items, 这在实际中是不会发生的;
- 随着未来的训练数据的增加, 这个现象呈现加重的趋势.
Recommendation Accuracy
- 作者进一步比较在逐步增加未来数据的时候, 模型的精度的变化:
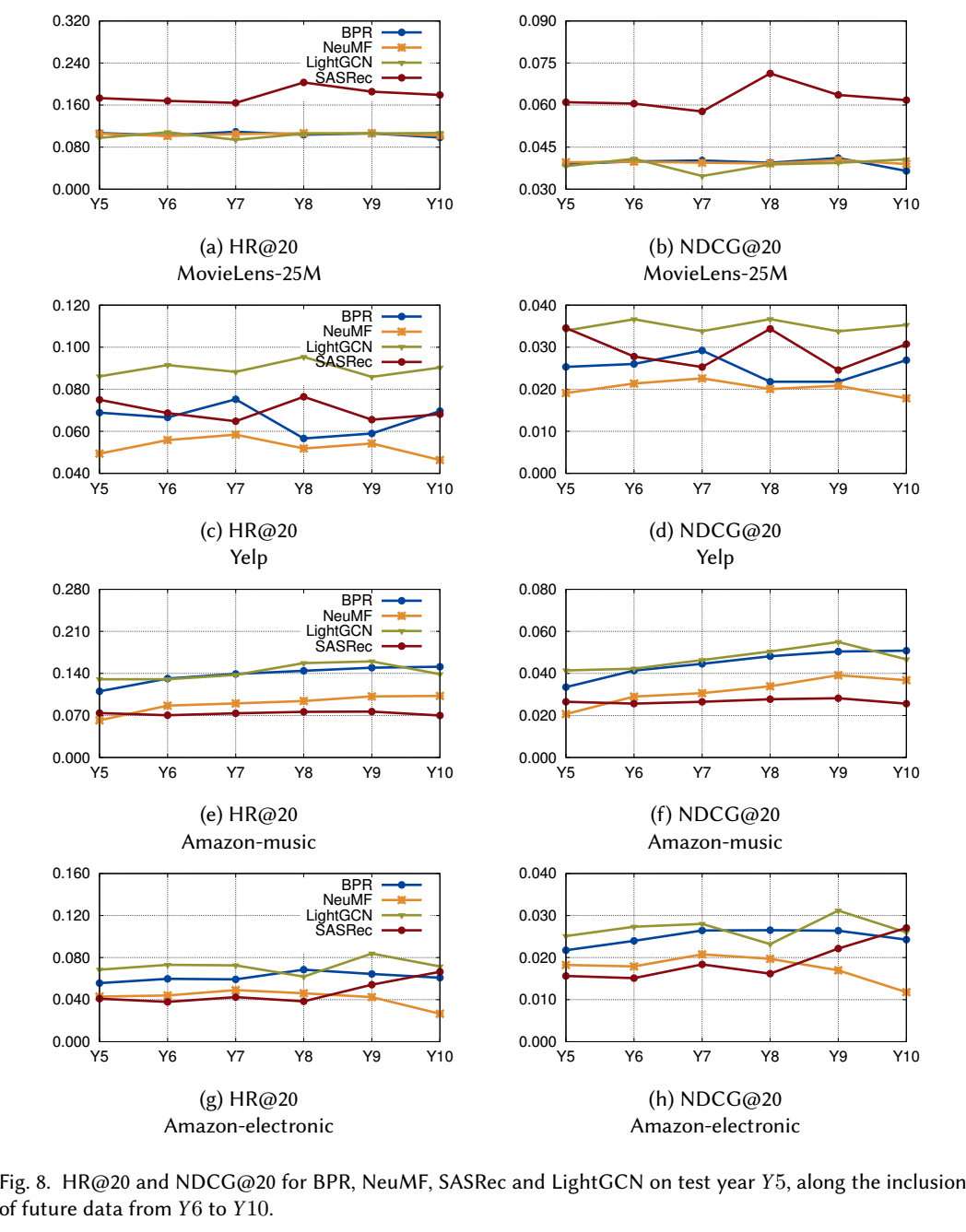
- 其实仅仅从图中, 似乎感觉整体的精度的变化其实不大, 但是比较相对的排名变化, 其实影响还是很大的:

- 可以发现, 不同的模型, 同一个数据集, 当未来数据的比例变化的时候, 各自的相对排名往往不是固定的. 这个其实影响很大, 因为这变相说明我们在一般的如 leave-one-out 这种切分下得到的结论可能并不适用于实际的场景. 不过这里我有那么点疑问, 为啥这里 BPR 的效果能这么好, 感觉和具体的数据集也是有关系的.
理想的切分方式
- 理想的切分方式是采用滑动窗口:
- 这种方式已经被应用一些在线推荐中去了, 不过这种方式也存在一些技术上的问题:
- time windows 的长度, 太长了用户兴趣可能会变化很大, 太短了测试样本点又太少;
- 超参数调节, 应该根据哪部分数据进行参数调节?
- 如何综合评价模型? 因为完全也有可能出现某一部分测试集上一个方法好, 另一部分另一个方法好, 是平均地看待精度还是仅仅取最后一个测试集来判断, 也是一个问题.
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2023-05-05 Graph Convolutional Networks with EigenPooling
2022-05-05 Field-aware Factorization Machines for CTR Prediction
2021-05-05 Improving Adversarial Robustness Using Proxy Distributions
2020-05-05 ADVERSARIAL EXAMPLES IN THE PHYSICAL WORLD