Enhancing ID and Text Fusion via Alternative Training in Session-based Recommendation
概
作者“发现”多模态推荐中 ID 和文本模态的结合做的并不好, 于是乎提出了一种交替的训练方式.
Motivation
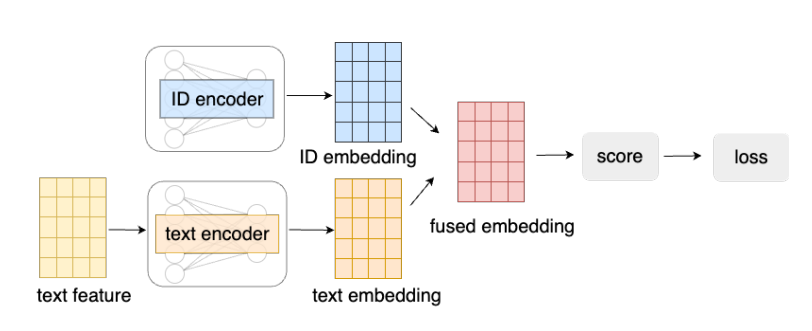
- 如上图所示, 现在的将不同模态融合在一起的方式大抵是分别进行编码, 然后进行简单的融合 (平均, 或者拼接), 但是这种方式却不能取得理想的结果.
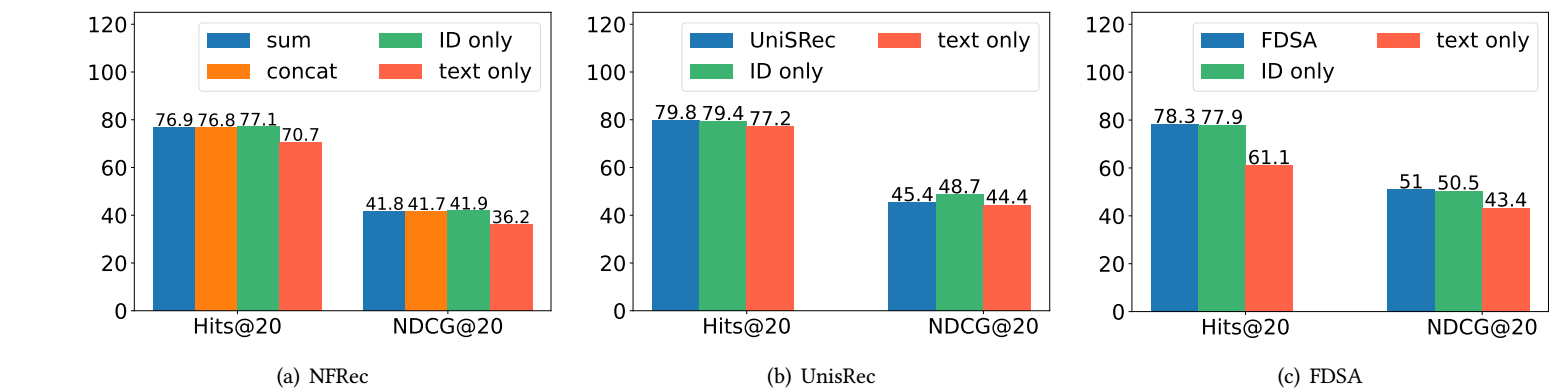
- 如上图所示, 在各种模型上, ID-only 的方法就已经能够取得和模态融合几乎一致 (甚至更好) 的效果.
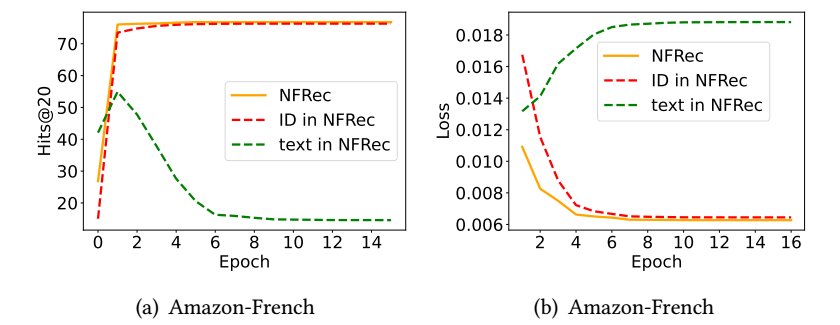
- 作者进行了一个简单的实验验证, 采取拼接的方法融合, 然后分别探究 ID 和 Text 两部分对于推荐性能和损失的共享, 可以发现, 随着训练的迭代, ID 在逐渐学的更好, 而 Text 部分甚至是越来越差.
AlterRec
- 所以, 本文的思路是两者进行一个交替的训练:
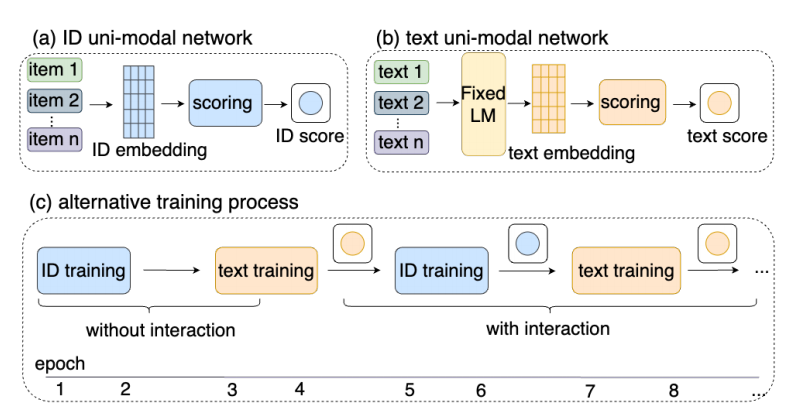
-
特别的, ID 部分有 ID embedding table 可以训练, Text 部分有一个 MLP projector 可以训练.
-
然后 scoring 部分, 作者采用 Mean Function 或者 Transformer.
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-04-25 Recovering Low-Rank Matrices From Few Coefficients In Any Basis
2019-04-25 Nonlinear Component Analysis as a Kernel Eigenvalue Problem