An Analysis of Sequential Recommendation Datasets
概
本文讨论了 MovieLens 系列数据集是否适用于序列推荐.
统计角度论证
- 作者为了论证 MovieLens 不适合作为序列推荐数据集, 首先从数据集的统计信息角度出发.
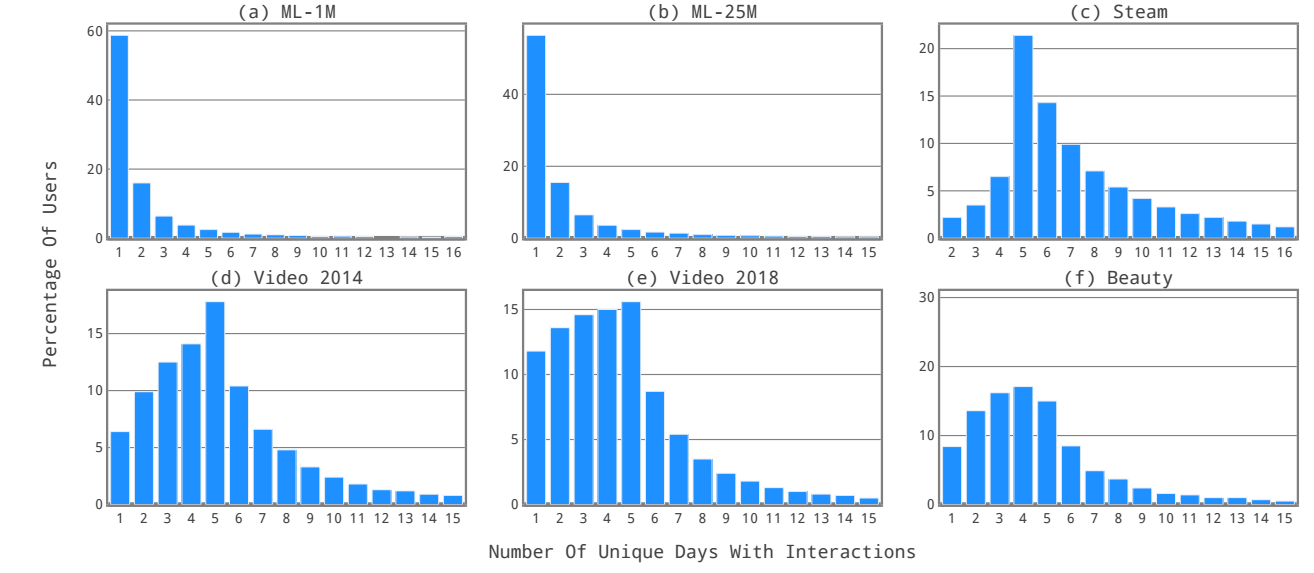
- 上图展示了常用的序列推荐数据集的 Day 分布情况, 如 '6' 上的占比表示该数据集中所有交互均发生在 6 天内的用户的占比. 显然和其它数据集相比, MovieLens 系列的数据集所有的交互有大半发生在一天内.
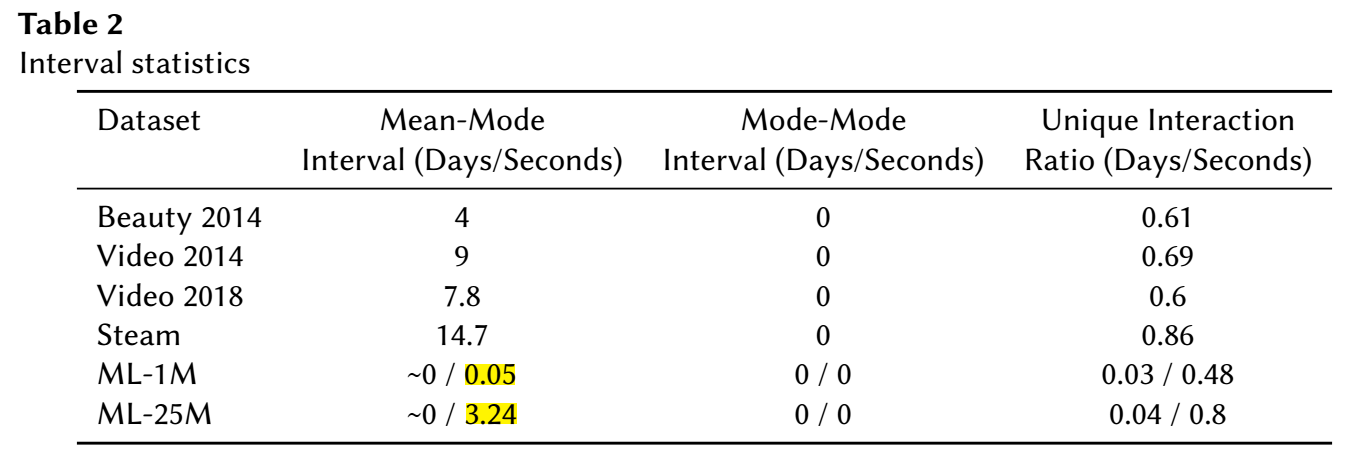
- Table2 展示了更加精细化的一个指标. 可以发现, ML-1M 每个用户的平均交互时间发生在 0.05s 内, 换言之, 你可以认为大部分用户交互的电影的时间戳是同一个! 要知道, MovieLens 中每个用户的平均交互次数 , 怎么可能同一个时间戳内同时给上百部电影打分? 所以作者认为, MovieLens 的数据集并不是真实的用户观看 (打分) 历史, 而是通过某种特殊的数据收集的方式得到的, 这导致如果我们采用的是序列预测, 我们实际上预测是这种数据收集方式, 而不是用户的兴趣变化.
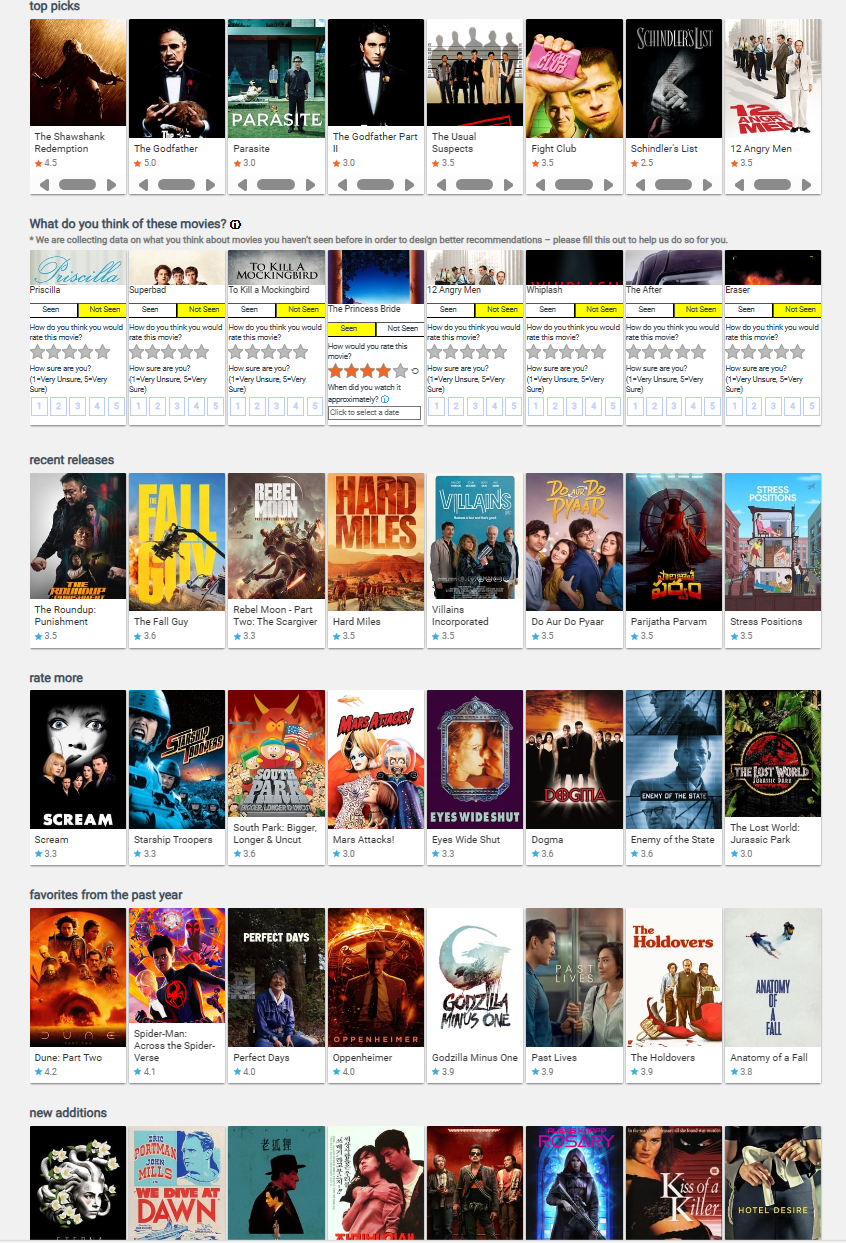
- 如上图所示, MovieLens 的用户主页, 其实就是一堆的推荐电影, 然后你可以去打分, 我想 MovieLens 的数据集就是这么收集过来的. 这么一想, 确实如果 MovieLens 去做 next-item predication 的话, 实际上我们是去预测背后的推荐机制, 而不是用户的观影顺序.
实验论证
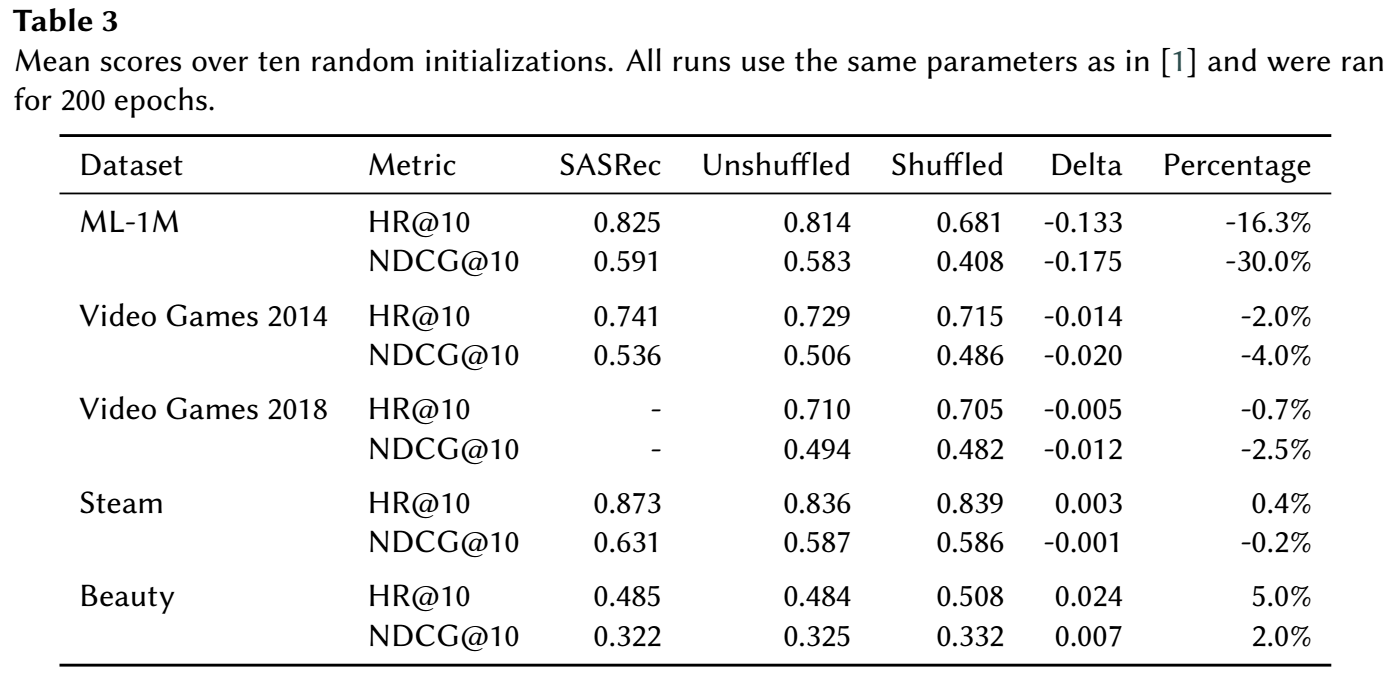
-
作者在 SASRec 的基础上, 比较了序列 unshuffled/shuffled 的前后变化情况, 可以发现, 虽然一般来说性能都有下降, 但是 ML-1M 的性能下降是最严重的.
-
我初看的时候很疑惑, 因为我得到的是和作者相反的结论, 这部恰恰说明 ML-1M 是具有很强的 '序列' 性嘛. 现在想来, 作者可能想要表达的是, 这种序列性, 并非是由用户的行为序列导致的, 而是特殊的数据收集方式导致的.
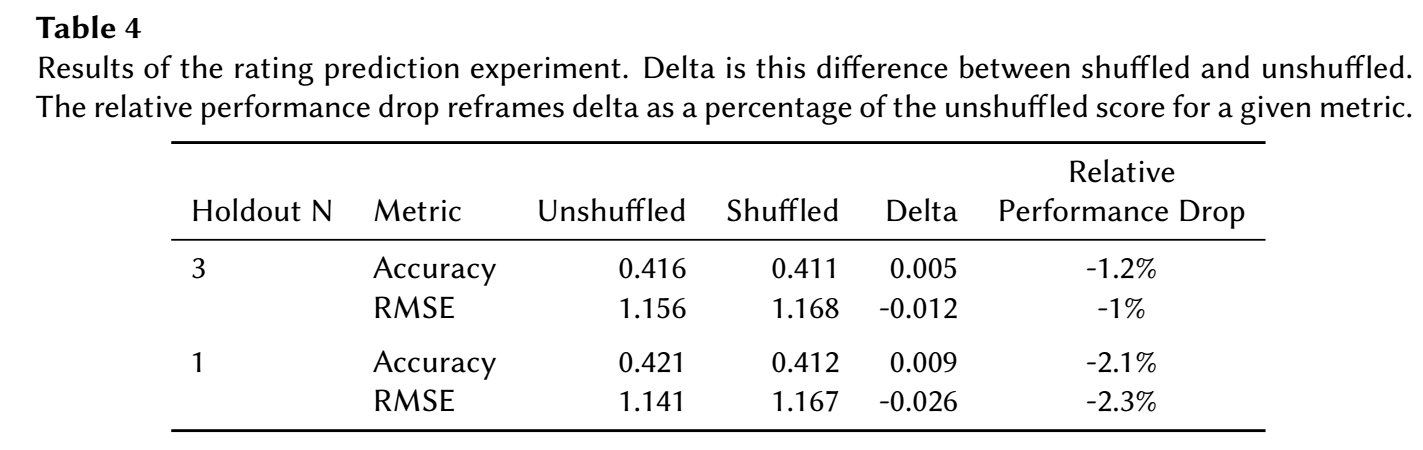
- 为了进一步证明这一点, 作者额外做了一个 rating 的预测任务: 不再预测下一个 item, 而是根据序列预测下一个 item 的 rating. 作者认为这种方式能够抵消数据收集方式带来的影响, 事实也的确如此! 在 rating 的预测任务上, 效果下降的很少.
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2023-04-24 Invariant and Equivariant Graph Networks
2022-04-24 Do We Need Zero Training Loss After Achieving Zero Training Error?
2022-04-24 Flooding-X: Improving BERT’s Resistance to Adversarial Attacks via Loss-Restricted Fine-Tuning
2022-04-24 Fake News Detection on Social Media Using Geometric Deep Learning
2021-04-24 Interval Bound Propagation (IBP)