Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited
目录
概
ID 信息, 模态信息使用方式的一个综合性的经验验证.
符号/缩写说明
- MoRec: modality-based recommendation model
- IDRec: pure ID-based model
- FM: foundation model
- NLP: natural language processing
- CV: computer vision
- ME: modality encoder
- TS: two-stage paradigm
- E2E: end-to-end training
- , items;
- , users;
Training details
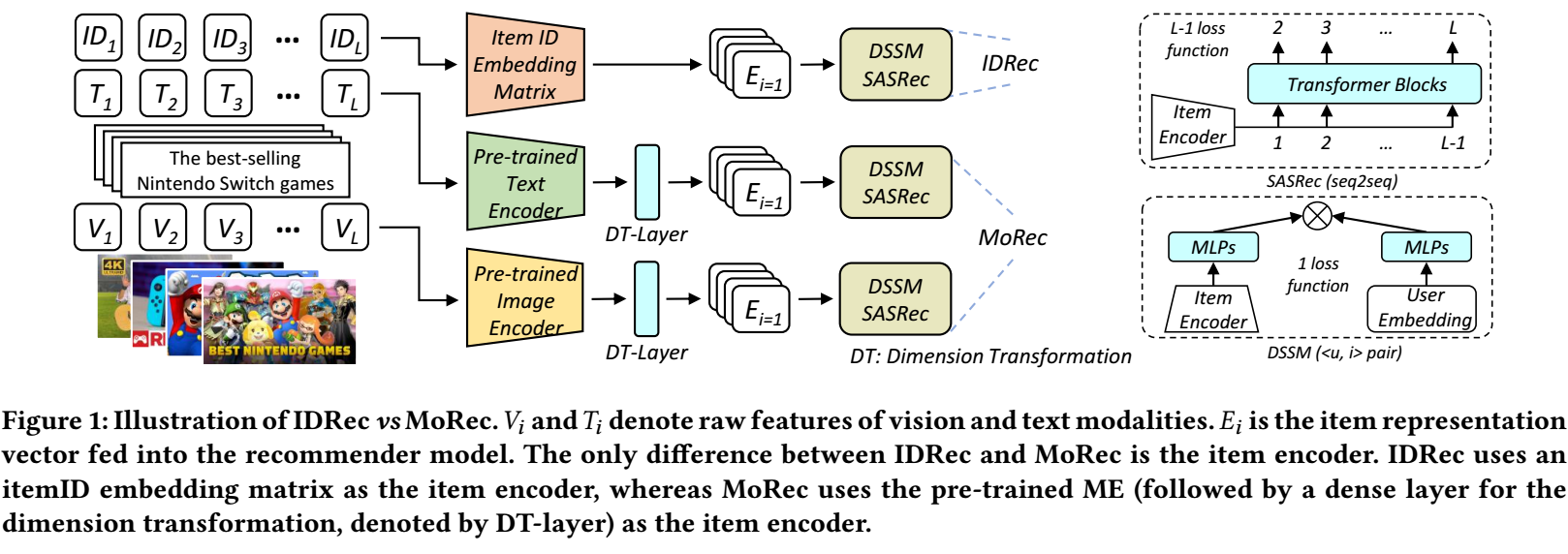
- Backbone: SASRec/DSSM, 前者是一个序列模型, 后者是一个双塔模型;
- Encoder: (仅对 MoRec 有用): BERT (small/base) | RoBERTa (small/base) | ResNet50 | Swin-T/B;
- Loss function: BCE (Binary Cross-Entropy)
- Optimizer: AdamW;
- dropout rate: 0.1
- learning rate for IDRec: ;
- learning rate for MoRec (Encoder): ;
- learning rate for MoRec (Other): ;
- Weight decay: ;
- IDRec embedding/hidden size: ;
- MoRec embedding/hidden size: 512 for DSSM, 64 for SASRec;
- Batch size: 1024 for DSSM, 128 for SASRec
注: 默认情况下, MoRec 采用的 E2E 的训练方式, 即除了 Backbone 外, Encoder 也是跟着训练的.
Datasets
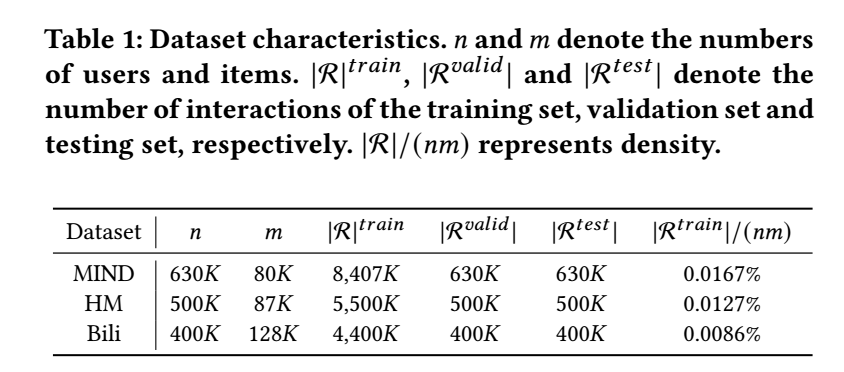

- MIND: 在训练 MoRec 的时候, 默认仅使用文本模态 (标题);
- H&M: 在训练 MoRec 的时候, 默认仅使用图像模态 (Cover image);
- Bili: 在训练 MoRec 的时候, 默认仅使用图像模态 (Cover image);
- 数据的划分依照 leave-one-out 的方式;
E2E 下 MoRec 是否优于 IDRec?
Regular setting
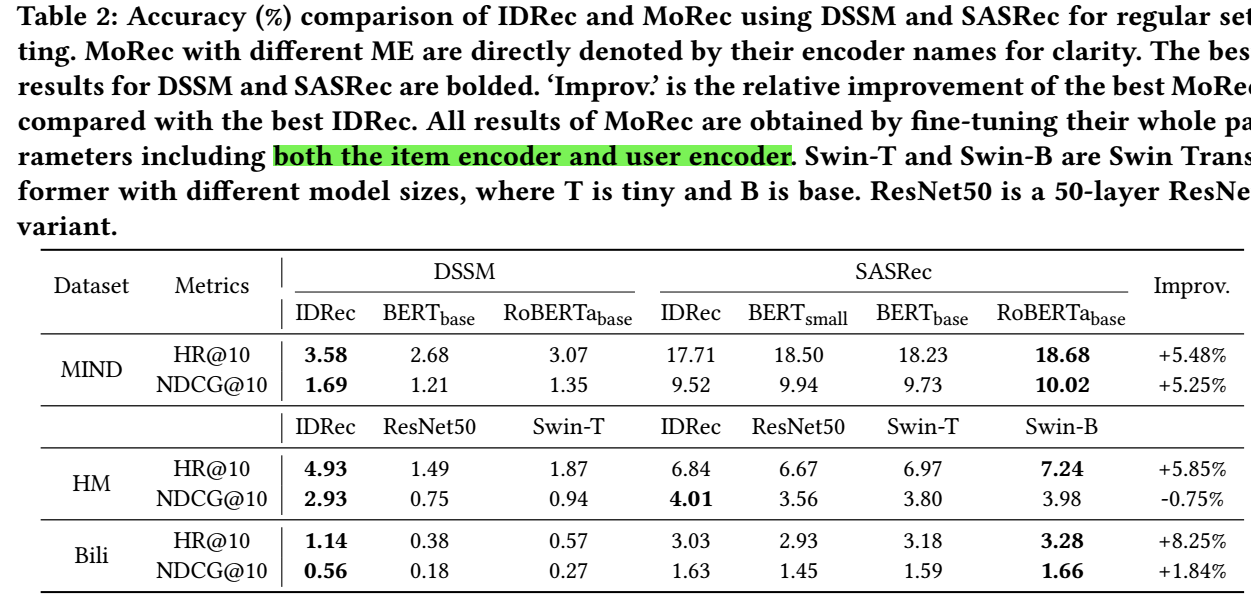
- 由上图可以发现, 通过比较强大的 encoder (如 RoBERTa/Swin-B), MoRec 是有可能赶上甚至超越 IDRec 的;
- 有意思的是, 这个结论和 backbone 有关系, DSSM 上无论用哪个 encoder 都是 IDRec 效果好, 而 SASRec 上 MoRec 就有很大机会暂优势, 感觉其实也有可能是 SASRec 和 encoder 在结构上比较一致?
- 文本信息 (MIND) 比起图片信息 (HM, Bili) 来说似乎效果更好一点, 我感觉是文本信息的噪声更少一点, 故而更容易利用和微调.
Warm setting
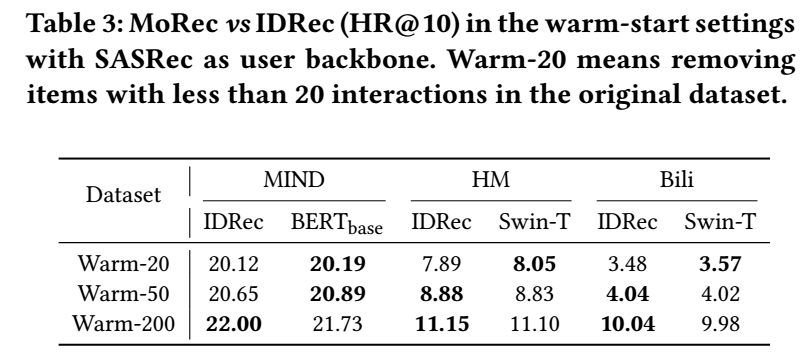
- 一般来说, 冷启动场景下, 都是 MoRec 效果好, 这里我们感兴趣的是, warm-setting 下的情况, 可以发现, 随着 item 的流行度的增加, IDRec 的优势越来越大.
越好的 encoder 带来越好的推荐效果?

- 如上图所示, 一般情况下, 模型越复杂, 参数量越多, 的确后续的推荐效果会越好, 但是也有例外, 如 BERT-small 的效果会比 BERT-base 的效果稍稍好一点.
TS versus E2E?
-
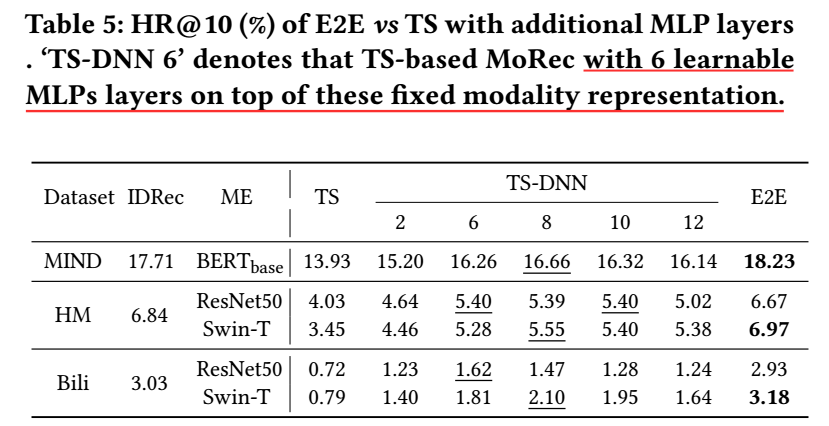
除了 E2E 外, 还有一种比较常见的模态信息的利用方式, 即 TS (two-stage), 它首先通过 encoder 提取模态特征, 然后把这些模态特征用到下游任务中 (此时, encoder 不会再进行微调), 这种方式有显著的优点, 就是节约计算资源.
-
但是如上图所示, TS 一般情况都是显著逊色于 E2E 的, 如果我们在模态特征后添加多层的 MLP 来进行映射, 则可以得到稍好的结果, 但是依然逊色于 E2E.
-
我个人认为, 这很大程度上取决于 E2E 能够通过微调记忆数据的信息, 其实是不公平的.
总结
总体看下来, 我的感觉是一般的模态特征是有很大的噪声的, 需要通过交互信息通过调整, 一种是通过 ID embedding 去记忆, 另一种是通过微调 encoder 去记忆, 但是显然这两种方式都不那么 scalable.
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2022-04-02 DropAttack: A Masked Weight Adversarial Training Method to Improve Generalization of Neural Networks
2022-04-02 A Weight Value Initialization Method for Improving Learning Performance of the Backpropagation Algorithm in Neural Networks
2020-04-02 Auto-Encoding Variational Bayes