A Tale of Two Graphs: Freezing and Denoising Graph Structures for Multimodal Recommendation
目录
概
本文主要是对 LATTICE 的改进.
FREEDOM
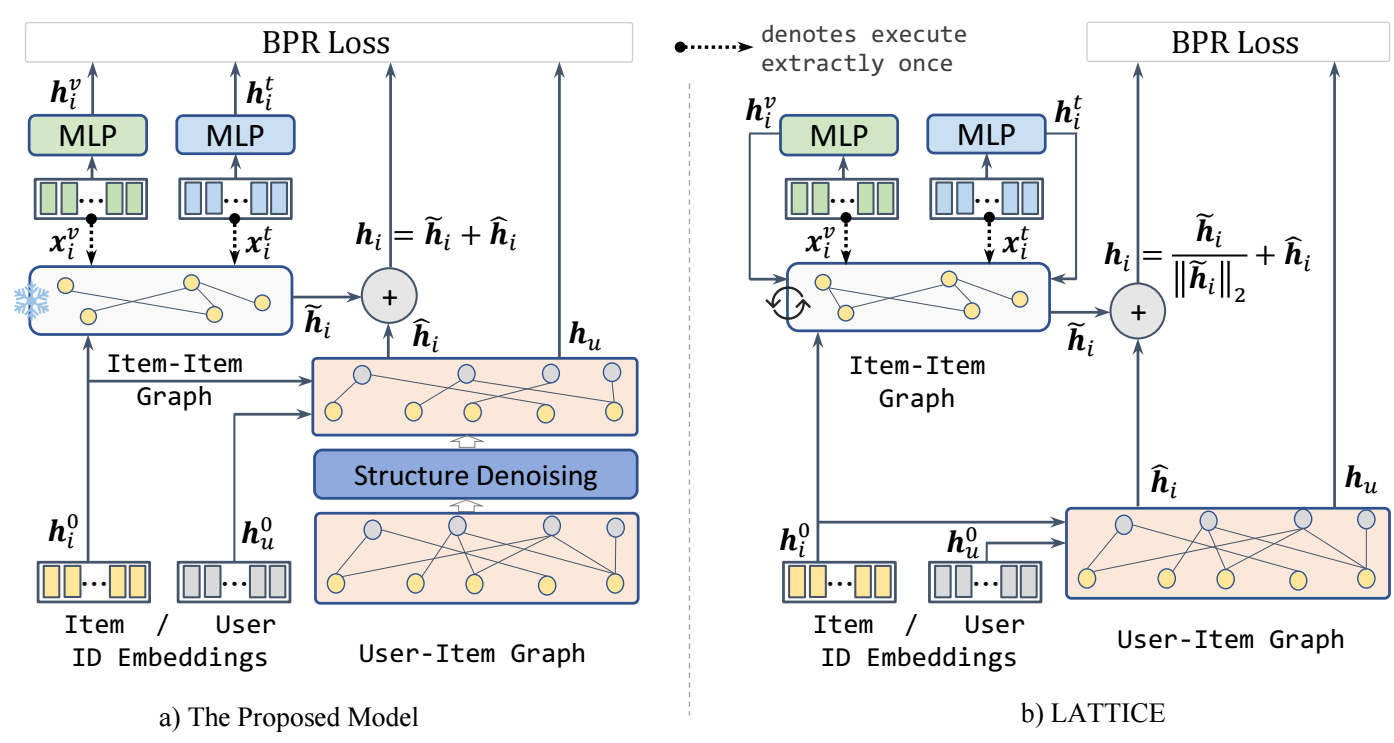
Motivation
- 如上图所示, LATTICE 动态地抽取 modality-specific 的 graph, 但是作者发现, 固定下来反而会有更好的结果:
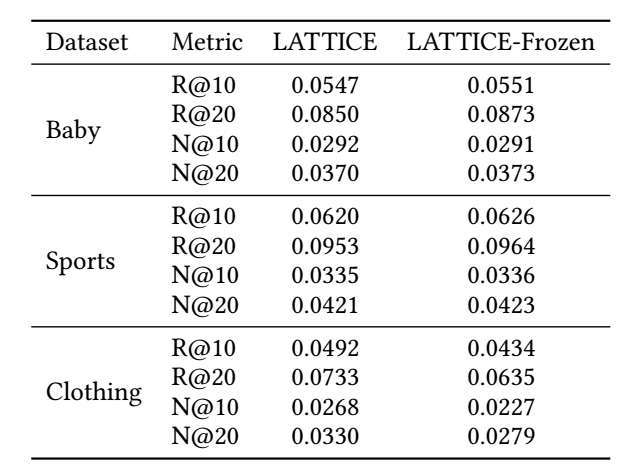
Frozen Item-Item graph
-
假设每个模态 的节点特征为 , 通过如下方式初步估计两两间的关系:
其中 ,
接着, 每个 item, 我们取相似度最高的 top- 个作为实际的邻居:最后我们再对这个稀疏化后的邻接矩阵进行标准化:
其中 为 的度矩阵.
-
最后, 通过如下方式聚合多个模态的邻接矩阵:
对于本文所考虑的仅 textual (t) + visual (v) 两个模态的信息, 作者设置为
然后 是一个认为给定的超参数 (LATTICE 中是可训练的参数, 所以从这个点来说, FREEDOM 似乎不那么直接地推广到更多地模态).
Denoising User-Item Bipartite Graph
-
其它部分, FREEDOM 和 LATTICE 差别不大, 另一个比较明显差别是对于 User-Item graph 的处理, 简而言之, FREEDOM 的 user-item 图是"动态"采样的.
-
假设 User-Item 的交互图为 , 每条边的权重的采样概率为
其中 表示节点 的度数. 故而, 一条边若是连接了高度数的节点, 则它有比较小的概率被采样到.
-
我们用 来表示采样后且标准化后的图.
Two Graphs for Learning
-
接下来, 用上面得到的两个图进行特征的提取.
-
对于模态的图, 我们用于处理 item 的 embedding:
-
接着, 对于 user-item graph, 作者利用 LightGCN 得到
-
最后我们将两部分的 embeddiing 融合在一起得到:
除此之外, 还有 modality-specific 的特征
-
最后通过如下的损失进行训练:
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix