Mining Latent Structures for Multimedia Recommendation
概
作者将模态信息转化为 graph, 再进行利用, 可以用于增强一般的协同过滤方法.
符号说明
- \(\mathcal{U}\), users;
- \(\mathcal{I}\), items, \(|\mathcal{I}| = N\);
- \(\bm{x}_u, \bm{x}_i \in \mathbb{R}^d\), user/item ID embedding;
- \(\bm{e}_i^m \in \mathbb{R}^{d_m}, m \in \mathcal{M}\), modality features of item \(i\).
LATTICE
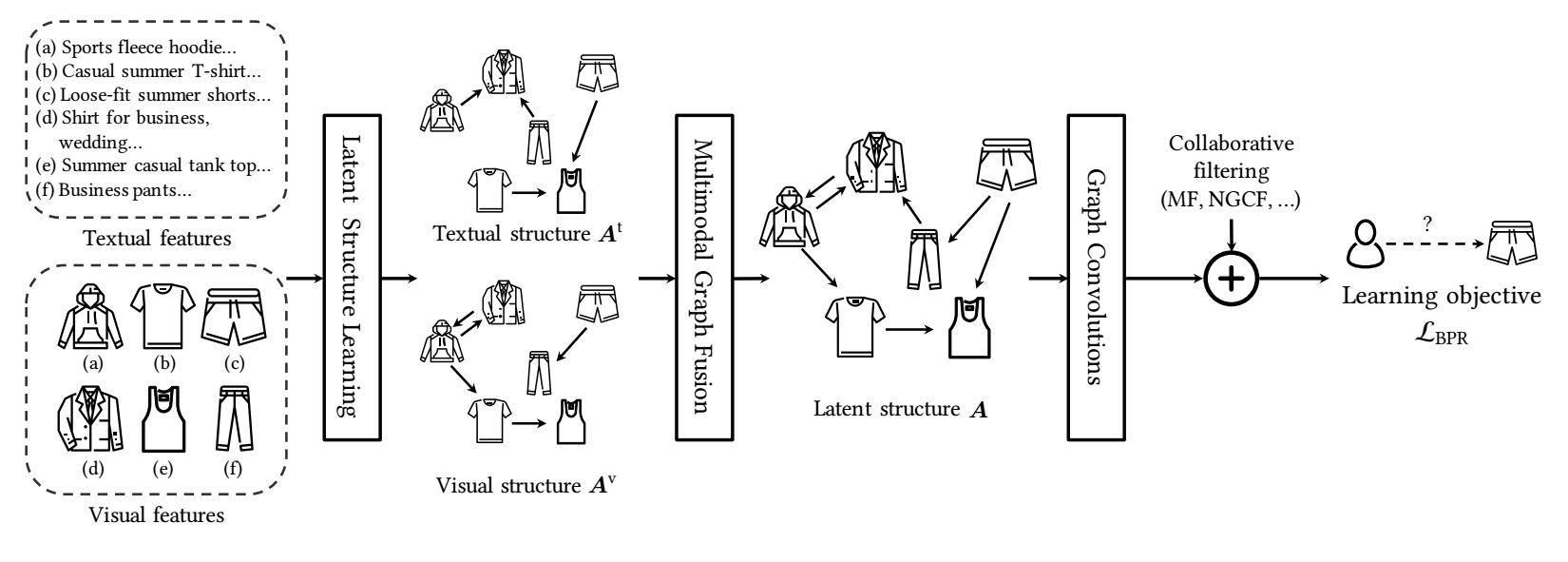
Modality-aware Latent Structure Learning
-
作者认为模态信息, 最重要的是背后的潜在的结构信息, 所以本文首先将这些结构信息提取成 graph.
-
作者用了比较普通的 kNN graph, 其中 similarity matrix \(S^m \in \mathbb{R}^{N \times N}\) 的各元素通过如下方式计算:
\[S_{ij}^m = [\frac{ (\bm{e}_i^m)^T \bm{e}_j^m }{ \|\bm{e}_i^m\| \|\bm{e}_j^m\|^2 }]_+, \]其中 \([\cdot]_+ = \max(\cdot, 0)\).
接着, 每个 item, 我们取相似度最高的 top-\(k\) 个作为实际的邻居:\[\hat{S}_{ij}^m = \left \{ \begin{array}{ll} S_{ij}^m, & S_{ij}^m \in \text{top-}k (S_i^m), \\ 0, & \text{otherwise}. \end{array} \right . \]最后我们再对这个稀疏化后的邻接矩阵进行标准化:
\[\tilde{S}^m = (D^m)^{-1/2} \hat{S}^m (D^m)^{-1/2}. \]其中 \(D^m\) 为 \(\hat{S}^m\) 的度矩阵.
-
但是这种方式有一点问题, 在实际中我们会对 modality features 进行 projection 使得它的特征和所关注的在同一个空间中, 即
\[ \tilde{\bm{e}}_i^m = W_m \bm{e}_i^m + \bm{b}_m. \]由于 \(W_m, b_m\) 都是可学习的参数, 所以 \(\tilde{\bm{e}}_i^m\) 实际上是在不断变化的. 按照上述的方式, 我们可以动态地构建邻接矩阵, 记为 \(\tilde{A}^m\).
-
最后的 modality-specific 的邻接矩阵通过如下方式加权得到:
\[A^m = \lambda \tilde{S}^m + (1 - \lambda) \tilde{A}^m, \]\(\lambda \in (0, 1)\) 是认为给定的超参数.
-
对于不同的模态 \(m \in \mathcal{M}\) 我们都可以得到这样的一个邻接矩阵, 为了最后得到总的矩阵, 我们采取如下的方式进行聚合
\[A = \sum_{m \in \mathcal{M}} \alpha_m A^m, \]其中
\[\alpha_m = \text{softmax}(w_m) \]得到.
-
接下来, 凭借该邻接矩阵, 我们可以通过如下方式进行 item 的特征提取:
\[\bm{h}_i^{(l)} = \sum_{j \in \mathcal{N}(i)} A_{ij} \bm{h}_j^{(l-1)}, \quad \bm{h}_i^{(0)} = \bm{x}_i. \]
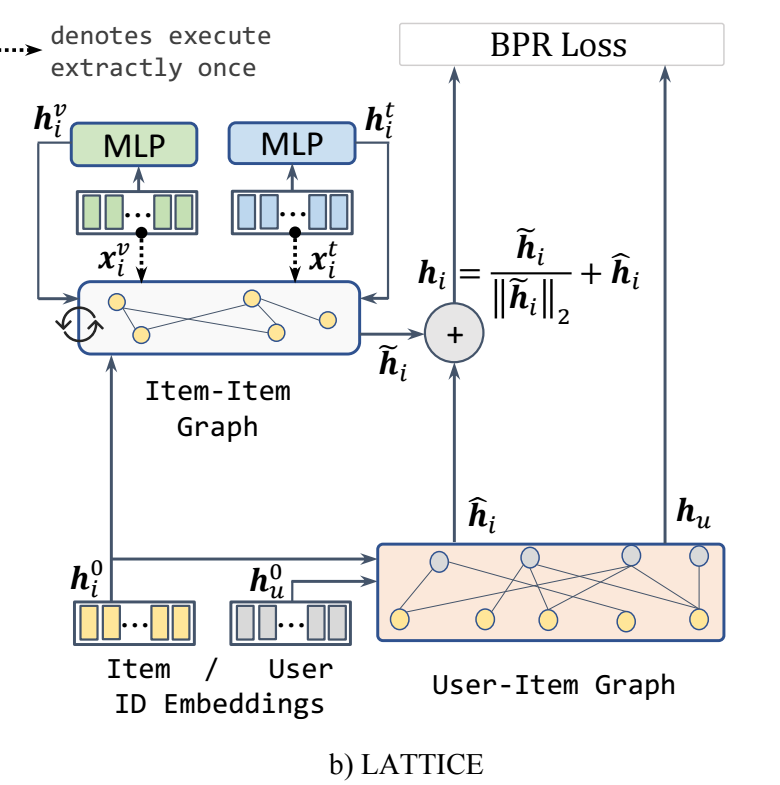
Combining with Collaborative Filtering
-
假设我们通过普通的协同过滤方法得到了
\[ \tilde{\bm{x}}_u, \tilde{\bm{x}}_i \in \mathbb{R}^d, \]LATTICE 通过如下方式去增强原有的 item embedding:
\[\hat{\bm{x}}_i = \tilde{\bm{x}}_i + \frac{ \bm{h}_i^{(L)} }{ \|\bm{h}_i^{(L)}\|_2 }. \] -
然后预测得分可以通过如下的方式计算:
\[ \hat{y}_{ui} = \tilde{\bm{x}}_u^T \hat{\bm{x}}_i. \] -
优化通过如下的 BPR 损失:
\[ \mathcal{L}_{\text{BPR}} = -\sum_{u \in \mathcal{U}} \sum_{i \in \mathcal{I}_u} \sum_{j \not \in \mathcal{I}_u} \ln \sigma(\hat{y}_{ui} - \hat{y}_{uj}). \]
代码
[official]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号