Graph-Skeleton: ~1% Nodes are Sufficient to Represent Billion-Scale Graph
概
本文提出了一种图压缩的方法, 这些方法基于一些有趣的经验观察.
符号说明
- \(\mathcal{G} = (\mathcal{V}, \mathcal{E})\), graph;
- \(\mathcal{T} = \{T_1, T_2, \ldots, T_n\}\), target nodes;
- \(\mathcal{B} := \mathcal{V} \setminus \mathcal{T} = \{B_1, B_2, \ldots, B_{|\mathcal{V}| - n}\}\), background nodes;
- \(X \in \mathbb{R}^{|\mathcal{V}| \times d}\), node features;
- \(Y \in \{0, \ldots, C-1\}^n\), target node labels.
Empirical Analysis
-
作者希望将一个大图压缩为一个轻量的容易处理的小图, 同时处理后的图尽可能不影响 target nodes 的分类准确度.
-
所以作者先做了一些经验性的验证, 来分析一个图中到底哪些点对于 target nodes 的分类是格外重要的.
-
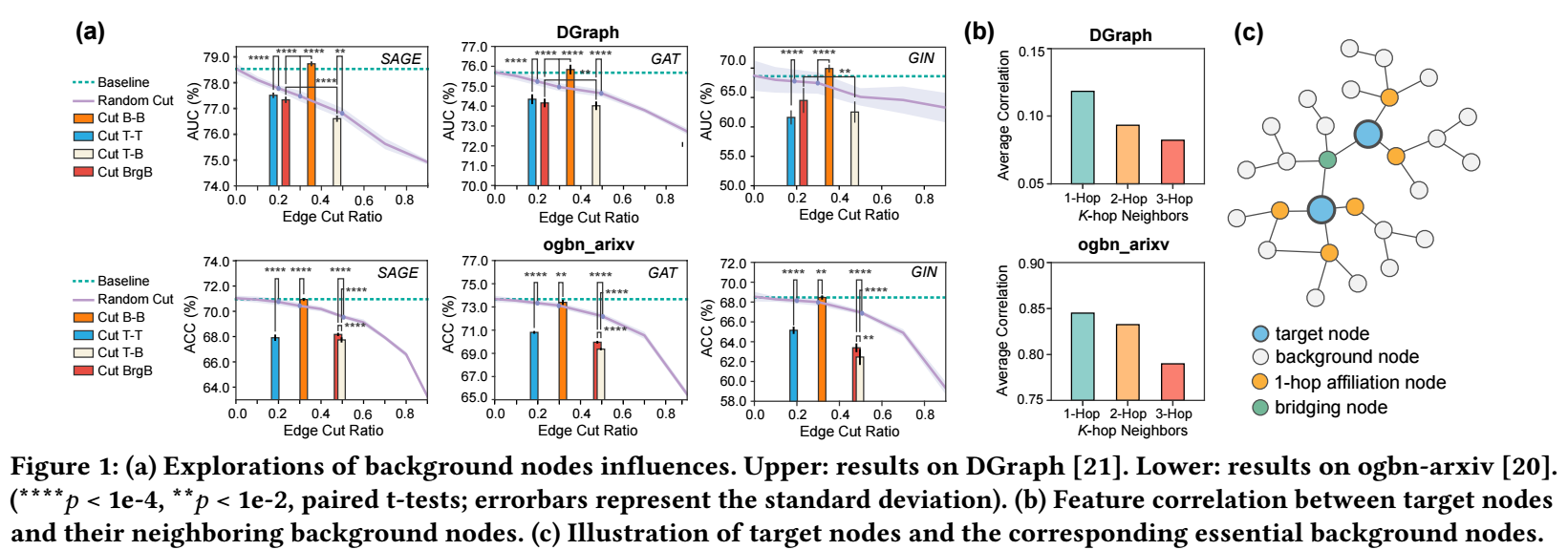
根据上面的定义, 我们已经知道除了 target nodes, 剩下的都是 background nodes, 这些 background nodes 实际上只有一小部分是重要的. 我们进行如下的切分:
- Cut B-B: 将 background nodes 间的 edge 全部抹去;
- Cut T-T: 将 target nodes 间的 edge 抹去;
- Cut T-B: 将 target-background nodes 间的 edge 抹去;
- Cut BrgB: 我们称同时连接两个不同 target 的 background 结点称为 bridging node, Cut BrgB 指的就是将 bridging nodes 和 target nodes 间的 edge 抹去;
- Rankdom Cut: 随机抹去一些边.
-
结果如下图所示:
-
可以发现:
- 抹去 background nodes 间的边有些时候甚至能够有助于 target nodes 的判别;
- 抹去 target nodes 间的 或者是 bridging nodes 和 target nodes 间的边对预测的影响很大.
-
故, 我们可以认为, 对于 target nodes 的判别最重要的是 target-target 和 target-brdB 间的关系. 此外, (b) 展示了 target nodes 和它的 k-hop neighbors 的相关系数, 随着 hop 的增加而降低.
Skeleton Graph
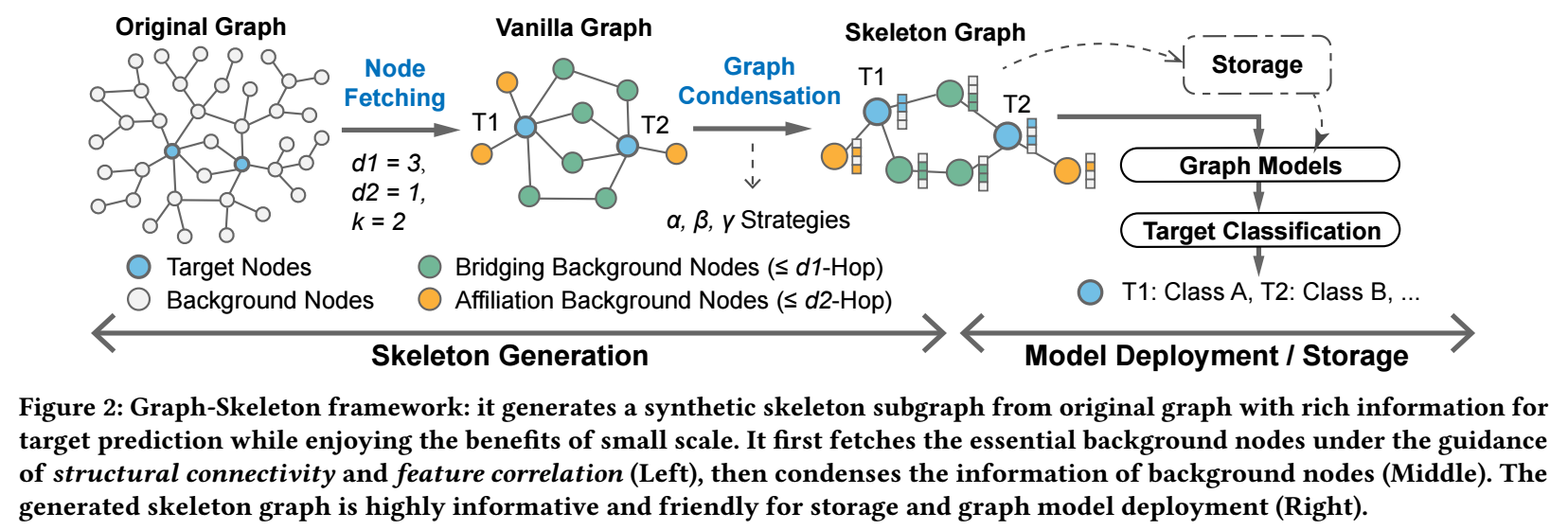
Node Fetching
- 首先, 我们需要在整个大图中确定一些重要的关键点, 按照上面的经验分析, 我们通过两个准则从 background nodes 中找寻那些关键的点:
- Structural connectivity: Bridges two or more target nodes within \(d_1\)-hop as bridging node.
- Feature corrlation: \(K\) highest correlation background nodes neighboring to solo target node within \(d_2\)-hop as affiliation nodes.
Graph Condensation
- 通过上面得到的图依然存在大量冗余的点和边, 于是本文又提出了 \(\alpha, \beta, \gamma\) 三种压缩策略 (压缩率逐步提高). 这些压缩策略主要和图的一些拓扑性质有关, 这里不多赘述.
代码
[official]

