Linear-Time Graph Neural Networks for Scalable Recommendations
概
在大图上的一种高效的训练方式.
符号说明
- \(\mathcal{V}\), node set;
- \(\mathcal{E}\), edge set;
- \(\mathcal{G} = (\mathcal{V}, \mathcal{E})\), 图;
- \(|\mathcal{E}|\), 边的数量;
- \(|\mathcal{V}| = n+m\), 结点的数量;
- \(\mathbf{A} \in \mathbb{R}^{(n + m) \times (n + m)}\), 邻接矩阵;
- \(\mathbf{D} \in \mathbb{R}^{(n + m) \times (n + m)}\), diagonal degree matrix;
- \(\mathbf{\tilde{A}} = (\mathbf{D} + \mathbf{I})^{-1/2} (\mathbf{A} + \mathbf{I}) (\mathbf{D} + \mathbf{I})^{-1/2}\), normalized adjacency matrix;
- \(\mathcal{N}(v)\) 表示结点 \(v\) 的一阶邻居;
- \(\mathbf{E} = [\bm{e}_1, \ldots, \bm{e}_n, \bm{e}_{n+1}, \ldots, \bm{e}_{n+m}]^T \in \mathbb{R}^{(n+m) \times d}\), 为 embedding matrix;
Motivation
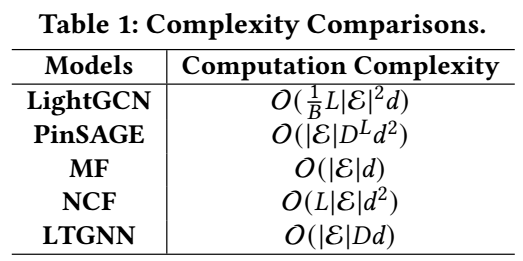
- 如上图所示, 一般的图方法, 如 LightGCN 每个 epoch 的计算复杂度与边集大小 \(|\mathcal{E}|\) 成二次关系.
- 一些近似方法如 PinSAGE 可以缓解这一点, 通过对每个结点采样 \(D\) 个邻居, 可以把复杂度将为 \(\mathcal{O}(|\mathcal{E} D^L d^2)\). 但是显然, 这种方式和 MF 的线性复杂度依然有很大的差距, 而且这种近似往往会导致一些不可避免的误差.
- 故而, 本文希望提出一种新的训练方法, 一方面降低计算复杂度, 另一方面能够降低由于采样所导致的近似误差.
LTGNN
-
LTGNN 的主要步骤分为前向和后向传播两部分.
-
Forward:
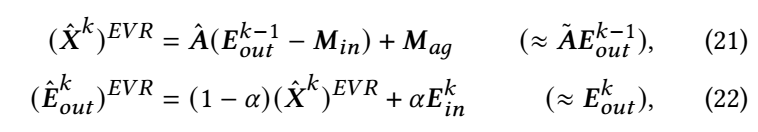
-
Backward:
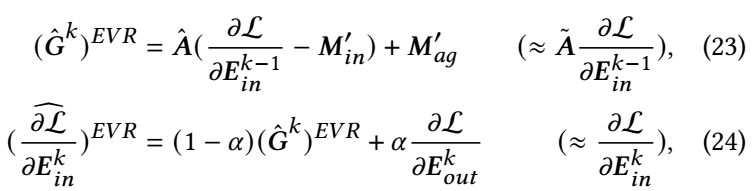
-
其中 \(EVR\) 表示 Efficient Variance Reduction. \(\mathbf{E}^k\) 代表第 \(k\) 次迭代时的 embedding. \(\mathbf{M}_{in}\) 历史的输入 embedding, 而 \(\mathbf{M}_{ag} := \mathbf{\tilde{A}} \mathbf{M}_{in}\). 诚然, 这两部分是隔一段 iterations 更新一次的, 否则又回到了 LightGCN 的复杂度了.
-
(21) 启发自 VR-GCN 和 MVS-GNN, 能够降低近似误差.
注: 实验结果, LTGNN 会比 LightGCN 还要好上一些, 这让我很费解, 因为我没看出来哪部分的设计会导致更好的性能.
代码
[原文代码]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号