GraphPrompt: Unifying Pre-Training and Downstream Tasks for Graph Neural Networks
概
统一的图预训练模型 + Prompt 微调.
符号说明
- \(G = (V, E)\), 图;
- \(\mathbf{X} \in \mathbb{R}^{|V| \times d}\), node features;
- \(\mathcal{G} = \{G_1, G_2, \ldots, G_N\}\), a set of graphs.
- \(S_v = (V(S_v), E(S_v))\), 结点 \(v\) 的子图 (\(\le \delta\) hops):\[V(S_n) = \{d(u, v) \le \delta | u \in V\}, \\ E(S_n) = \{(u, u') \in E| u \in V(S_v), u' \in V(S_v)\}. \]
GraphPrompt
-
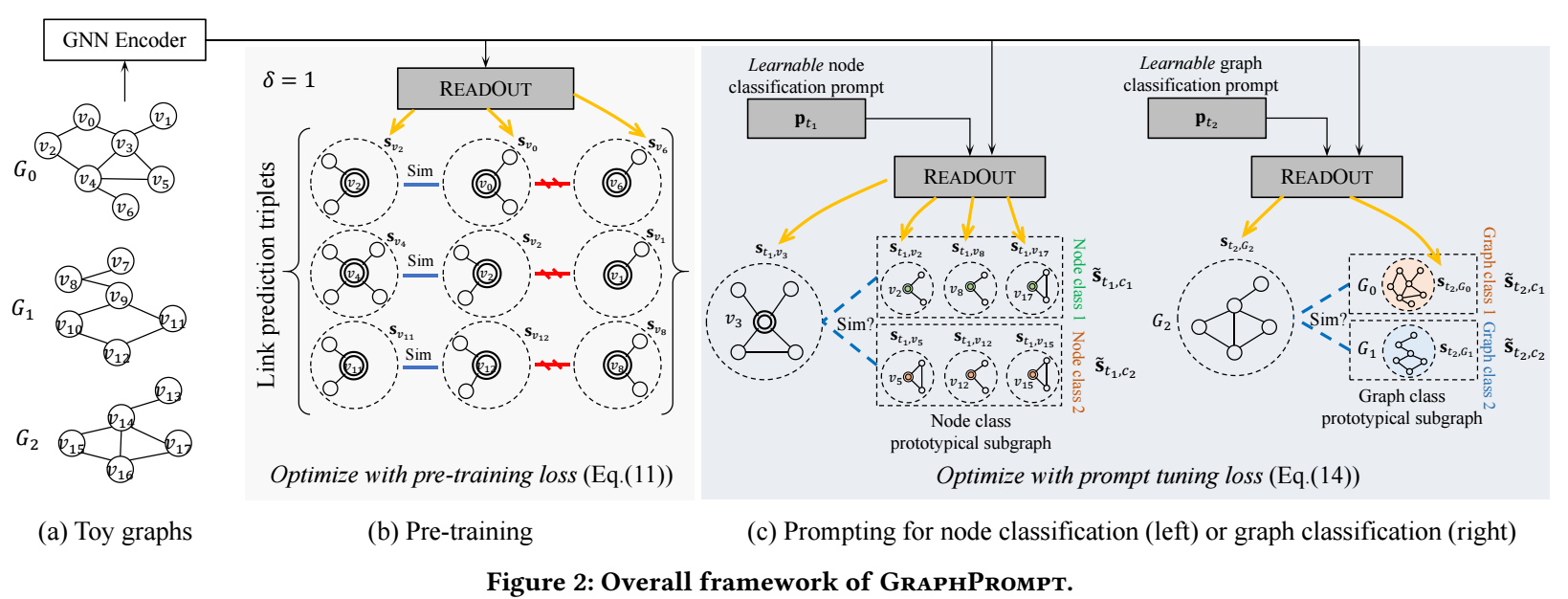
作者想通过 pretraining + prompt 的方式使得模型适用于各种下游任务, 首先需要做的是就是保持预训练模型和下游任务的预测基础, 对于图而言, 这个基础就是图的拓扑结构.
-
所以预训练任务是如此设计的:
- 对于结点 \(v\), 从邻居中采样正样本结点 \(a\), 并从非邻居中采样负样本结点 \(b\), 各自提取子图: \(S_v, S_a, S_b\);
- 预训练模型对图上特征进行转换后, 每个子图的结点通过如下方式得到:\[\mathbf{s}_x = \text{ReadOut}(\{\mathbf{h}_u: u \in V(S_x)\}), \quad x \in \{v, a, b\}. \]
- 接着, 我们通过如下损失训练:\[\mathcal{L}_{pre} = -\sum_{(v, a, b) \in \mathcal{T}_{pre}} \ln \frac{\exp(\text{sim}(\mathbf{s}_v, \mathbf{s}_a) / \tau)}{\sum_{u \in \{a, b\}} \exp(\text{sim}(\mathbf{s}_v, \mathbf{s}_u) / \tau)}. \]
-
在预训练模型的基础上怎么做图的各种下游任务呢?
-
Link prediction: 这个是自然的, 直接通过
\[\text{sim}(\mathbf{s}_v, \mathbf{s}_u) \]来判断两个结点的距离即可.
-
Node classification: 假设 k-shot 的设置, 假设结点类别集合为 \(C\), 对于每个类 \(c\in C\) 有 \(\{(v_i, \ell_i = c\}_{i=1}^k\) 对, 然后计算类内中心:
\[\tilde{\mathbf{s}}_c = \frac{1}{k} \sum_{(v_i, \ell_i) \in D, \ell_i = c} \mathbf{s_{v_i}}, \quad \forall c \in C. \]则每个结点的分类可以通过:
\[\hat{\ell}(v_j) = \text{argmax}_{c \in C} \: \text{sim}(\mathbf{s}_{v_j}, \tilde{\mathbf{s}}_c). \] -
Graph classification: 和 node classification 类似, 同样假设 k-shot settings, 此时类内中心为:
\[\tilde{\mathbf{s}}_c = \frac{1}{k} \sum_{(G_i, L_i) \in \mathcal{D}, L_i = c} \mathbf{s_{G_i}}, \quad \forall c \in \mathcal{C}. \]然后通过如下方式分类:
\[\hat{L}(G_j) = \text{argmax} \: \text{sim}(\mathbf{s}_{G_j}, \tilde{\mathbf{s}}_c). \]
-
-
虽然现在预训练模型和任务和后续下游任务形式上保持了一致, 但是如果不加微调直接用还是太过粗糙. 于是作者希望通过 prompt 来区分不同的下游任务.
-
和预训练不同之处在于, 在 readout 部分:
\[\mathbf{s}_{t, x} = \text{ReadOut}(\{\mathbf{p}_t \odot \mathbf{h}_v: v \in V(S_x)\}). \] -
微调的损失为 (针对 node/graph classification):
\[\mathcal{L}_{prompt}(\mathbf{p}_t) =-\sum_{(x_i, y_i) \in \mathcal{T}_t} \ln \frac{ \exp(\text{sim}(\mathbf{s}_{t, x_i}, \tilde{\mathbf{s}}_{t, y_i}) / \tau) }{ \sum_{c \in Y} \exp(\text{sim}(\mathbf{s}_{t, x_i}, \tilde{\mathbf{s}}_{t, c}) / \tau) }. \]
代码
[official]

