GPT-GNN: Generative Pre-Training of Graph Neural Networks
概
比较早的一篇图预训练模型.
符号说明
- \(G = (\mathcal{V}, \mathcal{E}, \mathcal{X})\), 某个图, 其中 \(\mathcal{X}\) 表示结点的属性空间.
- \(X, E\), node attributes, edges.
GPT-GNN
-
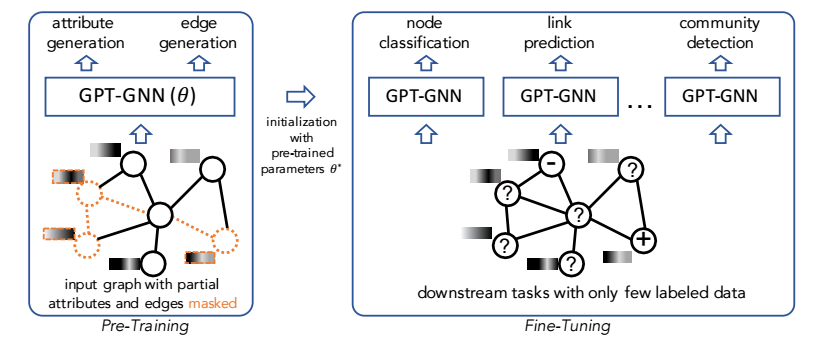
GPT-GNN 的思路就是模仿 GPT 采取自回归的生成任务 (结点属性和边) 来预训练:
\[\log p_{\theta}(X, E) = \sum_{i=1}^{|\mathcal{V}|} \log p_{\theta}(X_i, E_i | X_{<i}, E_{< i}), \]这里 \(X_i, E_i\) 分别表示结点 \(i\) 的属性和它上的边, \(X_{<i}\) 表示序号在 \(i\) 之前的结点, \(E_{<i}\) 表示 \(X_{<i}\) 的子图的边.
-
注: 为了采用自回归的方式, 需要将图序列化, 即序号为结点编号, 在训练中, 作者随机选择顺序 (相当于希望忽视顺序信息).
-
一个主要问题是如何建模:
\[p_{\theta}(X_i, E_i | X_{<i}, E_{< i}), \]毕竟 \(X_i, E_i\) 不是独立的.
-
作者采取如下的拆分:
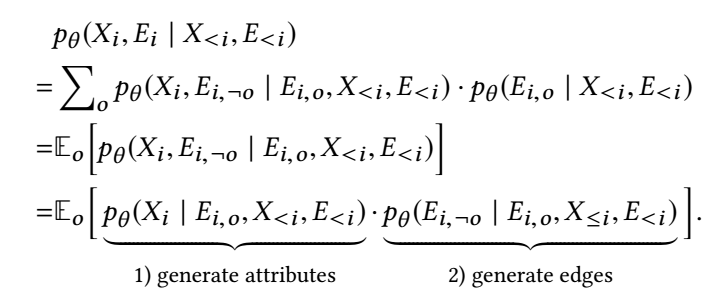
-
所以整个过程可以拆分为:
- 根据先前的 \(X_{<i}, E_{<i}\) 和(当前结点)观测到的边 \(E_{i,o}\) 预测 \(i\) 的属性 \(X_i\);
- 有了 \(X_i\) 再去预测 \(i\) 的边.
-
为了高效计算, 作者将两个任务独立开来考虑:
- Attribute Generation Nodes: 知道边但 mask 掉属性;
- Edge Generation Nodes: 知道属性但 mask 掉边.
-
假设我们对两种类型分别编码得到: \(h^{Attr}\) 和 \(h^{Edge}\), 我们的损失为:
\[\mathcal{L}_i^{Attr} = Distance(Dec^{Attr}(h_i^{Attr}), X_i), \\ \mathcal{L}_i^{Edge} = -\sum_{j^+ \in E_{i, \lnot o}} \log \frac{ \exp(Dec^{Edge}(h_i^{Edge}, h_{j^+}^{Edge})) }{ \sum_{j \in S_i^- \cup \{j^+\}} \exp(Dec^{Edge}(h_i^{Edge}, h_{j}^{Edge})) }. \]
代码
[official]

