Knowledge Distillation from A Stronger Teacher
概
用 Pearson correlation coefficient 来替代一般的 KL 散度用于蒸馏.
DIST
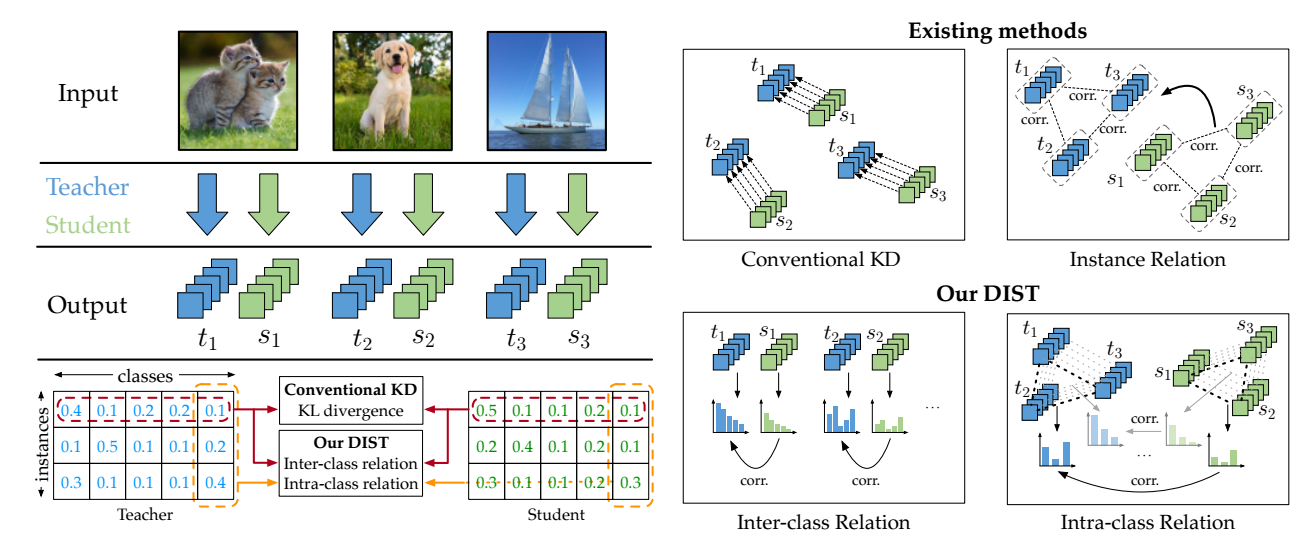
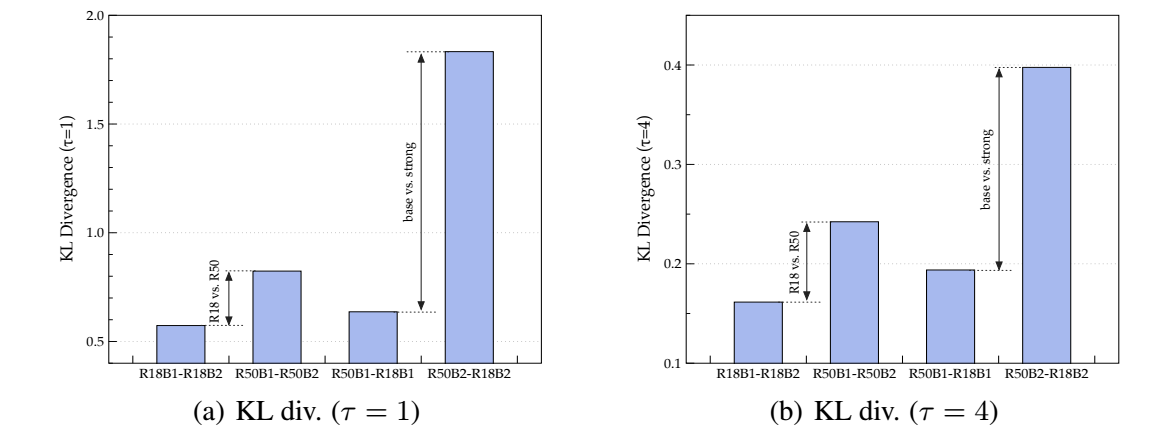
- 首先, 作者针对不同的 model size ResNet18, Resnet50 和不同的训练策略 B1, B2 (B2 更复杂一点, 通过 B2 训练得到的模型一般效果更好一点) 训练得到不同的教师模型. 比较在这些不同的教师模型的监督下, 学生模型训练后和教师模型的 KL 散度的差异:
-
可以发现, 有如下的结论:
- 在相同的策略下, 教师和学生的模型差距越大, 最后的 KL 散度越大;
- 在相同的模型大小下, 用更复杂的策略训练得到差距更大.
-
需要知道, KL 散度越大, 说明学生难以模仿教师的输出, 这启发作者抛弃传统的 KL 散度, 转向更简单更一般的对齐方式.
-
KL 散度要求学生的输出分布和教师的分布尽可能一致, 而 DIST 仅要求二者是线性相关即可, 即:
尽可能小.
-
假设 分别为教师和学生模型的输出概率, 分别是 batchsize 和 类别数目.
-
DIST 考虑类间和类内的线性相关性, 即:
-
最后的训练学生模型的损失为:
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2022-09-26 node2vec: Scalable Feature Learning for Networks
2021-09-26 ∞-former: Infinite Memory Transformer
2020-09-26 Learning a Similarity Metric Discriminatively, with Application to Face Verification