DE-RRD: A Knowledge Distillation Framework for Recommender System
概
知识蒸馏应用于推荐系统 (同时迁移隐层 + 输出层特征).
DE-RRD
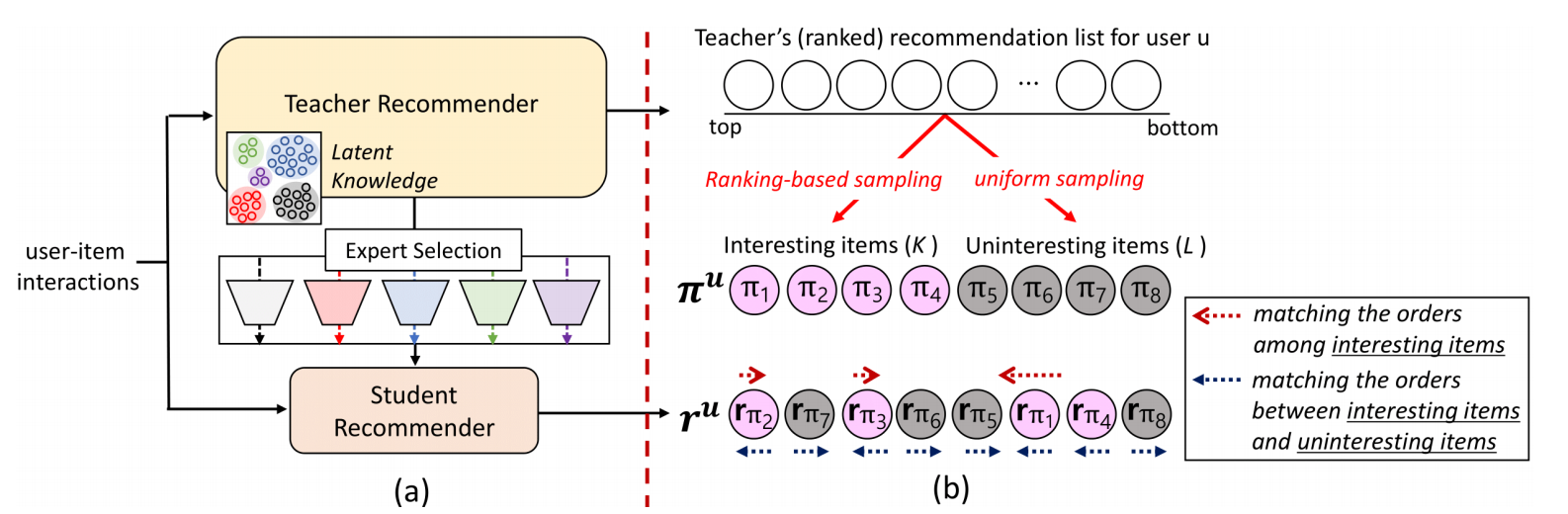
- DE-RRD 主要包括两个部分, 一个是对中间隐变量的信息迁移, 另一个则是对教师给出的排名的一个利用.
Distillation Experts (DE)
-
DE 部分是利用多个专家模型来迁移教师的隐变量的信息, 用多个的原因是作者认为一个的能力有限.
-
对于每一个, 专家就是一个普通的网络 \(E(\cdot)\). 假设 \(h_t(\cdot)\) 返回教师模型的隐变量, \(h_s(\cdot)\) 返回学生模型的隐变量. \(E(h_s(u))\) 将 \(h_s(u)\) 映射到和教师模型一个空间.
-
倘若总共有 \(M\) 个专家, DE 通过一个 selection network \(S\) 来计算每个的重要性:
\[\mathbf{e}^u = S(h_t(u)), \\ \alpha_m^u = \frac{\exp(e_m^u)}{\sum_{i=1}^M \exp(e_i^u)}, \quad m = 1,2,\ldots, M. \] -
然后, 我们要求:
\[\mathbf{s}^u \sim \text{Multinouli}_M (\{\alpha_M\}), \\ \mathcal{L}(u) = \|h_t(u) - \sum_{m=1}^M s_m^u \cdot E_m(h_s(u)) \|_2, \]这部分要求通过权重重加权后的学生近似于教师的. 这里具体的系数 \(\mathbf{s}^u \in \{0, 1\}^{M}\) 采样自多重伯努利分布 (通过 gumbel-softmax 实现), 越重要的专家信息与需要被保留 (我认为这是一个多余的设计).
Relaxed Ranking Distillation (RRD)
-
首先, 让学生模型去模仿教师模型的排名是一个被广泛接受的蒸馏方法, 但作者认为这种方式对于学生的难度有点大. 所以 RRD 希望只正对那些少部分的更有意义的 items, 然后模仿他们的排名. 具体的, RRD 会依据教师模型给出的排名, 然后按照:
\[p_k \propto e^{-k/\tau} \]来采样 \(K\) 个 interesting items, 然后再 均匀采样 \(L\) 个 uninteresting items.
-
接着, 定义如下的概率 (我不知道怎么推出来的):
\[p(\bm{\pi}_{1:K}^u|\mathbf{r}^u) = \prod_{k=1}^K \frac{\exp(r_{\pi_i}^u)}{\sum_{i=k}^K \exp(r_{\pi_i}^u) + \sum_{j=K}^{K+L} \exp(r_{\pi_j}^u)}. \] -
然后极大似然优化.
代码
[official]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号