Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System
概
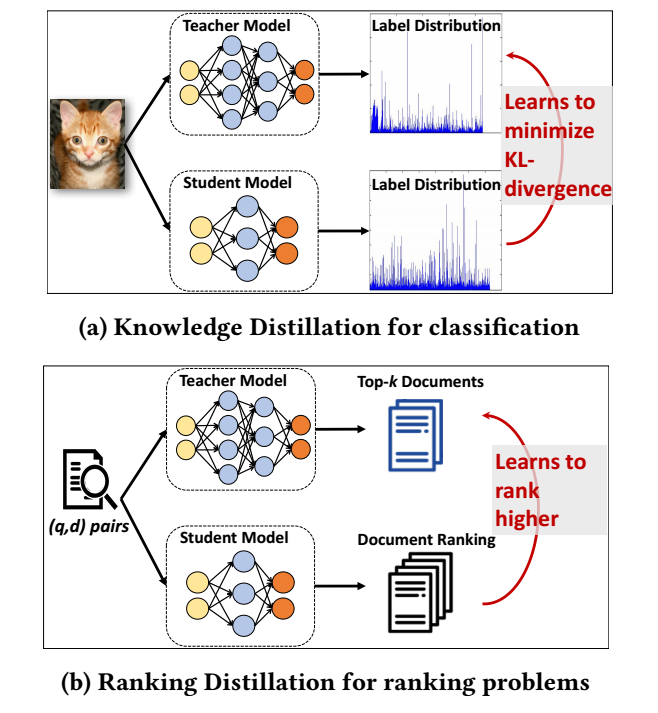
在分类问题上, 知识蒸馏一般利用最后的 logits, 本文希望学生和教师对 top-K 的 items 的排序能够尽可能保持一致, 而非局限在 logits 的数值上.
符号说明
- \(\mathcal{Q} = \{q_1, \cdots, q_{|\mathcal{Q}|}\}\), queries;
- \(\mathcal{D} = \{d_1, \cdots, d_{|\mathcal{D}|}\}\), documents;
- \(y_d^{(q)}\), query-document pair \((q, d)\) 的相关度
Ranking Distillation
-
在检索或者推荐领域, 我们的目的就是训练一个模型 \(M\), 然后
\[\hat{y}_d^{(q)} := M(q, d; \theta) \]来预测 query \(q\) 和 document \(d\) 的一个相关度, 根据预测的相关度来预测和推荐.
-
一般来说, 模型越复杂, 它的拟合能力越强, 效果就可能越好, 当然代价往往是更昂贵的计算(存储)开销. 知识蒸馏就是一个比较实用的方法将教师模型 (大一点模型) 的信息迁移到 学生模型 (小一点的模型)上.
-
在分类领域, 通常要求学生模型的输出分布尽可能符合教师模型的, 但是对于检索和推荐, 其实具体的数值并非如此关键. 我们只要求学生模型对一串文档的排序尽可能和教师模型的一致, 那么它的性能就能不错. 这实际上是减弱了对学生模型的约束 (可以认为, 让学生模型的输出分布和教师模型的一致的约束有点过于强了).
-
令 \(M_T\) 为一个规模较大的教师模型, 我们希望把它的一些重要信息迁移到学生模型 \(M_S\) 之上. 具体通过如下损失实现:
\[\mathcal{L}(\theta_S) = (1 - \alpha) \mathcal{L}^R (\bm{y}, \hat{\bm{y}}) + \alpha \mathcal{L}^D (\bm{\pi}_{1\ldots K}, \hat{\bm{y}}). \] -
前者是正常的损失, 后者是要求学生模型的打分 \(\hat{\bm{y}}\) 符合教师模型所给出的 top-K 的排序 \(\bm{\pi}_{1\ldots K}\). 它的具体的设计如下:
\[\mathcal{L}^D(\pi_{1\ldots K, \hat{\bm{y}}}) = - \sum_{r=1}^K w_r \cdot \log P(rel=1|\hat{y}_{\pi_r}) = - \sum_{r=1}^K w_r \cdot \log \sigma(\hat{y}_{\pi_r}). \] -
本文比较关键的部分就是关于 \(w_r\) 的设计, 显然不同的位置的重要性应该是不同的 (一般来说越前面的越重要).
-
作者首先采用的是,
\[w_r^a \propto e^{-r/\lambda}, \quad \lambda \in \mathbb{R}_+, \]该权重随着排名的下降而下降, 且可以通过超参数 \(\lambda\) 来控制下降的速率.
-
上面的问题是这种方式是仅考虑教师而不考虑学生的权重计算方式. 打个比方, 比如对于 item \(d\), 学生和教师给它的排名是一致的, 那么其实它所对应的损失就不需要很大的权重 (因为已经足够好了).
-
假设学生模型对于 item \(\pi_r\) 给出的排名是 \(\hat{r}_{\pi_r}\), 则另一种权重计算方式为:
\[w_r^b = tanh(\max(\mu \cdot (\hat{r}_{\pi_r} - r), 0)) \in [0, 1], \]显然它只会对那些学生模型排名大于教师模型排名的 item 基于非零的权重.
-
我们也可以将二者混合得到:
\[w_r = (w_r^a \cdot w_r^b) / (\sum_{i=1}^K w_i^a \cdot w_i^b). \] -
注: 学生的排名是需要在线计算的, 这个就比较费时, 所以作者采用的是一种近似的算法:

代码
[official]

