REALM Retrieval-Augmented Language Model Pre-Training
概
赋予生成模型检索的能力.
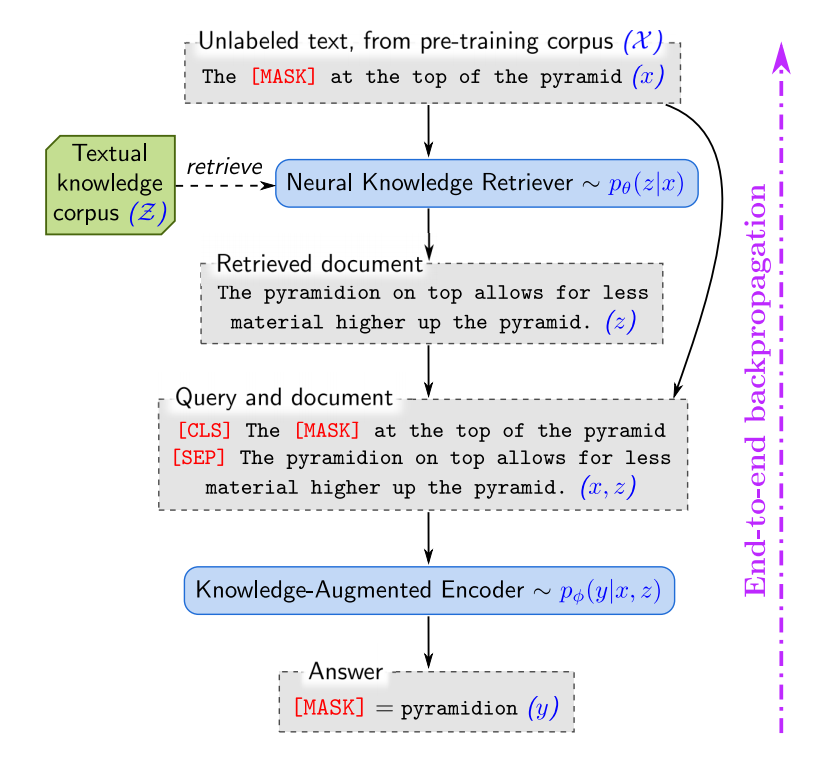
REALM
-
如上图所示, 作者希望实现这样一个事情: 给定一个'预测'任务, 如 "The [MASK] at the top of the pyramid", 作者不希望像一般的模型一样直接从条件分布 \(p(y|\bm{x})\) 中采样. 而是
- 首先通过 \(\bm{x}\) 检索得到相似的文档 \(\bm{z}\);
- 然后通过 \((\bm{x}, \bm{z})\) 一起得到 \(p_{\phi}(y|\bm{x}, \bm{z})\).
-
我们可以将检索的过程建模成另一个条件模型:
\[p_{\theta}(\bm{z}|\bm{x}) := \frac{\exp f(\bm{x}, \bm{z})}{ \sum_{\bm{z}'} \exp f(\bm{x}, \bm{z}')}, \]其中
\[f(\bm{x}, \bm{z}) = \text{Embed}_{\text{input}}(\bm{x})^T \text{Embed}_{\text{doc}}(\bm{z})^T, \]为一 score function.
-
类似的, \(p_{\phi}(y|\bm{x}, \bm{z})\) 采用另一个 encoder 去建模.
-
整体训练依旧采取普通的极大似然:
\[\max_{\theta, \phi} \quad p(y|\bm{x}) = \sum_{\bm{z}} p_{\phi}(y|\bm{z, x}) p_{\theta}(\bm{z|x}), \]当然了, 我们不可能真的直接计算这个边际密度函数, 实际中, 我们根据 \(p_{\theta}(\bm{z|x})\) 得到 Top-k 的文档, 然后进行训练.
-
一个容易存在的疑惑是, 这种方式是否能够训练好 \(\theta\), 作者给出了一种解释:
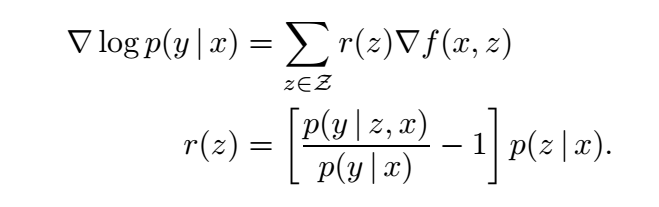
导数会促使 \(p(y|\bm{z, x}) > p(y|\bm{x})\) 的文档和 \(\bm{x}\) 的 score \(f(\bm{x, z})\) 变大.
-
此外, 在实际中, 我们还需要如下的一些操作以保证充分训练:
- Salient span masking: 即尽可能多 mask 比较重要的 spans;
- Null document: 有些 masking 的任务不需要检索, 我们可以加入 numm document \(\empty\);
- Prohibiting trivial retrievals: 如果预训练的 corpus 和检索的库是相同的, 显然会导致平凡解, 在训练中需要剔除这部分信息;
- Initialization: \(\theta\) 需要一个合适的初始化, 以避免生成过程直接无视 retriever. 作者是采取 BERT pre-training.
-
另外, retriever 采取的是异步的更新方式.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号