Neural Attentive Session-based Recommendation
概
Session 推荐的经典之作.
符号说明
- \(\mathbf{x} = [x_1, x_2, \ldots, x_{t-1}, x_t]\), session;
NARM
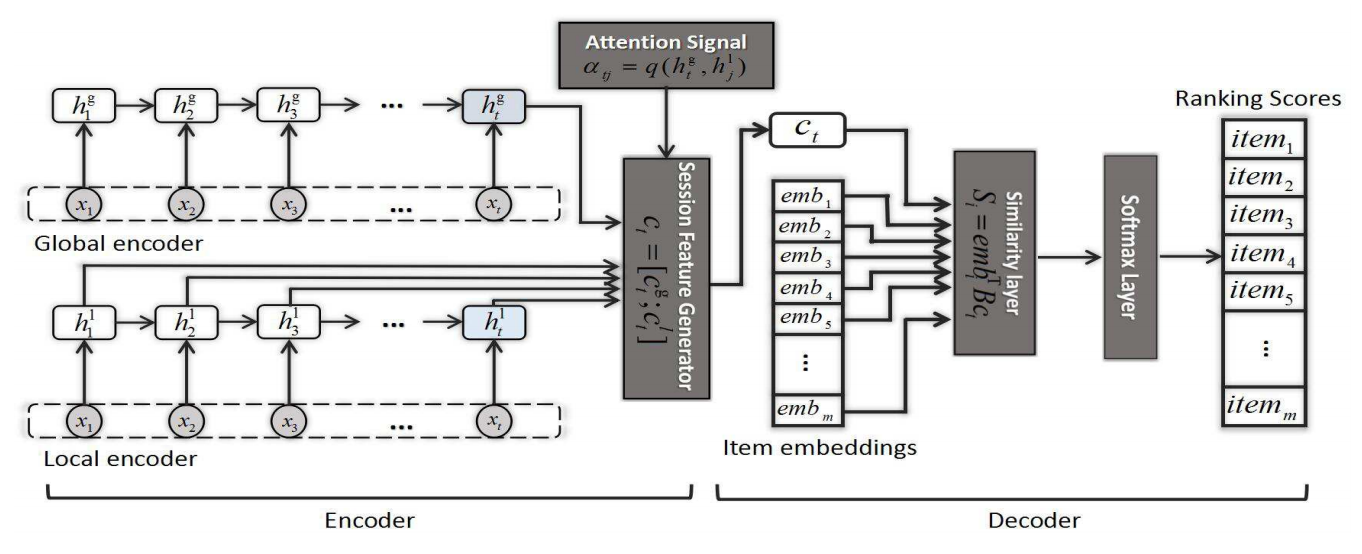
-
session \(\mathbf{x}\) 分别经过 local 和 global encoder 得到特征表示:
\[\bm{c}_t = [\bm{c}_t^g; \bm{c}_t^l]. \] -
概特征表示和其它的 items 的 embddings 一起, 通过如下方式计算 score:
\[S_i = emb_i^T \bm{B} \bm{c}_t, \]其中 \(\bm{B}\) 是可训练的参数.
-
该 score 可以用于 Top-K 的推荐, 以及通过交叉熵用于训练模型:
\[L(p, q) = -\sum_{i = 1}^m p_i \log(q_i), \]其中 \(p\) 表示真实的分布, 二 \(q\) 是 score softmax 后的概率.
Global Encoder
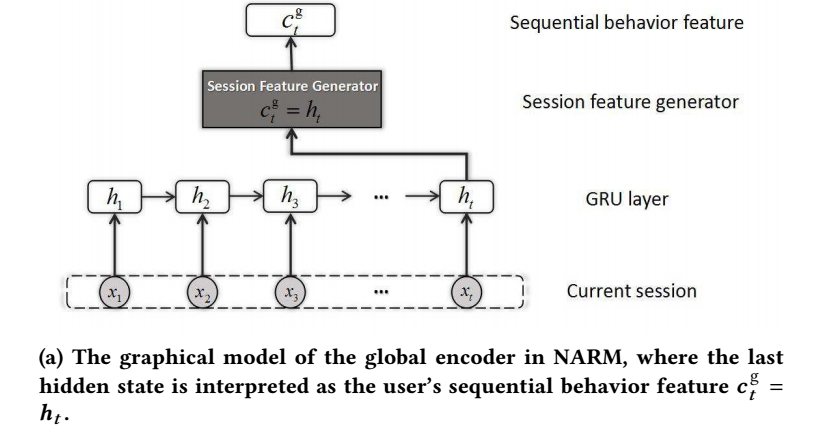
-
作者采用 GRU 来提取 global 的特征:
\[\bm{h}_t = (1 - \bm{z}_t) \bm{h}_{t-1} + \bm{z}_t \hat{\bm{h}}_t, \\ \bm{z}_t = \sigma(\bm{W}_z \bm{x}_t + \bm{U}_z \bm{h}_{t-1}), \\ \hat{\bm{h}}_t = tanh(\bm{W}\bm{x}_t + \bm{U} (\bm{r} \odot \bm{h}_{t-1})), \\ \bm{r}_t = \sigma(\bm{W}_r \bm{x}_t + \bm{U}_r \bm{h}_{t-1}). \] -
最后
\[\bm{c}_t^g = \bm{h}_t. \]
Local Encoder
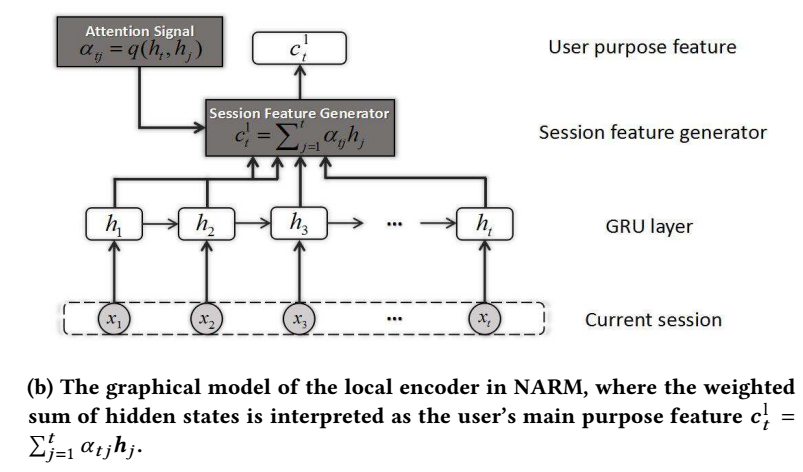
-
和 global 的架构基本相同, 除了:
\[\bm{c}_t^l = \sum_{j=1}^t \alpha_{tj} \bm{h}_j \]为不同特征的加权和 (话说这个能叫 local 吗).
-
其中
\[\alpha_{tj} = q(\bm{h}_t, \bm{h}_j) = \bm{v}^T\sigma(\bm{A}_1 \bm{h}_t + \bm{A}_2 \bm{h}_j), \]\(\bm{v}, \bm{A}_1, \bm{A}_2\) 均为可训练的参数.

