Efficient Graph Generation with Graph Recurrent Attention Networks
概
一种图的生成方法.
符号说明
- \(G = (V, E)\), 图;
- \(\pi \in \prod\), ordering, 某种 permutation;
- \(A^{\pi}\), 根据 ordering \(\pi\) 所唯一确定的邻接矩阵;
- \(p(G) = \sum_{\pi \in \prod} p(G, \pi) = \sum_{\pi \in \prod} p(A^{\pi})\)
GRAN

-
我们希望根据已有的一些图 \(G_1, G_2, \ldots\) 来建模 \(p(G)\) 并从中采样图, 这实际上要要求我们建模 \(p(A^{\pi})\).
-
本文首先针对的是无向图, 即此时 \(A^{\pi}\) 应当是对称的, 于是, 我们所需要做的实际上只有构建它的下三角矩阵 \(L^{\pi}\) 了, 一旦得到 \(L^{\pi}\), 我们便可以得到 \(A^{\pi} = L^{\pi} + {L^{\pi}}^T\) (without self-loop).
-
GRAN 每一层生成 \(L^{\pi}\) 的开始 B 行, 即
\[L_{\bm{b}_1}^{\pi}, L_{\bm{b}_2}^{\pi}, L_{\bm{b}_3}^{\pi}, \cdots \]其中 \(\bm{b}_1 = \{1, 2, \ldots, B\}, \bm{b}_2 = \{B+1, B+2, \ldots, 2B\}, \bm{b}_t = \{B(t-1) +1, \ldots, Bt\}\).
-
于是乎, 我们实际上要建模的是:
\[p(L^{\pi}) = \prod_{t=1}^T p(L_{\bm{b}_t}^{\pi}| L_{\bm{b}_1}^{\pi}, \cdots, L_{\bm{b}_{t-1}}^{\pi}). \] -
建模 \(L_{\bm{b}_t}^{\pi}\) 具体的做法如下:
-
生成初始的 node representations:
\[h_{\bm{b}_i}^0 = WL_{\bm{b}_i}^{\pi} + b, \quad \forall i < t, \quad h_{\bm{b}_t}^0 = \bm{0}. \]这里 \(L_{\bm{b}_i}^{\pi}\) 表示 \(R^{BN}\) 的向量, 其中 \(N\) 表示人为给定的最大的 graph size.
-
我们利用 GNN 来建模 augmented graph \(G_t\):

其中 \(h_i^r\) 是经过 \(r\) 轮后的隐变量便是, \(x_i\) 为 binary mask 表示 node \(i\) 是否在之前的 \(B(t-1)\) 个结点中. \(\mathcal{N}(i)\) 是 node \(i\) 的一阶邻居, 我不确定是不是根据 \(G_{t-1}\) 定义的. -
接着, 我们可以通过 mixture Bernoulli distributions 来建模:
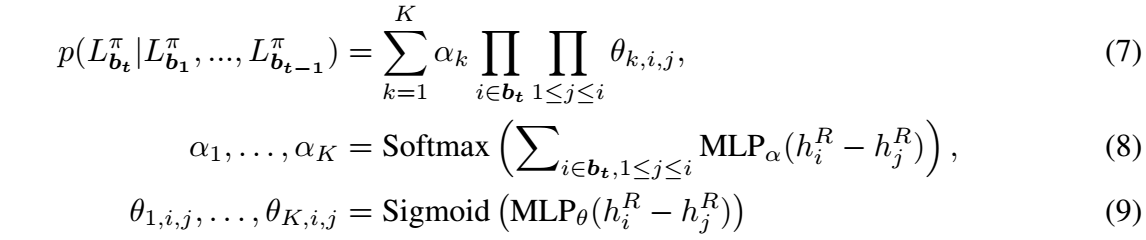
-
-
优化那一块请回看原文.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号