Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
概
序列推荐的经典之作, 将卷积用在序列推荐之上.
符号说明
- \(\mathcal{U} = \{u_1, u_2, \cdots, u_{|\mathcal{U}|}\}\), users;
- \(\mathcal{I} = \{i_1, i_2, \cdots, i_{|\mathcal{I}|}\}\), items;
- \(\mathcal{S}^{u} = (\mathcal{S}_1^u, \cdots, \mathcal{S}_{|\mathcal{S}^u|}^u)\), sequence;
Caser
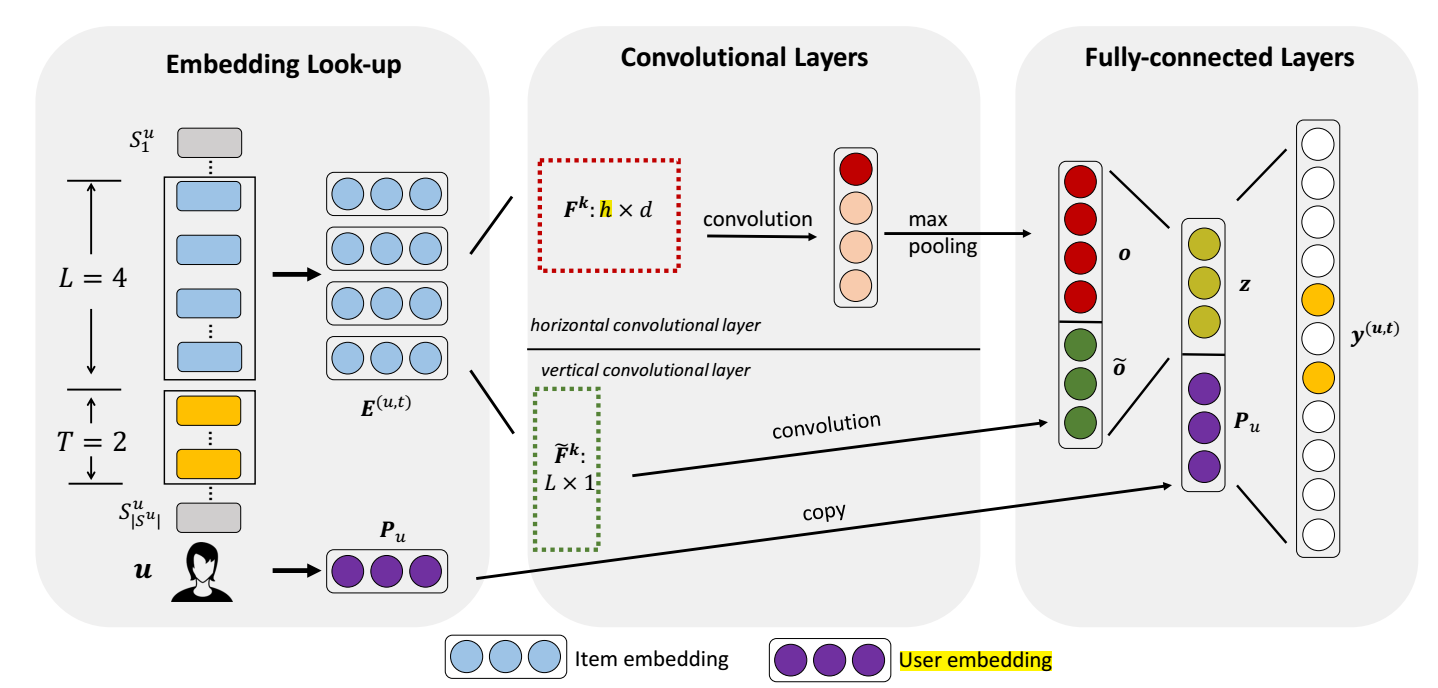
-
固定 sequence 的长度 \(|\mathcal{S}^u| = L\);
-
获取序列 items 的 embeddings: \(\mathbf{E}^{(u, t)} \in \mathbb{R}^{L \times d}\).
-
对于 user \(u\) 获取它的 embedding \(\mathbf{P}_u \in \mathbb{R}^d\).
-
Horizontal Convolutional Layer:
- 有 \(L\) 个水平卷积 \(\mathbf{F}^k \in \mathbb{R}^{h \times d}, h \in \{1, \cdots, L\}, 1 \le k \le n\), 每个水平卷积的
stride=1. 这相当于out_channels=n,kernel_size=(h, d)的卷积. - 于是乎, 每个卷积核卷积后的大小为 \((L-h+1, d)\), 于是每个卷积可以得到:\[\mathbf{c}^k = [\mathbf{c}_1^k \mathbf{c}_2^k \cdots \mathbf{c}_{L-h+1}^k]. \]
- 对每个进行 max pooling 得到\[\mathbf{o} = \{\max(\mathbf{c}^1), \max(\mathbf{c}^2), \cdots, \max(\mathbf{c}^n)\}. \]
- 有 \(L\) 个水平卷积 \(\mathbf{F}^k \in \mathbb{R}^{h \times d}, h \in \{1, \cdots, L\}, 1 \le k \le n\), 每个水平卷积的
-
Vertical Convolutional Layer:
- 垂直的卷积, 即卷积为 \(\tilde{\mathbf{F}}^k \in \mathbb{R}^{L \times 1}, 1\le k \le \tilde{n}\).
- 每个卷积卷积后的大小为 \((1, d)\):\[\tilde{\mathbf{c}}^k = [\tilde{\mathbf{c}}_1^k \tilde{\mathbf{c}}_2^k \cdots \tilde{\mathbf{c}}_d^k]. \]
- 最后得到:\[\tilde{\mathbf{o}} = [\tilde{\mathbf{c}}^1 \tilde{\mathbf{c}}^2 \cdots \tilde{\mathbf{c}}^{\tilde{n}}]. \]
-
最后的序列特征通过 MLP 转换得到:
\[\mathbf{z} = \phi_a (\mathbf{W} \left [ \begin{array}{c} \mathbf{o} \\ \tilde{\mathbf{o}} \end{array} \right] + \mathbf{b} ). \] -
最后的预测需要结合 user 的 embedding 表示:
\[\mathbf{y}^{(u, t)} = \mathbf{W}' \left [ \begin{array}{c} \mathbf{z} \\ \mathbf{P}_u \end{array} \right ] + \mathbf{b}'. \]

