Stochastic Training of Graph Convolutional Networks with Variance Reduction
概
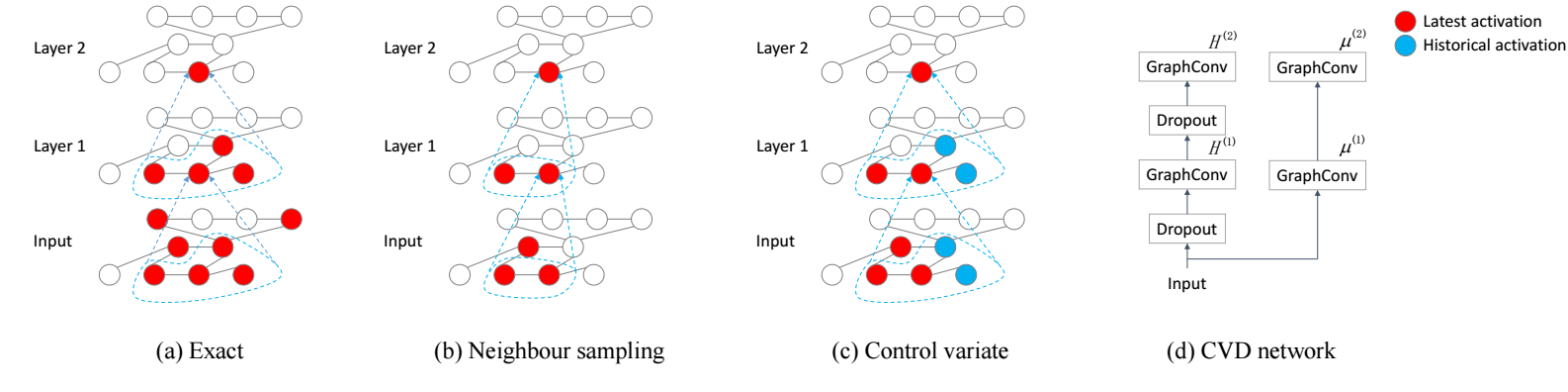
我们都知道, GCN 虽然形式简单, 但是对于结点个数非常多的情形是不易操作的: 多层的卷积之后基本上每个结点的感受野都会变得非常大 (指数级上升), 这对导致 mini-batch 训练的思想在图的任务中是不那么普遍的. GraphSage 通过采样结点的方式缓解了这个问题, 但是不想以往的 mini-batch 那样有很好的收敛性保证. 本文主要解决的就是这两个问题.
符号说明
- \(\mathcal{G} = (\mathcal{V}, \mathcal{E})\), 图;
- \(V = |\mathcal{V}|, E = |\mathcal{E}|\);
- \(A\), 邻接矩阵;
- \(\tilde{A} = A + I\);
- \(P = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2}\);
- graph convolution layer:\[Z^{(l+1)} = P H^{(l)} W^{(l)}, \\ H^{(l+1)} = \sigma(Z^{l+1}). \]
Motivation
-
我们首先将任务场景限定在 node-level 的问题上, 假设训练集 \(\mathcal{V}_l \subset \mathcal{V}\), 我们希望根据这些结点以及他们的标签为其余的结点 \(\mathcal{V} \setminus \mathcal{V}_l\) 打标签;
-
假设我们通过如下损失进行训练:
\[\mathcal{L} = \frac{1}{\mathcal{V}_l} \sum_{v \in \mathcal{V}_l} f(y_v, z_v^{(L)}), \]则每次训练都要计算如下的梯度:
\[\nabla \mathcal{L} = \frac{1}{\mathcal{V}_l} \sum_{v \in \mathcal{V}_l} \nabla f (y_v, z_v^{(L)}), \]作者认为这一步的计算是非常大的.
-
一些方法, 比如 GraphSage 采用采样邻居的方式来模拟 mini-batch 的训练方式, 它相当于:
- 采样部分结点;
- 利用这些结点构建新的邻接矩阵 \(\hat{P}\);
- 然后通过如下方式进行更新:\[Z^{(l+1)} = \hat{P}^{(l)} H^{(l)} W^{(l)}, \\ H^{(l+1)} = \sigma(Z^{(l+1)}), \]这就大大减轻了计算.
-
但是这种方式, 由于非线性 \(\sigma\) 的存在, 无法保证 \(\hat{P}\) 会收敛到 \(\hat{P}\), 也因此整体的训练方式也缺乏严格的收敛保证.
本文方法
-
作者维护历史变量 \(\bar{H}^{(l)}\), 然后通过如下方式更新:
\[Z^{(l+1)} = (\hat{P}^{(l)}(H^{(l)} - \bar{H}^{l}) + P\bar{H}^{(l)}) W, \]由于 \(\bar{H}^{(l)}\) 本身是不带梯度的, 所以在反向计算梯度的时候:
\[\begin{array}{ll} \mathrm{d} Z^{(l+1)} &= \mathrm{d} (\hat{P}^{(l)}(H^{(l)} - \bar{H}^{l}) + P\bar{H}^{(l)}) W \\ &= (\hat{P}^{(l)} \mathrm{d} H^{(l)}) W \\ & \quad + (\hat{P}^{(l)}(H^{(l)} - \bar{H}^{l}) + P\bar{H}^{(l)}) \mathrm{d} W, \end{array} \] -
说实话, 从训练的方式来看, 并没有减少计算量的感觉. 不过, 因为这种方式更加稳定, 所以方差比较小, 因此只需要为每个结点采样 2 个邻居就可以了, 这应该是计算量降低的主要原因.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号