DiffuRec: A Diffusion Model for Sequential Recommendation
概
扩散模型用于序列推荐, 性能提升很大.
DiffuRec
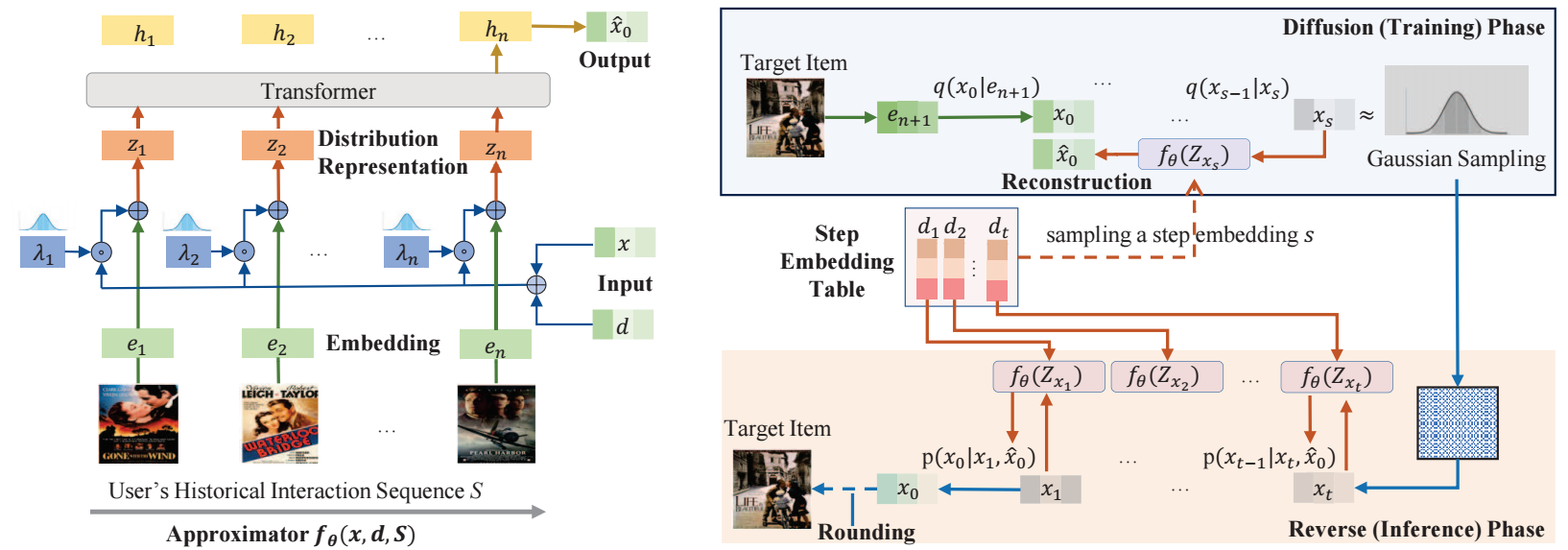
前向
- 前向和普通的扩散模型没有什么区别, 即不过采用的是 truncated linear schedule.
后向
- 后向是直接一步一步回来的, 并没有用 DDIM 加速, 所以 DiffuRec 的 timesteps 设的很小 .
近似模型
-
与一般的扩散模型比较大的区别是模型的设置.
-
首先, 为每个 item 赋予一个 embedding , 序列中扩散的任务是需要通过模型来拟合条件分布:
其中 表示用户的历史交互的 items.
-
作者的近似模型为:
即这是一个直接预测 的模型. 在反向采样的过程中, 我们需要推断 , 这可以通过一定的变换得到.
-
在这里 实际上控制了 '噪声' 的权重, 如果 那 DiffuRec 就成了普通的序列推荐模型, 在这里 . 实验中发现, 需要足够小:
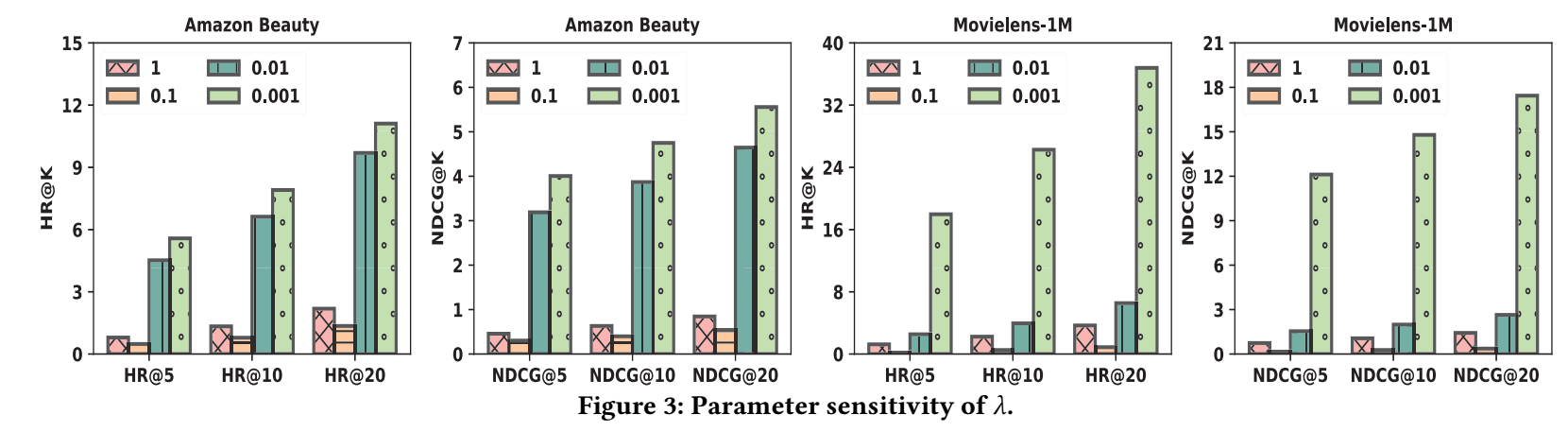
-
这是第一个让我感觉到有点奇怪的点.
-
此外, 不同于一般的扩散模型, 采用 MSE, 作者采用的是交叉熵
-
这也是十分奇怪的一点, 因为这相当于完全破坏了 ELBO 的性质, 不是很理解.
-
最后, 采样得到的 , 还需要通过 rounding 映射回到离散的空间中去:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2020-04-13 Differential Evolution: A Survey of the State-of-the-Art