Sequential Recommendation via Stochastic Self-Attention
概
Stochastic embeddings 和 Wasserstein attention.
符号说明
- \(\mathcal{U}\), users;
- \(\mathcal{V}\), items;
- \(\mathcal{S}^u = [v_1^u, v_2^u, \ldots, v_{|\mathcal{S}|^u}^u]\), sequence;
- \(p(v_{|\mathcal{S}^u| + 1}^{(u)} = v | \mathcal{S}^u)\), next-item 预测概率.
Motivation
-
一般的序列推荐模型采用'固定'的 embedding 表示 \(\mathbf{M} \in \mathbb{R}^{|\mathcal{V}| \times d}\), 但是这种方式不能很好地表示用户兴趣或者产品特征的不确定度.
-
此外, 一般的 Attention 一般如下形式:
\[\text{SA}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d}}) \mathbf{V}. \]但是作者认为, 这种 '内积' 不是并不是合格的距离度量 (不满足三角不等式), 所以难以正确度量序列的先后关系.
STOSA
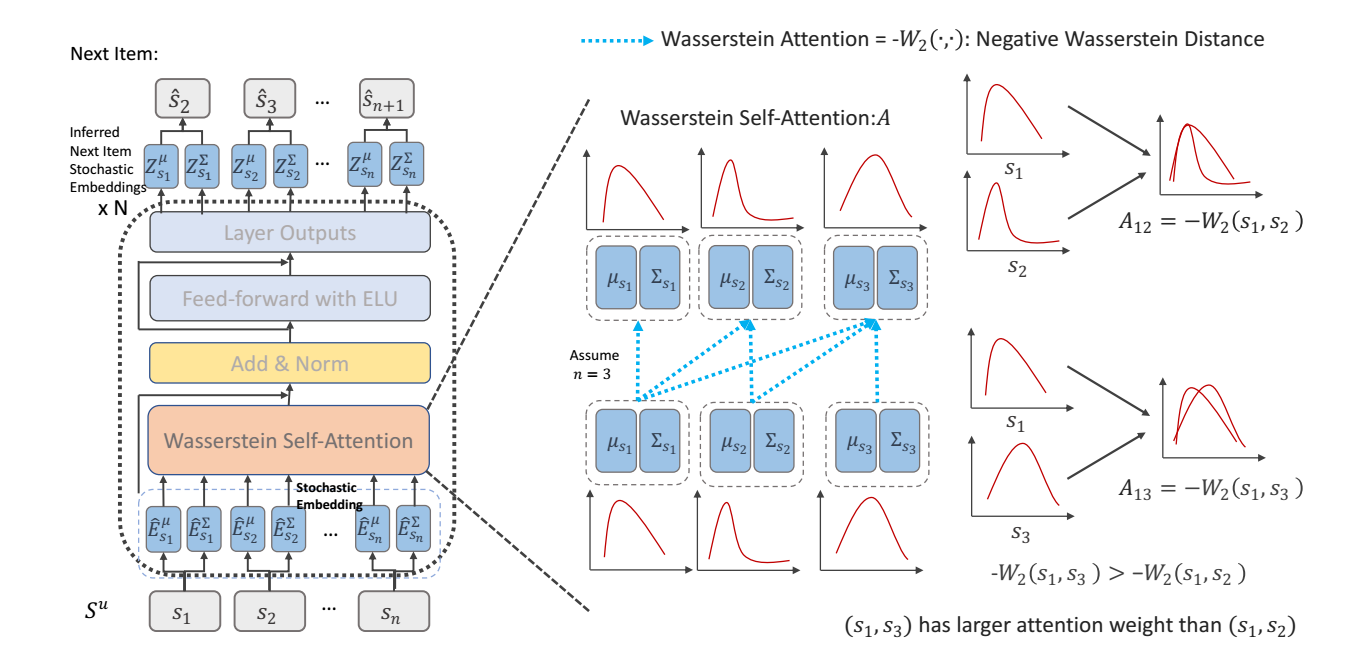
-
为了度量结点的不确定性, 作者将每个结点建模成一个高斯分布:
\[\mathcal{N}(\bm{\mu}_v, \Sigma_{v}). \] -
具体的, 我们构建两个 embedding table: \(\mathbf{M}^{\mu} \in \mathbb{R}^{|\mathcal{V}| \times d}, \mathbf{M}^{\Sigma} \in \mathbb{R}^{|\mathcal{V}| \times d}\), 故 (这里我们省略位置编码)
\[\bm{\mu}_v = \bm{m}_v^{\mu}, \: \Sigma_v = \text{diag}(\mathbf{m}_v^{\Sigma}). \] -
可以这么认为, \(\bm{\mu}_v\) 是结点 \(v\) 的基本表示, \(\Sigma_v\) 融合了结点 \(v\) 的一个不确定度.
-
为了替换一般的基于内积的 attention, 作者采用 Wasserstein attention:
- 给定两个结点, 假设它们的分布分别为 \(\mathcal{N}(\bm{\mu}_u, \Sigma_u), \mathcal{N}_v(\bm{\mu}_v, \Sigma_v)\), 则二者的 (unnormalized) attention 为:
\[\mathbf{A}_{uv} = -W_2(u, v) = -(\|\bm{\mu}_u - \bm{\mu}_v\|_2^2 + \text{tr}(\Sigma_u + \Sigma_v - 2(\Sigma_u^{1/2}\Sigma_{v}\Sigma_{u}^{1/2})^{1/2})). \] -
需要注意的是, 在 feed-forward 的过程中, 每个结点的分布在改变, 此时, 为了保证 \(\Sigma\) 有意义 (即满足半正定性), 每次需要对特征进行后处理:
\[\text{ELU}(\cdot) + 1 \in [0, +\infty]. \] -
因为不像 SASRec, STOSA 每次返回的是 \(\hat{\bm{\mu}}, \hat{\Sigma}\), 相当于是一个分布, 所以计算 score 的时候, 需要再计算它和其它结点的负Wasserstein 距离.
代码
[official]

