Divide and Conquer: Towards Better Embedding-based Retrieval for Recommender Systems From a Multi-task Perspective
概
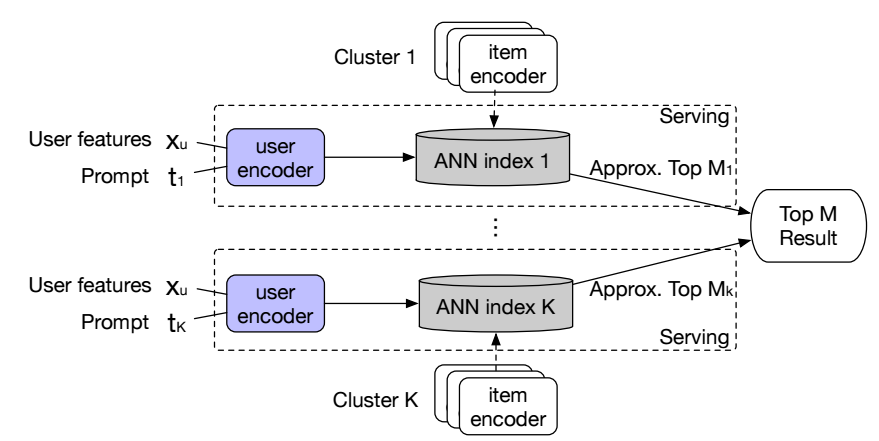
获得了表示之后, 最常见的做法是通过 ANN (Approximate Nearest Neighbor) 方法来找到最相似的一组表示用于推荐. 这种方式导致训练的低效和推理的不可控, 本文将 items 按照语义进行划分, 得到不同的 clusters, 然后每一类进行匹配.
符号说明
- \(\mathcal{U}\), user;
- \(\mathcal{I}\), item;
- \(\bm{e}_u, \bm{e}_i\), embeddings;
本文方法
-
一般来说, 我们根据 user, item 的历史交互和特征得到特征表示, 比如 SASRec:
\[\bm{e}_u = f(\bm{x}_u) = \text{Transformer}([\bm{s}_1^u, \bm{s}_2^2, \ldots, \bm{s}_n^u]), \]这里 \(\bm{s}_i^u\) 表示用户历史交互的 item 的 embeddings.
-
对于 \(\bm{e}_u\), 我们通常计算它和其它的 items 的内积然后筛选出得分最高的一批作为候选的推荐. 然而这种在全部 items 上训练和筛选的方式存在一下问题:
- 训练的时候, 我们通常需要采样负样本, 然后由于 items 过多, 采样出和 positive 相关的负样本是困难的;
- 推断的时候, 采用 ANN 的近似方式难以获得具有多样性的推荐结果, 整体的推荐是不可控的.
-
于是本文希望首先根据语义 (Word2Vec + K-means) 进行聚类得到:
\[\mathcal{I} = \{C_1, C_2, \ldots, C_K\}. \]然后采用如下损失进行学习:
\[\mathcal{L} = -\sum_{k=1}^K \sum_{u \in \mathcal{U}} \sum_{i^+ \in \mathcal{I}^u \cap C_k} \Big[ \log (\sigma(r_{ui^+})) + \mathbb{E}_{i^- \sim C_k \setminus \mathcal{I}^u}[\log (1 - \sigma(r_{ui^-}))] \Big]. \]这里 \(r_{ui}\) 表示 user, item 的内积.
-
显然:
- 同一个类内语义相似, 故而正样本和负样本的之间联系更加紧密;
- 此类方法可以增加多样性: 我们可以每个类选择中选择部分推荐 items, 然后综合起来. (每个类选择多少可以根据用户的特征学习).
-
此外, 为了适应不同的类, 作者采用类似 Prompt 的方式对模型进行改进:
\[\bm{e}_u = f(\bm{x}_u) = \text{Transformer}([\bm{s}_1^u \odot \bm{t}_k, \bm{s}_2^2 \odot \bm{t}_k, \ldots, \bm{s}_n^u] \odot \bm{t}_k), \]这里 \(\bm{t}_k\) 是第 k 个类的 embedding, \(\odot\) 表示哈达玛积.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号