Difformer: Empowering Diffusion Models on the Embedding Space for Text Generation
概
本文发现并改进了原先 Diffusion 模型的缺点 (针对文本生成任务).
符号说明
- \(\bm{x} = [x_1, x_2, \cdots, x_m]\), source sentence;
- \(\bm{y} = [y_1, y_2, \cdots, y_n]\), target sentence;
- 前向过程:\[q(\bm{z}_t|\bm{z}_{t-1}) = \mathcal{N}(\bm{z}_t; \sqrt{1 - \beta_t} \bm{z}_{t-1}, \beta_t \bm{I}), \\ \bm{z}_0 \sim \mathcal{N}(\bm{e(y)}; \beta_0 \bm{I}). \]其中 \(\bm{e}(\cdot)\) 将离散的 token \(y\) 映射到 embedding 空间.
- 反向过程:\[p_{\theta}(\bm{z}_{t-1}|\bm{z}_t) = \mathcal{N}(\bm{z}_{t-1}; \bm{\mu}_{\theta}(\bm{z}_t, t), \bm{\Sigma}_{\theta}(\bm{z}_t, t)). \]一般, 方差和前向保持一致, 然后我们实际上拟合的是\[\hat{\bm{z}}_0 = f_{\theta}(\bm{z}_t, t). \]
主要内容

-
Diffusion 在文本生成之上的应用大抵为优化如下的损失:
\[\underbrace{\mathbb{E}_{\bm{z}_0, t} [\|\hat{\bm{z}}_0 - \bm{z}_0\|^2]}_{\mathcal{L}_{vlb}} + \underbrace{(- \mathbb{E}_{\bm{z}_0, \bm{y}} \log p_{\theta}(\bm{y}|\bm{z}_0))}_{\mathcal{L}_{round}}. \]前者是普通的 diffusion 损失, 后者是用于离散到连续的对齐.
-
问题1: 可学习的 embeddings: 和 image, video 不同的是, embedding 是可学习的, 这可能导致训练的不稳定.
-
解决办法1: 如上图所示, 我们用不同时刻 t 的预测 \(\hat{\bm{z}}_0\) 来靠近 \(\bm{y}\), 即
\[\mathcal{L}_{anchor} = -\log p_{\theta}(\bm{y}|\hat{\bm{z}}_0) \]来替代 \(\mathcal{L}_{round}\).
-
问题2: embedding 的 norm 不一致: 由于词频不一致, 作者发现训练过程中高频词的 norm 会普遍大一点. 此时加入相同量级的噪声对于信号的干扰程度就不一致了:
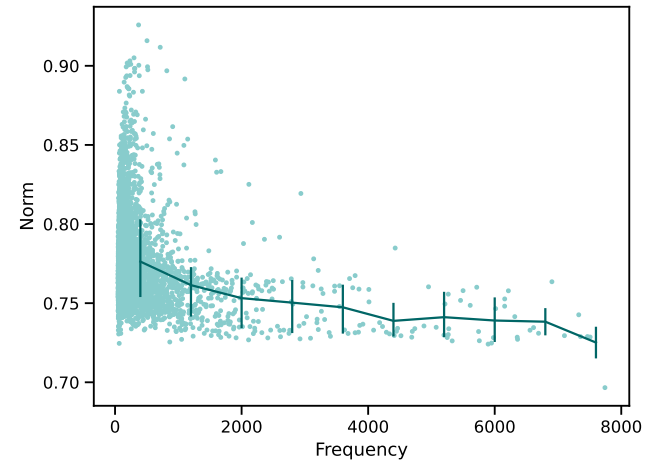
-
解决办法2: 故作者在 embedding 之后加了一个 embedding normalization 层 (不过看起来对实际效果的提升不是特别大):
\[\text{LN}(\bm{e}(y_i)) = \frac{\bm{e}(y_i) - \mathbb{E}[\bm{e}(y_i)]}{\sqrt{\mathbb{V}[\bm{e}(y_i)] + \epsilon}} \odot \bm{\gamma} + \bm{\eta}. \] -
问题3: noise schedule 导致扩散过程的大部分阶段都是'无意义'的: 作者发现, 对于一般的前向过程和 noise schedule 而言, 整个过程的大部分时间的干扰效果都是很差的, 此时很难充分训练 (特别是对于 sqrt 这种 schedule):
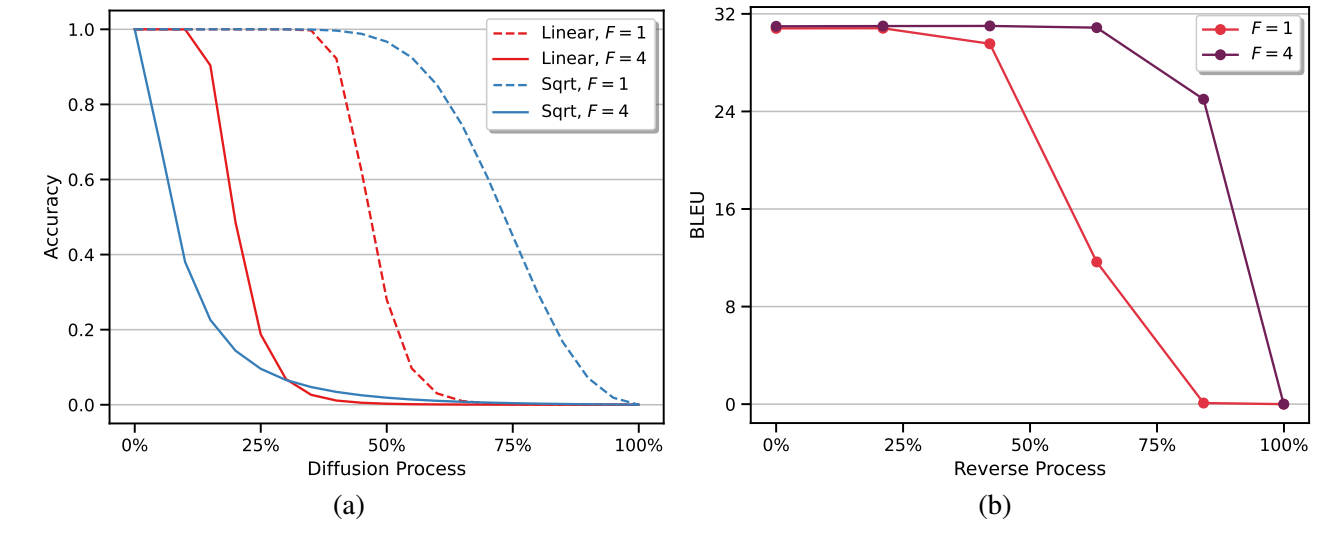
-
解决办法3: 作者对整体的扰动的方差进行一个扩张:
\[q(\bm{z}_t|\bm{z}_{t-1}) = \mathcal{N}(\bm{z}_t; \sqrt{1 - \beta_t} \bm{z}_{t-1}, \beta_t F^2 \bm{I}). \]一般的扩散 \(F=1\), 作者发现 \(F=4\) 会产生相当不错的结果.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号