A Survey of Diversification Techniques in Search and Recommendation
概
本文对聚焦 diversity 的方法进行了一个回顾和总结. 这里主要记录一下评价多样性的指标.
符号说明
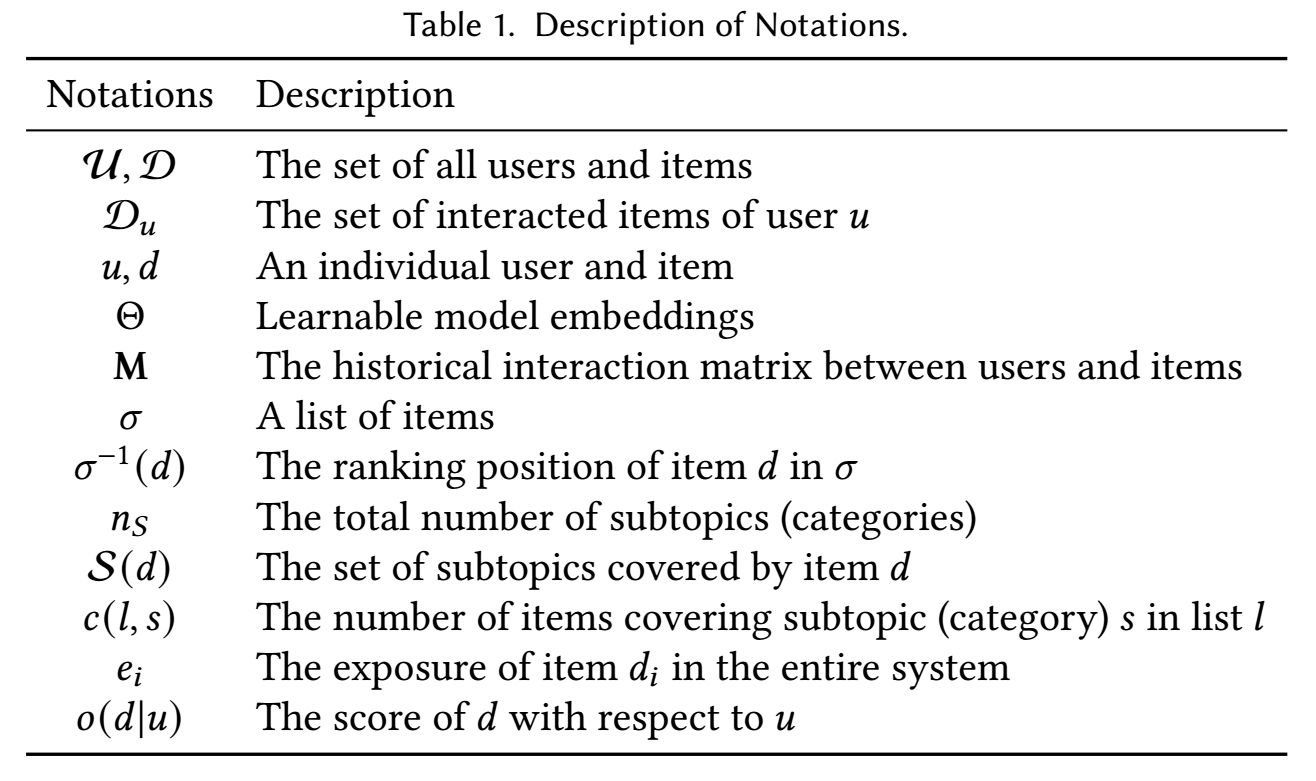
Diversity Metrics

Relevance-oblivious Diversity Metrics
Distance-based Metrics
-
ILAD ↑↑ (Intra-List Average Distance):
ILAD=meandi,dj∈σ,i≠jdisij.ILAD=meandi,dj∈σ,i≠jdisij.其中 disijdisij 表示 didi, djdj 间的距离.
-
ILMD ↑↑ (Intra-List Minimal Distance):
ILAD=mindi,dj∈σ,i≠jdisij.ILAD=mindi,dj∈σ,i≠jdisij.
通过引入长度为 ww 的滑动窗口可以将这些概念推广到 (local) 的概念:
-
ILALD ↑↑ (Intra-List Average Local Distance):
ILAD=meandi,dj∈σ,i≠j|rank(di|σ)−rank(dj|σ)|≤wdisij.其中 disij 表示 di, dj 间的距离.
-
ILMD ↑ (Intra-List Minimal Local Distance):
ILAD=mindi,dj∈σ,i≠j|rank(di|σ)−rank(dj|σ)|≤wdisij.
我们有如下几种方式来具体的定义 disij:
-
Cosine Diversity Distance. 假设我们拥有 item embeddings, 可以定义
disij:=1−cos⟨di,dj⟩. -
Jaccard Diversity Distance. 我们也可以通过如下方式来定义:
disij:=JDD(di,dj|u)=1−|Expl(u,di)∩Expl(u,dj)||Expl(u,di)∪Expl(u,dj)|,其中 (content-based strategy)
Expl(u,d)={d′∈D|sim(d,d′)>0 and d′∈Du},或 (collaborative filtering)
Expl(u,d)={u′∈U|sim(u,u′)>0 and d∈Du′}. -
Gower Diversity Distance. 还可以定义为
disi,j:=GDD(di,dj)=∑kwk⋅δk,其中 δk 为两个 items 在 k-th 的属性差异, 而 wk 是对应位置的权重 (感觉好复杂啊).
Converage-based Metrics
首先介绍 Rank-unaware 的方法, 这些大体是刻画推荐系统整体的多样性指标, 感觉目前我还用不到这些.
-
P-Coverage ↑ (Prediction Coverage):
P-Converage=|Dp||D|,其中 Dp 表示推荐的 (满足感兴趣条件的) items 的集合. 通常用来刻画推荐系统整体的多样性.
-
C-Converage ↑ (Catalog Coverage):
C-Coverage=|⋃Ni=1σi||D|.刻画了所有推荐的 items 在整体的一个覆盖率. 同样是刻画系统整体的多样性.
-
S-Coverage ↑ (Subtopic-Coverage):
S-Coverage=|⋃Ni=1(∪d∈σiS(d))|nS,这里 S(d) 表示 item d 所涵盖的 topic (或类别, 群体 ...), nS:=|⋃d∈DS(d)|.
接下来再介绍一些 Rank-aware 的尺度, 这些指标大抵是作用在一个推荐的 list 上, 需要注意的是, 这里的 Rank-aware 只是这些指标在不同的 Top-K 的推荐下会有不同的结果, 并非表示对于不同的 position 会有不同的权重.
-
S-RR@100% (Subtopic-Reciprocal Rank@100%):
S-RR@100\%=mink(|k⋃i=1S(di)|=nS.)反应了为了覆盖所有的 topics 所需要推荐的 items 数.
-
S-Recall@K ↑ (Subtopic-Recall@K):
S-Recall@K=|∪ki=1S(di)|nS.反映了 Top-K 的推荐的覆盖率.
-
S-Precision@K ↑ (Subtopic-Precision@K):
S-Precision@K=|∪ki=1S(di)|k.
最后介绍 Social Welfare Metrics, 这些指标大抵是从一些别的领域 (经济等) 引用过来的, 个人感觉还是挺有意思的.
-
SD Index ↓ (Simpson’s Diversity Index):
SD Index=∑nSi=1[c(l,si)⋅(c(l,si)−1)]|l|(|l|−1),其中 c(l,si) 表示 l 中包含 subtopic (或类别, 种类, 群体) si 的数目. 在每个 item 仅包含一个 subtopic 的情况下, 显然推荐的 items 不包含重复的 subtopics 时 SD Index 最小 (为 0).
-
Gini Index ↓.
Gini Index=12|D|2ˉe|D|∑i=1|D|∑j=1|ei−ej|.其中 ei 表示 di 是否被推荐 ? ˉe=1|D|∑|D|i=1ei. 需要注意的是, Gini Index 是一个整体性的指标.
Relevance-aware Diversity Metrics
注: 虽然标题写着 relevance-aware, 但是所包括的指标中有些并没有把 relevance 考虑进来, 只是这些指标对于不同的 position 施加了不同的权重而已. 我不知道是否是我的理解有所差异.
Novelty-based Metrics
Novelty-based 的指标更关注我们推荐的 list 避免重复性.
-
α-nDCG@K (Novelty-biased Normalized Discounted Cumulative Gain@K):
Gain(dk)=nS∑i=1I[si∈dk](1−α)c(k,si),α-DCG@K=K∑k=11log(k+1)⋅Gain(dk).其中 c(k,si)=∑k−1j=1I[si∈dj],c(0,si)=0. 进一步地, 我们可以计算 α−iDCG@K, 从而计算 α-nDCG@K. 不过 α−iDCG@K 是 NP-Complete 问题.
o -
NRBP (Novelty- and Rank-Biased Precision):
NRBP=1−(1−α)βnS|σ|∑k=1βk−1nS∑i=1r(dk|si)(1−α)c(k,si).其中 β 是认为给定的超参数, 它衡量了在浏览了当前 item 会继续浏览下一个 item 的概率. 所以 NRBP 实际上是一个期望收益.
-
nDCU@K (Normalized Discounted Cumulative Utility@K):
DCU@K=K∑k=11log(k+1)⋅Utility(dk),其中
Utility(dk)=Gain(dk)−Loss(dk).
Intent-aware Metrics
- 有些时候, 不同的 topic 的重要性是不同的, 但是上面的指标基本上是同等看待, 所以在有些时候是不妥的. 故 Intent-aware Metrics 此时就有了必要, 比如:M-IA(σ)=nS∑i=1p(si|q)⋅M(σ|si).其中 q 表示某个 query, M 可以是一些传统的指标, 比如: nDCG, MRR, MAP 等 (注意 |si 条件下, 不包含 si topic 的 items 应当看成是无关的 item).



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· SQL Server 2025 AI相关能力初探
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
2022-03-25 Improving the Learning Speed of 2-Layer Neural Networks by Choosing Initial Values of the Adaptive Weights
2021-03-25 Chapter 20 Treatment-Confounder Feedback